
GPT-5.6 Sol Ultra и Claude Opus 4.7 представляют две разные концепции передового ИИ. Одна ориентирована на агентную оркестровку, режимы глубокого рассуждения и расширяющуюся экосистему продуктов OpenAI. Другая построена вокруг аккуратного исполнения, работы с длинным контекстом, надёжности при кодировании и дисциплины рабочих процессов корпоративного уровня. Настоящий вопрос уже не просто «какая модель умнее?». Вопрос — «какая модель соответствует тому, как вы действительно работаете?»
Гонка моделей ИИ изменилась. Год назад большинство сравнений моделей сосредотачивалось на качестве ответов: какая модель написала лучшее эссе, решила самую трудную загадку, суммировала самый длинный PDF или сгенерировала самый чистый фрагмент кода. Это по-прежнему важно, но этого уже недостаточно. В 2026 году рубеж сместился в сторону ИИ‑систем, которые умеют планировать, использовать инструменты, управлять контекстом, восстанавливаться после ошибок и продолжать работу над многошаговыми задачами. Самой ценной моделью не всегда является та, что даёт самый впечатляющий единичный ответ. Часто это модель, которая способна завершить наиболее полезный рабочий процесс с наименьшим трением.
Именно поэтому сравнение между GPT-5.6 Sol Ultra и Claude Opus 4.7 представляет интерес. Эти модели — не просто апгрейды чат‑ботов. Они претендуют на роль интеллектуального слоя для агентов разработки ПО, помощников‑копилотов в исследованиях, систем финансового анализа, корпоративной автоматизации и рабочих процессов поддержки принятия решений. Для разработчиков вопрос сводится к тому, какая из моделей лучше подходит для кодирования, отладки, архитектуры и агентного исполнения. Для бизнеса — какая модель даёт лучшее соотношение цены и качества. Для инвесторов и аналитиков — какая модель умеет преобразовывать шумную информацию в структурированные инсайты.
Эта статья сравнивает две модели по публично доступной информации, ценообразованию, кейсам использования в кодировании, поведению при рассуждении, контексту бенчмарков, рабочим процессам разработчиков, производительности AI‑агентов и реальным исследовательским сценариям. Там, где доступны надёжные публичные данные, мы их используем. Там, где независимое покрытие бенчмарков всё ещё ограничено, особенно для GPT‑5.6 Sol Ultra в период раннего превью, мы избегаем притворяться, что точные рейтинги уже установлены. Хорошее сравнение ИИ должно помогать людям принимать более взвешенные решения, а не порождать ложную уверенность.
Важное замечание по источникам: GPT‑5.6 Sol Ultra всё ещё находится на ранней стадии публичного цикла. Наиболее полезные публичные отчёты описывают GPT‑5.6 как набор моделей в ограниченном превью, где Sol выступает флагманом, а также доступны режимы Max и Ultra для более глубоких рассуждений и оркестровки под‑агентов. Для Claude Opus 4.7 имеется больше прямой официальной информации от Anthropic, включая доступ к API, цены и отзывы тестировщиков. Поэтому в этом сравнении подтверждённые данные отделены от практической интерпретации.
Гонка ИИ изменилась: от чат‑ботов к интеллектуальным агентам

Самый простой способ неверно понять сравнение GPT-5.6 Sol Ultra и Claude Opus 4.7 — рассматривать его как простое соревнование чат-ботов. Такая постановка устарела. Лучшие модели больше не конкурируют только в умении написать лучший абзац или ответить на вопрос викторины. Они конкурируют в том, смогут ли они функционировать как интеллектуальные работники внутри большей системы.
В эпоху чат-ботов пользователь выполнял большую часть работы. Пользователь делил задачу на части, писал тщательно продуманные подсказки, переносил вывод в другие инструменты, проверял ошибки вручную, задавал уточняющие вопросы и собирал окончательный ответ. Модель была мощной, но пассивной. Она ждала инструкций.
В эпоху агентов от модели ожидают больше координации. Она должна понимать цель, планировать шаги, собирать доказательства, использовать инструменты, писать или модифицировать код, тестировать результат, анализировать сбои, пересматривать подход и предоставлять результат, готовый к принятию решения. Это не значит, что ИИ автономен в магическом смысле. Это означает, что единица ценности смещается с одного ответа к завершённому рабочему процессу.
Похоже, GPT-5.6 Sol Ultra разработан для такого сдвига. Публичные отчёты описывают Sol как флагман OpenAI в семействе GPT-5.6, с сильными сторонами в программировании, кибербезопасности, биологии и долгосрочных агентных задачах. Особую заметность приобретает режим Ultra, поскольку о нём говорят как о использующем субагентов. Такая формулировка важна. Оркестровка субагентов подразумевает модель, спроектированную не только для рассуждений в одном потоке, но и для распределения работы между специализированными внутренними или внешними процессами.
Claude Opus 4.7 идёт из другого, но не менее важного направления. Публичные материалы Anthropic подчёркивают сложные многошаговые рабочие процессы, программирование, использование инструментов, длительно выполняющиеся задачи, дисциплину в работе с данными, следование инструкциям и последовательность. Ранние отзывы тестировщиков отмечали способность Claude Opus 4.7 выявлять логические ошибки при планировании, продолжать работу при сбоях инструментов и избегать правдоподобных, но неподкреплённых решений. Это не просто «лучшее письмо». Это надёжность в выполнении рабочего процесса.
Это создаёт центральный контраст: GPT-5.6 Sol Ultra похож на модель, оптимизированную для оркестровки и экосистем агентов, тогда как Claude Opus 4.7 похож на модель, оптимизированную для аккуратного, надёжного выполнения при долгой и сложной работе. Победитель зависит от того, ценит ли ваш кейс широкую интеграцию в экосистему и агентную гибкость, или же последовательность в длинном контексте и консервативную точность.
GPT-5.6 Sol Ultra vs Claude Opus 4.7: Краткое сравнение
Прежде чем углубляться в бенчмарки и рабочие процессы, вот обзор на высоком уровне. Эта таблица не предназначена для объявления универсального победителя. Она призвана прояснить, в чём каждая модель кажется сильнее на основе текущей публичной информации и практических шаблонов использования.
Категория GPT-5.6 Sol Ultra Claude Opus 4.7 Основная позиция: флагманский вариант набора моделей OpenAI, ориентированный на продвинутые рассуждения, кодирование и агентные рабочие процессы, с режимом Ultra, описываемым как оркестрация субагентов. Anthropic: модель Opus на передовой, сфокусированная на кодировании, работе с длинным контекстом, сложных задачах, стабильном исполнении и внимательном следовании инструкциям. Наилучшее применение: агентные рабочие процессы, приложения экосистемы OpenAI, оркестрация инструментов, автоматизированные исследования, мультимодальные и продуктовые AI-решения. Длинные документы, сложные задачи по кодированию, тщательный анализ, корпоративные инженерные рабочие процессы, Claude Code и структурированное рассуждение. Кодирование: сильный кандидат для агентного кодирования и автоматической отладки, особенно там, где центральную роль играет инструментарий OpenAI. Очень сильные публичные позиции в задачах кодирования и длительных программных заданиях; доступен в Claude Code и интеграциях с GitHub Copilot. Ценообразование: публичные отчеты указывают GPT-5.6 Sol по $5 за миллион входных токенов и $30 за миллион выходных токенов в период превью. Anthropic заявляет, что Claude Opus 4.7 остается по $5 за миллион входных токенов и $25 за миллион выходных токенов. Достоверность бенчмарков: независимые публичные данные бенчмарков по-прежнему ограничены из-за раннего этапа превью. Доступно больше обратной связи от экосистемы и официальных заявлений Anthropic; покрытие независимых бенчмарков варьируется в зависимости от теста. Возможности агентов: потенциально сильнее в оркестрации субагентов и широких AI-продуктовых рабочих процессах. Потенциально сильнее в надежном долговременном выполнении и рабочих процессах, зависящих от инструментов. Практический выбор: выбирайте его, когда вам нужна нативная для OpenAI агентная система, широкая интеграция в экосистему и продвинутые режимы рассуждений. Выбирайте его, когда вам нужно дисциплинированное кодирование, анализ документов, надежность при длинном контексте и тщательные результаты.
Философия модели: OpenAI Sol Ultra vs Anthropic Opus
У OpenAI и Anthropic разные продуктовые философии, и эти различия проявляются в поведении моделей. Передовые модели OpenAI все чаще ощущаются не просто как «мозг», а как компоненты расширяющейся операционной системы ИИ: ChatGPT, API-рабочие потоки, мультимодальные входы, использование инструментов, среды для кодирования, корпоративные интеграции и агентные продуктовые поверхности. Модель — это не просто генератор ответов. Она часть системы, которая стремится выполнять больше задач пользователя от начала до конца.
GPT-5.6 Sol Ultra вписывается в этом направлении. Бренд Sol намекает на флагманский уровень, а Ultra — на наиболее способный режим для сложных задач. Ключевая фраза — оркестрация субагентов. На практике самые продвинутые ИИ-системы начинают выглядеть не как один гигантский генератор ответов, а как менеджер специализированных работников. Один агент может проверять исходный код. Другой — искать в документации. Третий — оценивать вопросы безопасности. Четвертый — суммировать компромиссы. Основная модель координирует эти усилия и формирует итоговый результат.
Философия Anthropic Opus больше ориентирована на надежный интеллект. Claude давно известен качеством письма, пониманием длинного контекста и осторожным стилем. Claude Opus 4.7 расширяет этот подход для профессиональной работы. В анонсе Anthropic делали упор на обратную связь от компаний, занимающихся кодированием, данными, исследованиями и рабочими процессами. Речь меньше о показательных демо и больше о снижении ошибок при работе с инструментами, лучшем планировании, более надежном выполнении длительных задач и ясном уведомлении, когда данных недостаточно.
Это различие имеет значение, потому что многие сбои ИИ в продакшене вызваны не отсутствием «сырого» интеллекта. Они вызваны плохим поведением в рабочем процессе. Модель выдумывает недостающую информацию. Она останавливается слишком рано. Она молча даёт сбой. Она следует неверной иерархии инструкций. Она неправильно использует инструменты. Она меняет задачу, не объясняя, почему. Она выдаёт впечатляющий результат, который на самом деле не обоснован доступными доказательствами. Коммуникация Anthropic вокруг Claude Opus 4.7 прямо нацелена на эти производственные проблемы.
Практический вывод прост: GPT-5.6 Sol Ultra может быть более интересен разработчикам, которые хотят, чтобы ИИ-системы координировали множество задач и глубоко интегрировались в экосистему продукта. Claude Opus 4.7 может быть более привлекательным для команд, которым нужна тщательная реализация, сильное управление контекстом и меньше неожиданных ошибок в рассуждениях при длительных профессиональных рабочих процессах.
Сравнение бенчмарков: какая модель ИИ умнее?

Бенчмарки полезны, но только если их правильно интерпретировать. Номер в таблице лидеров — не то же самое, что пригодность для продукта. Модель может хорошо выступать на бенчмарке и при этом быть раздражающей в реальном рабочем процессе. Другая модель может немного отставать в синтетическом тесте, но лучше следовать инструкциям, использовать инструменты или поддерживать контекст в ходе длительной задачи.
Что касается GPT-5.6 Sol Ultra, честная ситуация с бенчмарками такова: независимых публичных результатов пока мало. Поскольку модель была представлена в ограниченном превью, широкое покрытие сторонними бенчмарками ещё не стабилизировалось. Это значит, что любую статью, утверждающую о точных универсальных рейтингах GPT-5.6 Sol Ultra по всем бенчмаркам, следует воспринимать осторожно, если только она не ссылается на реальный публичный лидерборд или официальное опубликованное оценивание.
По Claude Opus 4.7 публичного материала больше. Собственное объявление Anthropic включает обратную связь ранних тестировщиков по задачам кодирования, агентным исследовательским задачам, анализу данных и многошаговым рабочим процессам. GitHub также объявил о развёртывании Claude Opus 4.7 в GitHub Copilot, и раннее тестирование указывает на более сильную производительность в многошаговых задачах и более надёжное агентное исполнение. Это не то же самое, что нейтральные академические бенчмарки, но это важно, потому что данные поступают из контекстов продуктов для разработчиков, где имеют значение реальные рабочие процессы.
Независимые сайты с бенчмарками, такие как SWE-bench и Artificial Analysis, важны тем, что они обеспечивают внешний контекст. SWE-bench фокусируется на реальных проблемах программной инженерии, включая отфильтрованный человеком Verified-поднабор. Artificial Analysis сравнивает модели по показателям интеллекта, скорости, цене, объёму выходных токенов и стоимости за задачу. Эти платформы ценны тем, что помогают отделить маркетинговые утверждения от измеримого поведения. Однако к ним также нужно относиться с осторожностью: результаты бенчмарков зависят от подводки, доступа к инструментам, дизайна подсказок, агентной рамки и правил оценки.
Лучший способ читать ландшафт бенчмарков — не «GPT побеждает» или «Claude побеждает». Вместо этого думайте по категориям:
-
Тесты на способность рассуждать проверяют, может ли модель решать сложные задачи, но могут не отражать использование в производственных инструментах.
-
Бенчмарки по программированию проверяют починку или генерацию ПО, но результаты сильно зависят от инфраструктуры агента.
-
Бенчмарки для длинного контекста проверяют извлечение и синтез по большим входным данным, но в реальных проектах есть неопрятные файлы, противоречивые требования и неполная информация.
-
Бенчмарки для агентов ближе к реальной работе, но они всё ещё быстро развиваются.
-
Бенчмарки по стоимости имеют значение, потому что модель, которая на 5% лучше, но в 3 раза дороже, может быть хуже для производства.
Если вам нужен строгий ответ по бенчмаркам сегодня, у Claude Opus 4.7 сейчас больше публичных оснований, потому что Anthropic опубликовала официальные детали, и партнёры по экосистеме обсудили её производительность. GPT-5.6 Sol Ultra обладает более сильным стратегическим потенциалом в плане оркестровки суб-агентов, но независимая валидация всё ещё догоняет. Этот разрыв может быстро сокращаться по мере расширения превью.
Сравнение в программировании: GPT-5.6 Sol Ultra против Claude Opus 4.7 для разработчиков

Программирование — одно из важнейших полей битвы для передовых моделей, потому что разработчики — одни из самых ценных пользователей ИИ. Они часто используют модели, платят за премиальные инструменты и привлекают модели к сложным реальным задачам: рефакторинг устаревших систем, отладка нестабильных тестов, проектирование архитектуры, изучение незнакомых кодовых баз, написание миграций, генерация тест-кейсов и работа внутри IDE.
У Claude Opus 4.7 сегодня есть явное публичное преимущество в надёжности для программирования, потому что Anthropic и GitHub оба позиционируют её вокруг рабочих процессов программной инженерии. В заявлении Anthropic есть отзывы ранних тестировщиков, которые описывают лучшее планирование, меньше ошибок инструментов и более сильную производительность в сложных рабочих процессах по кодированию. В журнале изменений GitHub указано, что Opus 4.7 внедряется в GitHub Copilot и описаны улучшения в многошаговых задачах, дальновидном рассуждении и рабочих процессах, зависящих от инструментов. Для разработчиков это важнее, чем демонстрация одного фрагмента кода.
Причина, по которой Claude часто хорошо показывает себя в программировании, не только в умении писать код. Многие модели умеют писать код. Сложность заключается в понимании существующей архитектуры проекта, сохранении стиля, соблюдении ограничений, внесении минимальных изменений, диагностике сбоев и умении не чрезмерно осложнять решение. Аккуратный стиль Claude полезен в этом. Модель склонна продуманно рассуждать о проблеме, объяснять компромиссы и избегать поспешных решений. В большой кодовой базе такая осторожность может быть преимуществом.
История программирования GPT-5.6 Sol Ultra другая. Публичные отчёты подчёркивают, что GPT-5.6 Sol особенно силён в программировании и в задачах с долгосрочной агентной организацией. Если режим Ultra действительно улучшает оркестровку суб-агентов, модель может быть очень сильной в рабочих процессах по кодированию, требующих параллельного рассуждения: один суб-агент читает тесты, другой проверяет реализацию, третий ищет в документации, четвёртый предлагает патч, а пятый проверяет граничные случаи. Такая структура очень релевантна современной ИИ-инженерии программного обеспечения.
Для одного разработчика в IDE Claude Opus 4.7 может показаться более надежным, если задача — чтение и модификация существующей кодовой базы. Для создателя платформы, создающего автоматизированных кодирующих агентов, GPT-5.6 Sol Ultra может быть интереснее, потому что архитектура указывает на оркестрацию. Но пока независимые бенчмарки по программированию и реальные отчёты разработчиков не станут более широкими, правильный вывод не в том, что GPT-5.6 уже победил Claude. Правильный вывод в том, что обе модели могут быть оптимизированы для разных рабочих процессов кодирования.
В чём Claude Opus 4.7 может быть сильнее при кодировании
-
Понимание больших кодовых баз с множеством ограничений.
-
Следование детальным инструкциям в длительных сессиях.
-
Объяснение компромиссов и избегание неподдерживаемых предположений.
-
Работа внутри интеграций Claude Code и GitHub Copilot.
-
Сложный рефакторинг, где важна тщательная работа с контекстом.
В чём GPT-5.6 Sol Ultra может быть сильнее при кодировании
-
Агентные системы кодирования, которые используют несколько инструментов и субагентов.
-
Автоматизированные рабочие процессы, требующие циклов планирования, выполнения и валидации.
-
Нативные для OpenAI продукты для разработчиков и агенты, построенные на API.
-
Задачи, которые объединяют код, документы, логи, скриншоты и мультимодальный контекст.
-
Быстрая итерация в рамках более широких экосистем AI-продуктов.
Если ваш вопрос «какую модель использовать в Cursor, Claude Code, Copilot или во внутреннем кодирующем агенте?», ответ — протестировать обе на вашем реальном репозитории. Используйте пять задач: одно исправление бага, один рефакторинг, одну функцию, одну задачу по генерации тестов и одно объяснение архитектуры. Измеряйте не только собирается ли код, но и сколько шагов требуется, сколько файлов затрагивается, соблюдается ли стиль и придумывает ли модель новые API. Это скажет вам больше, чем рейтинг.
Способности к рассуждению: глубокое мышление против прагматичного интеллекта
«Рассуждение» — самое переиспользуемое слово в маркетинге ИИ. Каждая передовая модель претендует на лучшее рассуждение. Более полезный вопрос: какой тип рассуждений модель выполняет хорошо?
История рассуждений GPT-5.6 Sol Ultra связана с режимами. Публичные сообщения говорят, что у Sol есть режим Max для более глубоких рассуждений и режим Ultra для оркестрации субагентов. Это подразумевает модель, спроектированную для выделения большего вычислительного ресурса и структуры на сложные задачи. Для пользователя это может проявляться как лучшее планирование, более качественное декомпозирование задач, улучшенная координация инструментов и меньше поверхностных ответов на трудные вопросы.
История рассуждений Claude Opus 4.7 связана с дисциплиной. Публичные примеры Anthropic подчёркивают обнаружение логических ошибок при планировании, корректное указание на недостающие данные, сопротивление ловушкам и продолжение работы при сбоях инструментов. Такой тип рассуждений чрезвычайно ценен в профессиональной работе. Речь идёт не только о решении головоломки. Речь о том, чтобы понимать, какие есть доказательства, чего не хватает, что можно вывести и чего не следует утверждать.
Apply this research method to your stock
Generate bull/bear views, risk notes, and an evidence trail for GPT.
Для пользователя разница может ощущаться так: GPT-5.6 Sol Ultra скорее будет вести себя как энергичный стратег, способный координировать сложный рабочий процесс, тогда как Claude Opus 4.7 скорее будет вести себя как внимательный старший аналитик, защищающий от слабых предположений. Оба стиля полезны. Лучшая модель зависит от стоимости ошибки.
Если вы разрабатываете стратегию продукта, строите рабочий процесс AI-агента или быстро генерируете множество вариантов, GPT-5.6 Sol Ultra может быть более мощным креативным движком. Если вы просматриваете контракт, анализируете длинный финансовый отчет, проверяете конвейер данных или расследуете инцидент в производстве, осторожность Claude Opus 4.7 может оказаться более ценной.
Самые глубокие системы рассуждений в конечном счете объединят оба стиля: смелое разложение задач на части и консервативную верификацию. Вот почему важны агентные рабочие процессы. Хорошая AI-система не должна полагаться на одну «личность» модели. Следует использовать одну модель для генерации гипотез, другую — чтобы их оспаривать, третью — для проверки источников, и ещё одну — чтобы превратить результат в практическое решение. Это особенно важно в финансовых исследованиях, где уверенные, но необоснованные выводы могут дорого обойтись.
Длинный контекст и работа с документами
Длинный контекст — одна из сильнейших ассоциаций бренда Claude. Модели Claude широко используются для чтения документов, контрактов, кодовых баз, научных статей и деловых отчетов. Claude Opus 4.7 продолжает эту тенденцию, делая акцент на согласованности при работе с длинным контекстом и профессиональной работе с знаниями. В объявлении Anthropic приведены отзывы тестировщиков, хваливших дисциплину данных, раскрытие отсутствующих данных и сильные показатели при работе с длинным контекстом.
Длинный контекст — это не только размер окна. Окно в миллион токенов звучит впечатляюще, но важно то, правильно ли модель использует контекст. Может ли она найти релевантную деталь? Может ли она не отвлекаться на нерелевантный текст? Может ли она примирить противоречивые источники? Может ли она сказать пользователю, когда ответа нет в доступных данных? Может ли она сохранять ограничения от начала задачи до её завершения?
Claude Opus 4.7 кажется особенно пригодным для задач, где ввод длинный, неаккуратный и важный. Это такие случаи, как юридическая экспертиза, анализ политики, инвестиционные меморандумы, техническая документация, базы знаний службы поддержки клиентов, папки due diligence, руководства по комплаенсу и большие репозитории кода. В этих ситуациях контроль галлюцинаций и дисциплина работы с контекстом могут иметь большее значение, чем скорость.
GPT-5.6 Sol Ultra может выглядеть более убедительно, когда длинный контекст является частью более широкого рабочего процесса. Например, вместо простого чтения длинного отчета агентная система может суммировать отчет, извлечь ключевые метрики, сравнить их с рыночными данными, проверить последние новости, сгенерировать инвестиционные гипотезы, обсудить факторы риска и выработать итоговую тезисную рекомендацию. Если оркестрация суб-агентов в режиме Ultra работает хорошо, GPT-5.6 может быть мощным в такого рода мульти-источниковых рабочих процессах.
Итак, отличие не в том, «Claude для длинного контекста, GPT для всего остального». Точнее: Claude Opus 4.7 может быть сильнее в тщательном чтении длинного контекста и обоснованном синтезе, тогда как GPT-5.6 Sol Ultra может быть сильнее для рабочих процессов с длинным контекстом, требующих оркестрации, использования инструментов и многоэтапного исполнения.
Производительность AI-агентов: реальное различие
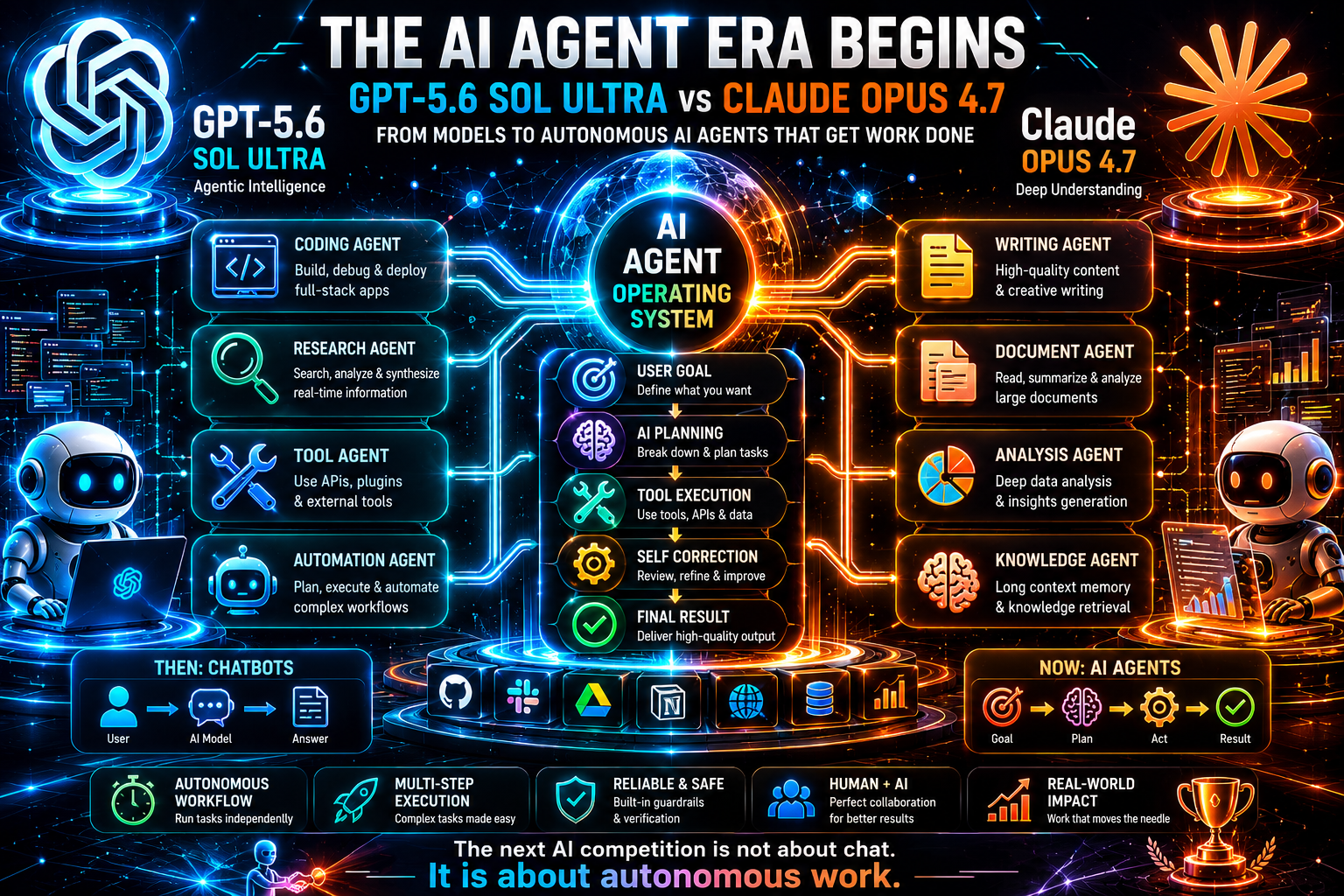
Самая важная категория в этом сравнении — производительность AI-агентов. Именно туда движется рынок. Чат-боты полезны, но агенты — это то место, где прирост производительности становится измеримым. AI-агент может принять цель, спланировать шаги, вызывать инструменты, использовать API, проверять результаты, корректировать план и продолжать до завершения задачи или до момента, когда требуется решение человека.
Сильнейший нарратив GPT-5.6 Sol Ultra — это агентная оркестрация. Описание режима Ultra указывает на субагентов, что является одним из важнейших паттернов в продвинутом дизайне систем ИИ. Один вызов модели может быть мощным, но сложная работа выигрывает от специализированных ролей: исследователь, критик, программист, тестировщик, аналитик рисков, суммаризатор и агент принятия решений. Если GPT-5.6 Sol Ultra оптимизирован под такую структуру, он может стать прочной основой для продуктов следующего поколения.
Сильнейший нарратив Claude Opus 4.7 — это агентная надёжность. Anthropic и GitHub оба подчёркивают выполнение многошаговых задач, длительную работу, рабочие процессы, зависящие от инструментов, и меньшее число сбоев. В продакшене надёжность часто ценнее амбиций. Агент, который пытается сделать слишком многое и молча ломается, опасен. Агент, который действует осторожно, сообщает о неопределённости и восстанавливается после сбоев инструментов, вызывает больше доверия.
Это создаёт полезное различие для разработчиков:
-
Используйте GPT-5.6 Sol Ultra, когда агенту нужна широкая оркестрация, множество специализированных шагов и интеграция с рабочими процессами, родными для OpenAI.
-
Используйте Claude Opus 4.7, когда агенту требуется тщательная работа с контекстом, длительное кодирование или исследование и надёжное выполнение в сложных условиях.
-
Используйте оба, когда задача высокоцелевая: одна модель может генерировать и планировать, а другая — критиковать, проверять или переписывать.
Будущее AI-агентов не сводится к тому, что одна модель заменит все остальные. Это будет интеллектуальная маршрутизация. Платформа будет выбирать лучшую модель для каждого этапа рабочего процесса. Она может использовать более дешёвую модель для классификации, быструю модель для извлечения, Claude для анализа длинных документов, GPT для оркестрации и специализированную модель для изменений в репозитории. Победит не просто продукт с самой большой моделью, а продукт с лучшим дизайном рабочего процесса.
Сравнение цен: какая модель даёт лучшую ценность?

Ценообразование — это то место, где сравнение становится осязаемым. По публичным данным, GPT-5.6 Sol стоит $5 за миллион входных токенов и $30 за миллион выходных токенов. Anthropic заявляет, что Claude Opus 4.7 стоит $5 за миллион входных токенов и $25 за миллион выходных токенов. Это делает Claude Opus 4.7 дешевле по выходным токенам, если эти цифры являются основой ценообразования для вашей развертки.
Модель Цена за входные токены Цена за выходные токены Вывод по ценообразованию GPT-5.6 Sol $5 / 1M входных токенов $30 / 1M выходных токенов Та же цена за входные токены, что и у Opus 4.7, более высокая цена за выходные токены, исходя из текущих публичных отчётов. Claude Opus 4.7 $5 / 1M входных токенов $25 / 1M выходных токенов Ниже цена за выходные токены, хорошо подходит для длительных рабочих процессов по кодированию и работе с документами при контролируемом использовании токенов.
Однако цена за токен сама по себе не определяет реальную стоимость. Реальная стоимость зависит от длины вывода, размера контекста, кэширования подсказок, частоты повторных прогонов, вызовов инструментов, задержки и того, насколько часто модель дает правильный ответ с первого раза. Дешёвая модель может стать дорогой, если требует множества повторных попыток. Более дорогая модель может быть дешевле, если она выполняет задачу с меньшим числом вызовов. Для кодирующих агентов главным фактором затрат часто является не первоначальная подсказка, а итеративный цикл: просмотр файлов, предложение изменений, запуск тестов, чтение ошибок, исправление и повторение.
Business Insider сообщил, что Anthropic обновила свои оценки расхода токенов для Claude Code, заявив, что средняя стоимость на активный день для корпоративного разработчика составляет около $13, а $150–$250 в месяц на разработчика, при том что 90% пользователей укладываются в менее чем $30 за активный день. Важно не то, что Claude уникально дорог — важно то, что использование AI‑агентов меняет структуру расходов. Когда модели становятся рабочими, а не просто источниками ответов, они потребляют больше токенов, потому что выполняют больше работы.
Для продуктовых команд вопрос ценообразования следует формулировать как стоимость за завершённый рабочий процесс. Например:
-
Сколько стоит обработка одного тикета в службу поддержки?
-
Сколько стоит исправить один баг?
-
Сколько стоит подготовить один инвестиционный бриф?
-
Сколько стоит проанализировать один earnings call (телефонную конференцию по результатам отчётного периода)?
-
Сколько стоит отслеживание одной акции в течение недели?
Когда вы измеряете стоимость таким образом, лучшая модель может различаться в зависимости от задачи. Claude Opus 4.7 может быть более экономичным для аккуратных выводов с большим контекстом, потому что цена за выходной токен у неё ниже, а стиль работы может сокращать переработки. GPT‑5.6 Sol Ultra может быть экономичнее в рабочих процессах, где оркестрация сокращает время на координацию людей. Единственный надёжный способ узнать — проводить оценку на уровне задач с реальными подсказками, реальными файлами и реальными критериями успеха.
Опыт разработчика: Claude Code, GitHub Copilot, API и фреймворки агентов
Качество модели важно, но за внедрение отвечает опыт разработчика. Модель, которая чуть лучше, но сложнее в интеграции, может проиграть модели, которая естественно вписывается в существующие рабочие процессы. Именно поэтому Claude Code, GitHub Copilot, ChatGPT, инструменты для работы с API и фреймворки агентов так важны.
Claude Opus 4.7 выигрывает от интеграции в те среды разработки, где уже работают пользователи. Объявление GitHub о том, что Opus 4.7 разворачивается в Copilot, даёт ей распространение внутри одного из важнейших продуктов для кодирования в мире. Claude Code также предоставляет Anthropic прямой интерфейс для агентной инженерии ПО. Для разработчиков, которые хотят мощного партнёра по кодированию, а не сырое API, это имеет значение.
GPT‑5.6 Sol Ultra выигрывает от более широкой экосистемы OpenAI. ChatGPT остаётся массовым интерфейсом ИИ, API OpenAI имеет сильную популярность среди разработчиков, а продуктовая стратегия компании всё больше поддерживает инструменты, мультимодальные рабочие процессы и агентные приложения. Если ваша команда уже строит решения на OpenAI API, GPT‑5.6 Sol Ultra может быть проще принять как путь обновления.
Вопрос об опыте разработчика должен включать:
-
Работает ли модель внутри инструментов, которые ваша команда уже использует?
-
Может ли она безопасно вызывать ваши внутренние инструменты?
-
Можете ли вы контролировать использование токенов и успех рабочих процессов?
-
Можете ли вы маршрутизировать задачи между моделями?
-
Можете ли вы добавить защитные механизмы для безопасности, конфиденциальности и соответствия требованиям?
-
Может ли модель объяснить, что она сделала и почему?
Для внутренних AI‑платформ лучшим ответом может быть маршрутизатор моделей, а не приверженность одной модели. Используйте Claude Opus 4.7 для задач, требующих тщательного чтения и рассуждений по базе кода с длинным контекстом. Используйте GPT‑5.6 Sol Ultra для задач, ориентированных на планирование, интенсивное использование инструментов и оркестрацию множества агентов. Для извлечения, классификации и повторяющихся задач используйте более дешёвые модели. Такая архитектура более устойчива, чем ставка на одну передовую модель.
Исследования и анализ: какая модель лучше справляется со сложной информацией?
Исследования — это область, где модели ИИ могут создать огромное преимущество. Человеческий аналитик может тратить часы на чтение отчетов, документов, расшифровок, новостей, форумов, рыночных данных и внутренних документов. Хорошая модель ИИ способна сжать этот процесс. Но плохая исследовательская система на базе ИИ может порождать уверенное в себе бессмысленное содержимое.
Claude Opus 4.7 имеет веские основания для исследовательских задач благодаря дисциплине длинного контекста и осторожной обработке отсутствующих данных. В объявлении Anthropic приведены отзывы тестировщиков, описывающие лучшее раскрытие информации и дисциплину работы с данными. Это важно в исследованиях, потому что самые опасные ошибки часто не являются очевидными галлюцинациями. Это тонкие неподкреплённые выводы, которые звучат правдоподобно.
GPT‑5.6 Sol Ultra также имеет сильные аргументы для исследовательских рабочих процессов благодаря своей агентной ориентации. Исследования — это не только чтение. Это задавание правильных вопросов, сбор источников, сравнение точек зрения, выявление противоречий, обновление тезиса и решение о том, за чем следить дальше. Если режим Ultra улучшает оркестровку субагентов, GPT‑5.6 может быть особенно полезен в исследовательских системах, которые распределяют работу между несколькими агентами.
Например, финансовый исследовательский рабочий процесс может включать:
-
Агент новостей, который собирает недавние события, связанные с компанией.
-
Агент по отчетности, который извлекает данные о выручке, марже, долге и изменениях прогнозов.
-
Агент по рынку, который проверяет динамику цен, объёмы, волатильность и движение сектора.
-
Агент по рискам, который ставит под сомнение бычью гипотезу.
-
Агент по оценке, который сравнивает мультипликаторы и допущения.
-
Финальный синтезирующий агент, который готовит бриф, готовый к принятию решения.
Здесь GPT‑5.6 Sol Ultra и Claude Opus 4.7 могут быть полезны одновременно. GPT может координировать рабочий процесс. Claude может критиковать доказательства. Другая модель может дешево извлекать структурированные численные данные. Конечный продукт — это не ответ чатбота. Это нативный для ИИ исследовательский процесс.
Почему ИИ‑нативные инвестиционные исследования становятся возможными
Инвестиционные исследования — отличный пример того, почему гонка моделей ИИ превращается в гонку рабочих процессов. Инвесторам нужны не просто ответы. Им нужно структурированное мышление в условиях неопределённости. Им нужно понимать, что изменилось, почему это важно, какие доказательства поддерживают тезис, что может пойти не так и какой сигнал следует отслеживать далее.
Традиционные инструменты финансовых исследований часто статичны. Они показывают графики, коэффициенты, заголовки, оценки аналитиков и отчётные документы. Это полезно, но требует от пользователя самостоятельно соединять точки между данными. Пользователю всё равно приходится решать, какая информация важна, какие риски недооценены, какой нарратив меняется и какой показатель противоречит консенсусу.
Агенты ИИ могут это изменить. Агент по исследованиям может читать стенограммы отчётов о доходах. Агент по рискам может оспаривать предположения. Агент по оценке может сравнивать сценарии. Новостной агент может отслеживать катализаторы. Агент мониторинга может отслеживать события, разрушающие инвестиционную гипотезу. Агент дебатов может моделировать бычьи и медвежьи аргументы. Речь не о замене человеческого суждения. Речь о предоставлении инвесторам более совершенной операционной системы для исследований.
Именно сюда вписываются платформы вроде AlphaVue.ai в более широком сдвиге к ИИ. Следующее поколение инвестиционных платформ не будет просто отображать данные. Оно будет помогать пользователям рассуждать на их основе. Оно превратит рыночную информацию в рабочие процессы: сканировать, исследовать, обсуждать, сравнивать, мониторить и принимать решения. GPT-5.6 Sol Ultra и Claude Opus 4.7 важны не потому, что одна модель навсегда победит другую, а потому, что обе показывают, насколько рынок близок к инвестиционному интеллекту, изначально основанному на ИИ.
Для инвесторов ключевой вопрос уже не «может ли ИИ суммировать эту акцию?». Это базовый минимум. Настоящий вопрос: может ли ИИ помочь мне понять, что важно, что изменилось, что уже заложено в цену, что неопределённо и что делать дальше? Для этого нужны агентные рабочие процессы, маршрутизация моделей, дисциплина работы с источниками и прозрачная аргументация. Также нужен продуктовый дизайн. Мощная модель без хорошего рабочего процесса похожа на терминал Bloomberg без поиска, без оповещений и без структуры.
Перспектива AlphaVue.ai: от моделей ИИ к инвестиционным агентам на базе ИИ
Будущее финансовых исследований не будет представлять собой один гигантский чат‑бот. Это будет сеть специализированных агентов ИИ, которые исследуют компании, сравнивают рыночные сигналы, тестируют бычьи и медвежьи сценарии и помогают инвесторам отслеживать важное. AlphaVue.ai создана для такого ИИ-ориентированного инвестиционного рабочего процесса: более продуманные исследования, более ясные решения и более быстрая генерация инсайтов.
Практические кейсы: какую модель выбрать?
Нет универсального победителя между GPT-5.6 Sol Ultra и Claude Opus 4.7. Правильный выбор модели зависит от задачи. Вот практическая схема принятия решения.
Выберите GPT-5.6 Sol Ultra, если:
-
Вы создаёте агентов ИИ, которым требуется планирование, использование инструментов и оркестрация.
-
Вы уже используете API OpenAI и хотите путь обновления до передовых технологий.
-
Ваш рабочий процесс сочетает текст, код, структурированные данные и, возможно, мультимодальные входные данные.
-
Вы хотите, чтобы модель координировала специализированные подзадачи.
-
Вы цените интеграцию в экосистему и скорость развития продукта.
Выберите Claude Opus 4.7, когда:
-
Вам нужна тщательное чтение длинного контекста и анализ документов.
-
Вы много работаете с кодовой базой, рефакторингом и сложными инженерными задачами.
-
Вы цените осторожное рассуждение и раскрытие отсутствующих данных.
-
Вы используете интеграции Claude Code или GitHub Copilot, которые поддерживают Opus 4.7.
-
Вы хотите слегка более низкую цену за выходные токены по указанным ставкам.
Используйте оба, когда:
-
Задача достаточно ценна, чтобы оправдать перекрёстную проверку моделей.
-
Вам нужна одна модель для генерации, а другая — для критики.
-
Вы строите промышленную платформу ИИ с маршрутизацией моделей.
-
Вы хотите сократить риск отказов, зависящих от одной модели.
-
Вам важны и креативность, и осторожность.
Самые продвинутые команды не будут спрашивать «какая модель лучше?» Они спросят «какая модель должна выполнять какой шаг?» Это правильный вопрос на 2026 год. ИИ стал слишком важен, чтобы рассматривать выбор модели как предпочтение бренда.
Итоговый вердикт: GPT-5.6 Sol Ultra или Claude Opus 4.7?

Если вам нужен самый простой ответ, он таков: Claude Opus 4.7 сегодня представляет собой более безопасный выбор для аккуратного кодирования, исследований с длинным контекстом и дисциплинированных профессиональных рабочих процессов, в то время как GPT-5.6 Sol Ultra является стратегически более захватывающим выбором для агентной оркестрации и систем ИИ, нативных для OpenAI.
У Claude Opus 4.7 сейчас больше публичной подтверждённости. Anthropic опубликовала официальные цены и доступность. GitHub обсуждал его развёртывание в Copilot. Отзывы ранних тестировщиков выделяют именно те возможности, которые важны для реальной работы: многошаговое выполнение, меньше ошибок при работе с инструментами, более сильное планирование и лучшая работа с длинным контекстом. Если вашей команде сегодня нужна модель для рабочих процессов по кодированию и исследованиям, Claude Opus 4.7 заслуживает серьёзной оценки.
GPT-5.6 Sol Ultra сложнее оценить с уверенностью, потому что независимое покрытие бенчмарков пока ограничено. Но его направление важно. Сочетание флагманских возможностей рассуждения, режима Max, режима Ultra и оркестрации подагентов указывает на то, куда движется ИИ: от ответов на вопросы к координации работы. Если OpenAI успешно реализует это, GPT-5.6 Sol Ultra может стать одной из самых важных моделей для продуктов, ориентированных на агентов.
Реальным победителем может оказаться не одна модель. Победителем станет слой рабочих процессов, который использует правильную модель в нужный момент. В кодировании это означает агентов, которые могут читать, исправлять, тестировать и объяснять. В исследованиях — системы, которые могут собирать, проверять, обсуждать и мониторить. В инвестировании — платформы, превращающие рыночные данные в структурированную аналитику.
Сопоставление GPT-5.6 Sol Ultra и Claude Opus 4.7 — это, следовательно, не просто сравнение моделей. Это превью следующей войны платформ ИИ. Будущее будет принадлежать системам, которые сочетают рассуждение, инструменты, память, верификацию и дизайн рабочих процессов. Самый умный чат-бот не победит. Победит самый полезный работник ИИ.
Часто задаваемые вопросы: GPT-5.6 Sol Ultra против Claude Opus 4.7
Является ли GPT-5.6 Sol Ultra лучше, чем Claude Opus 4.7?
Не универсально. GPT-5.6 Sol Ultra, по-видимому, больше ориентирован на агентную оркестровку и рабочие процессы, нативные для OpenAI, тогда как Claude Opus 4.7 имеет более убедительные публичные доказательства в пользу аккуратного кодирования, работы с длинным контекстом и надёжного многошагового выполнения. Выбор лучшей модели зависит от вашего случая использования.
Какая модель лучше для программирования?
В настоящее время у Claude Opus 4.7 более высокая публичная репутация в области кодирования, поскольку Anthropic и GitHub оба отметили её производительность в задачах программирования и агентных рабочих процессах для разработчиков. GPT-5.6 Sol Ultra может стать очень конкурентоспособной в системах агентного кодирования, особенно если режим Ultra улучшит оркестрацию подагентов.
Какая модель дешевле?
По публичным ценам обе модели указаны по $5 за миллион входных токенов. Claude Opus 4.7 указан по $25 за миллион выходных токенов, тогда как в публичных сообщениях GPT-5.6 Sol указан по $30 за миллион выходных токенов. Реальная стоимость зависит от количества повторных попыток, длины вывода, использования инструментов, кэширования и процента успешности рабочего процесса.
Какая модель лучше для агентов ИИ?
GPT-5.6 Sol Ultra может быть более интересна для оркестрации агентов, поскольку режим Ultra описывается с акцентом на подагентов. Claude Opus 4.7 может быть лучше для надёжного длительного выполнения агентных задач, особенно в рабочих процессах, связанных с кодированием и большими объёмами документов. Для дорогостоящих сценариев использования лучше всего может быть сочетание обеих моделей через роутер моделей.
Какую модель должны выбирать стартапы?
Стартапам следует выбирать, исходя из экономики рабочих процессов. Если продукт зависит от интеграции с экосистемой OpenAI и мультиагентной оркестрации, протестируйте GPT-5.6 Sol Ultra. Если продукт опирается на рассуждения в длинном контексте, надёжность при кодировании и аккуратный анализ, протестируйте Claude Opus 4.7. В продакшне распределяйте задачи в соответствии с сильными сторонами моделей, а не используйте одну модель для всего.
Какая модель лучше для инвестиционных исследований?
Claude Opus 4.7 может быть сильнее при чтении длинных отчётов и подготовке осторожного анализа. GPT-5.6 Sol Ultra может быть лучше для мультиагентных исследовательских рабочих процессов, которые собирают новости, сравнивают финансовые данные, обсуждают риски и отслеживают изменения инвестиционных тезисов. Лучшие системы для инвестиционных исследований, вероятно, будут сочетать несколько моделей и специализированных агентов.