
1. Core Conclusion: ChatGPT 5.5 Is Execution-Oriented, Claude Opus 4.7 Is Stability-Oriented
If you only look at the conclusion, the difference between ChatGPT 5.5 and Claude Opus 4.7 can be summed up in one sentence: ChatGPT 5.5 is better suited for complex task execution and agentified workflows; Claude Opus 4.7 is better suited for long documents, enterprise security, compliance review, and stable outputs.
ChatGPT 5.5's strengths include stronger task decomposition, more proactive tool invocation, and a better fit for engineering development, data analysis, research tasks, and multi-step business processes. Its product direction is no longer just "answering questions" but is closer to "completing tasks."
Claude Opus 4.7's strengths are stability, caution, and suitability for long-context tasks and enterprise-scale complex workflows. It performs particularly well in document understanding, code review, risk control, compliance phrasing, and security boundaries.
One-sentence judgment: If you need AI to "do work," prioritize ChatGPT 5.5; if you need AI to "review, verify, and deliver stable outputs," Claude Opus 4.7 is more appropriate.
2. Basic Positioning Comparison
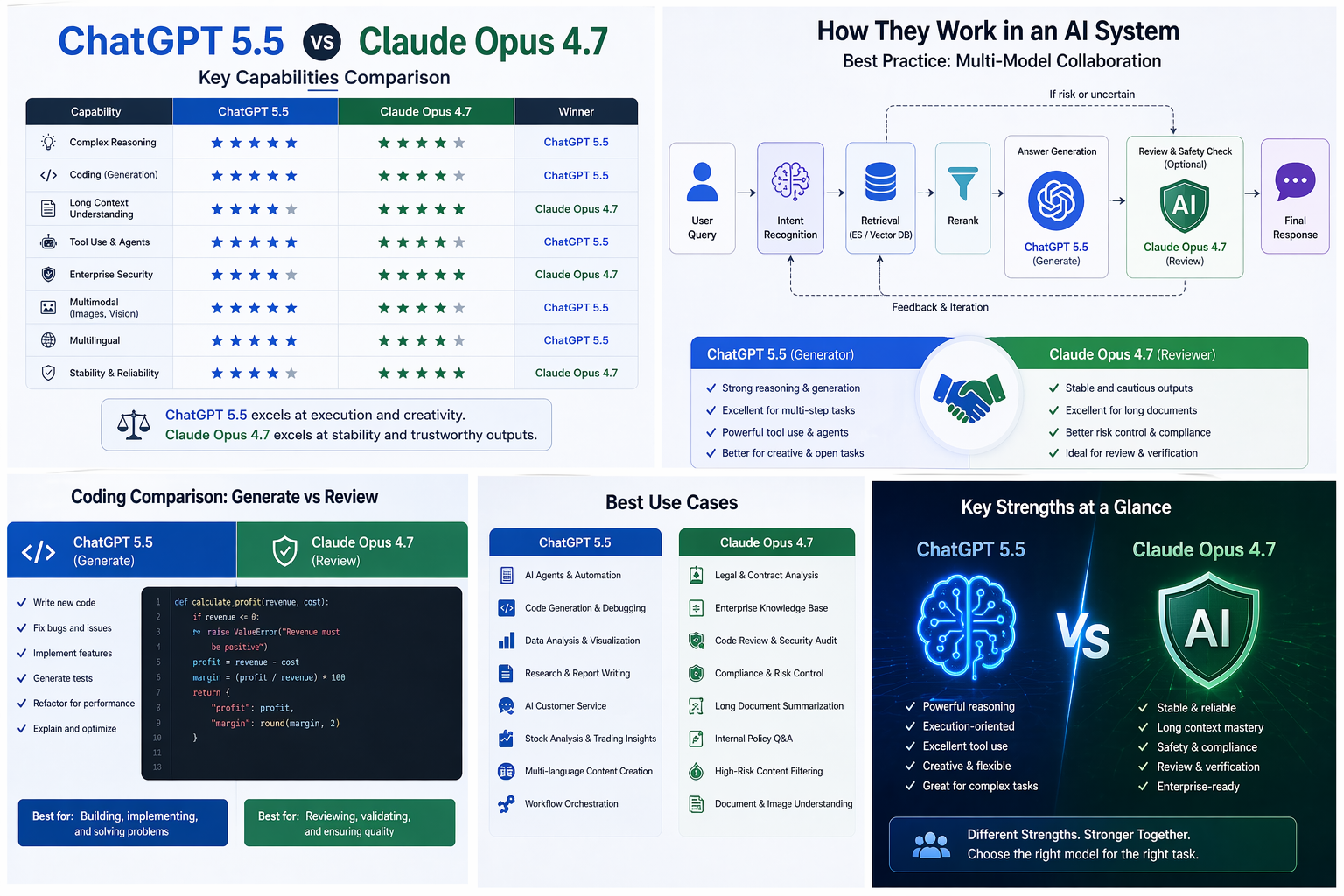
Dimension ChatGPT 5.5 Claude Opus 4.7 Company OpenAI Anthropic Core positioning Complex task execution, coding, research, data analysis, agent workflows Enterprise workflows, long context, code, visual understanding, security protection Model style Proactive, aggressive, execution-focused Stable, cautious, strong review capabilities Suitable users Developers, data analysts, product managers, researchers, agent application builders Enterprise users, legal, compliance, knowledge-base teams, code review teams Main strengths Multi-step reasoning, tool invocation, code generation, task completion Long-text understanding, stable output, security boundaries, document handling Main weaknesses Needs constraints to control hallucinations and overreach in open tasks Sometimes overly conservative and less proactive on ambiguous tasks than ChatGPT
3. Overview of Model Capabilities
Capability Dimension ChatGPT 5.5 Claude Opus 4.7 Conclusion Complex reasoning Very strong, suitable for multi-step tasks Strong, outputs are more cautious ChatGPT 5.5 is better for proactive reasoning Code generation Strong, good at writing code, fixing bugs, and generating solutions Strong, good at reviewing, refactoring and standardization Use ChatGPT for generation, Claude for review Long-document understanding Strong Very strong Claude is more stable Multi-tool invocation Very strong Strong but more cautious ChatGPT is better for agenting Enterprise security Strong Very strong Claude is better for high-risk scenarios Multilingual ability Very strong Strong ChatGPT is better for global content Visual understanding Strong Significantly improved, supports higher-resolution images Both are strong; Claude 4.7 shows notable progress Commercial deployment Suitable for productization, automation, and agent systems Suitable for enterprise processes, compliance, and document workflows Depends on business scenario
4. ChatGPT 5.5 Core Strengths: From "Chat Model" to "Task Execution Model"
The biggest change in ChatGPT 5.5 is not just more natural answers, but a much better fit for complex task execution. OpenAI’s official description of GPT-5.5 emphasizes coding, research, data analysis, document-intensive tasks, and plugin/tool usage. This indicates a clear direction: ChatGPT 5.5 is no longer just a language model but an intelligent execution system for complex work.
This kind of capability is critical for real business. Earlier large models were more like "knowledge Q&A assistants"—they answered whatever the user asked. In real business scenarios, users often need an AI that can decompose tasks, call tools, analyze results, correct errors, and ultimately deliver actionable outputs.
For example, in software development, users don't just want the model to explain a code snippet; they want it to understand the project structure, locate problems, modify code, generate tests, and even assess deployment risks. In data analysis, users want the model to read data, detect anomalies, generate charts, explain trends, and propose next-step strategies—not just provide statistical conclusions.
ChatGPT 5.5 shines in these complex chains. It's better at breaking a big problem into smaller steps and executing them sequentially. This makes it especially suitable for:
Code generation and bug fixing
Complex system architecture design
Data analysis and report generation
Multi-agent collaboration systems
AI customer service workflows
Stock analysis and automated research report generation
Enterprise automation
RAG knowledge-base Q&A
5. Claude Opus 4.7 Core Strengths: Stability, Safety, Long Context, and Enterprise Workflows
Claude Opus 4.7’s upgrade path differs from ChatGPT 5.5. Anthropic has long emphasized safety, controllability, and enterprise-grade stability. Claude Opus 4.7 improves in complex tasks, code, and visual understanding, while also strengthening detection and blocking for high-risk cybersecurity uses.
This shows Claude’s core approach is not purely about unleashing more aggressive capabilities, but about improving ability while maintaining strong boundaries. For enterprise customers this is crucial. Enterprises usually care less about how "smart" a model is and more about whether it is stable, unlikely to fabricate, compliant, and able to reliably handle long documents and complex workflows.
Claude Opus 4.7 is especially suited for:
Legal contract analysis
Enterprise policy Q&A
Long-document summarization
Code review
Compliance review
High-risk content filtering
Enterprise knowledge-base Q&A
Multi-page document, screenshot, and table understanding
Claude Opus 4.7 also enhances high-resolution image input capabilities, which is valuable for document screenshots, system UIs, table images, and flowchart understanding. Many enterprise data are not plain text but embedded in PDFs, screenshots, spreadsheets, presentations, and system pages. Improved visual understanding significantly increases Claude’s applicability in enterprise workflows.
6. Coding Capabilities Comparison: ChatGPT 5.5 Better for Writing, Claude Opus 4.7 Better for Reviewing
Coding is one of the most important battlegrounds in the current large-model competition because code tasks directly translate to productivity and are easy for enterprises to perceive value from.
Code tasks ChatGPT 5.5 Claude Opus 4.7 New code generation More proactive, stronger landing/implementation Strong in norms and clear structure Bug fixing Good at locating, modifying, and explaining Good at finding edge cases and potential risks Large project understanding Strong, especially when combined with tools Strong, well suited for long-context review Code refactoring Engineering-oriented Oriented toward maintainability and safety Test case generation Broad coverage, execution-oriented Strong boundary awareness Code review Usable Better suited for review
If you are an engineer, you can divide responsibilities like this in practice:
ChatGPT 5.5: responsible for solution design, code generation, bug fixes, scripting, API integration, and data analysis.
Claude Opus 4.7: responsible for code review, risk checks, boundary conditions, documentation summarization, and compliance phrasing.
This is also an important future trend for enterprises using large models: don't rely on a single model but let different models play different roles. ChatGPT 5.5 is more like the developer; Claude Opus 4.7 is more like the reviewer.
7. Agent Capabilities Comparison: ChatGPT 5.5 Is Better for Execution Agents
Agent capability is a core metric for judging the value of the next-generation large models. An agent is not simple Q&A; it's a model that can autonomously decompose goals, call tools, execute steps, handle exceptions, and ultimately complete tasks.
Agent capability ChatGPT 5.5 Claude Opus 4.7 Task decomposition Very strong Strong Tool invocation Very strong, suitable for multi-tool chains Strong, but more cautious Error correction Highly proactive Stable Long-duration tasks Suitable for execution Suitable for supervision and review Complex business flows Better as the main controller Suitable as a verification model
From a product perspective, ChatGPT 5.5 is better suited to be the "brain" in agent systems, responsible for planning and execution; Claude Opus 4.7 is better as a "checker," responsible for judging whether results are reasonable, out-of-bounds, or risky.

8. RAG and Knowledge-Base Scenarios
In RAG and knowledge-base scenarios, the model's role is not to answer independently but to generate accurate, credible, and controllable answers based on retrieved content. A good model needs to have these abilities:
Understand the user's true intent
Answer based on retrieved knowledge
Recognize when knowledge is insufficient
Not fabricate arbitrarily
Handle multi-turn context
Call business tools like order, product, after-sales, and logistics systems
RAG capabilities ChatGPT 5.5 Claude Opus 4.7 Answering based on knowledge Strong Strong and more cautious Multi-turn dialogue Stronger Stable but more conservative Hallucination control Needs prompt and rule constraints Naturally more cautious Tool invocation Stronger Strong Customer service scenarios Better as the primary model Suitable as an audit or fallback model Enterprise document Q&A Strong More stable
If it's an AI customer-service scenario, a recommended architecture is:
User question
↓
Intent recognition
↓
ES / vector store retrieval
↓
Rerank
↓
ChatGPT 5.5 generates answer
↓
Claude Opus 4.7 optional review
↓
Return to userThe benefit of this architecture is that ChatGPT 5.5 generates more natural, flexible, and execution-effective answers; Claude Opus 4.7 checks whether responses exceed knowledge boundaries, make risky commitments, or over-answer.
9. Enterprise Knowledge-Base Scenarios: Claude Is More Stable, ChatGPT Handles Complex Tasks Better
Enterprise knowledge bases differ from ordinary chat. They require models to strictly answer based on internal documents, avoid improvisation, and not draw unverified conclusions. In this scenario, Claude Opus 4.7's stability is highly valuable.
However, enterprise knowledge bases are not just simple Q&A. Increasingly, enterprises want knowledge bases that can execute complex workflows, for example:
Read multiple documents and generate comparison reports
Determine whether a process is compliant based on policies
Automatically call system APIs based on customer questions
Generate handling suggestions based on historical tickets
Automatically produce meeting minutes, weekly reports, and risk lists
These tasks are more suitable for ChatGPT 5.5. Therefore, the best practice for enterprise knowledge bases is not a single model but a hybrid model:
Task type Recommended model Standard policy Q&A Claude Opus 4.7 Long-document summarization Claude Opus 4.7 Complex workflow execution ChatGPT 5.5 Tool invocation and automation ChatGPT 5.5 Final risk review Claude Opus 4.7
10. AI Stock Analysis Scenarios: ChatGPT 5.5 for Main Analysis, Claude for Risk Validation
For AI stock analysis platforms, the key model capabilities are not only summarizing news but completing structured analysis. A high-quality stock analysis system needs to handle earnings reports, news, technical indicators, market sentiment, industry cycles, macro risks, and company fundamentals simultaneously.
In this scenario, ChatGPT 5.5’s advantages are clearer. It is better suited to multi-agent analysis, for example:
Fundamentals Agent: analyze revenue, profit, cash flow, debt, and valuation
Technical Agent: analyze trends, moving averages, volume, and volatility
News Sentiment Agent: analyze recent news and market opinion
Risk Agent: identify policy, litigation, financial, and industry risks
Long/Short Debate Agent: generate bullish and bearish viewpoints
Summary Agent: integrate signals and generate a structured conclusion
Claude Opus 4.7 is better suited as a risk-control model here. It can check:
Whether conclusions are overly certain
Whether risk warnings are missing
Whether speculation is stated as fact
Whether there are non-compliant investment advice expressions
Whether the chain of evidence is sufficient
Stock analysis modules Recommended model Financial statement parsing ChatGPT 5.5 / Claude Opus 4.7 Multi-agent analysis ChatGPT 5.5 Research report draft ChatGPT 5.5 Risk review Claude Opus 4.7 Compliance phrasing optimization Claude Opus 4.7 Multilingual output ChatGPT 5.5
So for AI stock analysis products like AlphaVue.ai, the optimal solution is not to use a single model but a "primary analysis model + audit model" combination. ChatGPT 5.5 handles deep analysis and reasoning; Claude Opus 4.7 handles risk control and expression checks.
11. Long-Context and Document Processing Comparison
Long-context capability has long been an advantage of the Claude series. Claude Opus 4.7 is usually more stable when handling long documents, contracts, technical docs, meeting minutes, and enterprise materials. Its output style is more restrained and less likely to expand beyond the document basis without cause.
ChatGPT 5.5 also has strong document-processing abilities, especially for executing tasks on top of documents. For example, it can read documents and then generate action plans, extract action items, produce code, or produce project plans.
Document tasks ChatGPT 5.5 Claude Opus 4.7 Contract summarization Strong More stable Paper reading Strong, better for further analysis Strong, better for accurate summarization Multi-document comparison Strong Very strong Generating plans from documents Strong Strong but more conservative Enterprise policy Q&A Strong More suitable
12. Output Style Comparison: ChatGPT More Flexible, Claude More Restrained
Output style affects real-world experience. ChatGPT 5.5 is more flexible in expression, suitable for creative writing, marketing, product plans, technical proposals, and report generation. It often proactively adds structure, suggestions, and actionable steps.
Claude Opus 4.7's expression is more restrained and its logic more stable; it is suitable for formal documents, compliance materials, audit reports, and internal enterprise documents. It usually does not overextend, making it more reliable in high-risk scenarios.
Output type Better-suited model Marketing copy ChatGPT 5.5 Technical proposals ChatGPT 5.5 Compliance reports Claude Opus 4.7 Legal text Claude Opus 4.7 Product blog ChatGPT 5.5 Enterprise policy summaries Claude Opus 4.7
13. Cost and Value-for-Money Analysis
Model cost should not be judged only by token price; task completion efficiency matters. A model with a higher per-token price might be cheaper overall if it completes complex tasks in one go and reduces manual rework.
ChatGPT 5.5’s cost-effectiveness mainly comes from execution efficiency. It is better at completing complex tasks in one pass, especially in coding, data analysis, research, and automation workflows, which reduces a lot of manual effort.
Claude Opus 4.7’s value lies in stability and risk control. For enterprises, a single incorrect answer can cause losses far greater than token costs. Therefore, Claude’s stability itself has intrinsic value in legal, compliance, security, contract, and enterprise knowledge-base scenarios.
Cost dimensions ChatGPT 5.5 Claude Opus 4.7 Single-task execution efficiency High High Complex task completion rate Strong Strong Rework cost Depends on constraint quality Usually lower Compliance risk cost Requires extra control Lower Overall cost-effectiveness Suitable for productivity scenarios Suitable for high-reliability scenarios
14. Which Model Should Different Users Choose?
User type Recommended model Reason General users ChatGPT 5.5 More flexible and suitable for daily tasks Developers ChatGPT 5.5 + Claude Opus 4.7 ChatGPT writes code; Claude reviews it Data analysts ChatGPT 5.5 Better for analytical chains and tool invocation Legal / compliance Claude Opus 4.7 More stable and cautious Enterprise knowledge-base teams Claude Opus 4.7 + ChatGPT 5.5 Claude for stable Q&A, ChatGPT for complex tasks AI customer service teams ChatGPT 5.5 Stronger multi-turn dialogue and tool invocation Stock analysis platforms ChatGPT 5.5 for main analysis, Claude Opus 4.7 for review Balancing reasoning and risk control Content creators ChatGPT 5.5 More flexible expression and stronger creative ability
15. Commercial Deployment Advice: Don’t Rely on a Single Model — Use Multi-Model Collaboration
For real commercial systems, a single-model architecture will increasingly be insufficient. Different tasks require different model properties: some require creativity, others require stability; some require fast execution, others require strict review; some require multi-tool calls, others require low-risk outputs.
Therefore, a more mature future AI system should adopt a multi-model collaborative architecture.
User request
↓
Task classifier
↓
Simple Q&A → Claude Opus 4.7
Complex execution → ChatGPT 5.5
Code generation → ChatGPT 5.5
Code review → Claude Opus 4.7
Risk review → Claude Opus 4.7
Multilingual generation → ChatGPT 5.5
↓
Result merge
↓
Final outputThis architecture leverages ChatGPT 5.5’s execution capabilities while using Claude Opus 4.7’s stability and safety boundaries.
16. Future Trend: Model Competition Shifts from "Parameter Scale" to "Task Completion Rate"
Past model competition focused on parameter counts, base capabilities, and chat quality. The industry has entered a new phase: what really matters is task completion rate.
In the future, enterprises will increasingly evaluate models on metrics like:
Complex task completion rate
Tool invocation success rate
Code-fix success rate
Long-document understanding accuracy
Hallucination rate
Security violation rate
Unit task cost
Enterprise system integration capability
ChatGPT 5.5 and Claude Opus 4.7 represent two different routes. OpenAI emphasizes execution, productivity, and agentification; Anthropic emphasizes safety, stability, and enterprise-level controllability. These approaches are not mutually exclusive and will be complementary in real business.
17. Final Conclusion
The comparison between ChatGPT 5.5 and Claude Opus 4.7 is essentially not about which is absolutely stronger, but which is better suited for a given class of tasks.
ChatGPT 5.5 is better suited for:
Complex task execution
Code generation and bug fixing
Agent workflows
Data analysis
Office automation
AI customer service
Stock analysis and report generation
Multilingual content production
Claude Opus 4.7 is better suited for:
Long-document processing
Enterprise knowledge bases
Legal and compliance texts
Code review
Risk control
High-security requirement scenarios
Document summarization and audit tasks

If you are an individual user, ChatGPT 5.5 may be more versatile; if you are an enterprise, Claude Opus 4.7’s stability may be more attractive; if you are building AI products—especially RAG, agents, AI customer service, or stock analysis platforms—the optimal solution is usually not an either/or but multi-model collaboration.
Final verdict: ChatGPT 5.5 handles creation, reasoning, and execution; Claude Opus 4.7 handles review, constraint, and stable output. The future competitive AI systems will not rely on a single model but will let different models play to their strengths in different stages.