
GPT-5.6 Sol Ultra und Claude Opus 4.7 repräsentieren zwei unterschiedliche Visionen von Spitzen-KI. Die eine ist auf agentische Orchestrierung, tiefe Denkmodi und OpenAIs wachsendes Produkt-Ökosystem ausgerichtet. Die andere basiert auf sorgfältiger Ausführung, Arbeit mit langen Kontexten, Zuverlässigkeit beim Programmieren und unternehmensgerechter Workflow-Disziplin. Die eigentliche Frage lautet nicht mehr einfach „Welches Modell ist klüger?“, sondern „Welches Modell passt zu der Art, wie Sie tatsächlich arbeiten?“
Das Rennen der KI-Modelle hat sich verändert. Vor einem Jahr konzentrierten sich die meisten Modellvergleiche auf die Antwortqualität: Welches Modell schrieb den besten Essay, löste das schwerste Rätsel, fasste das längste PDF zusammen oder erzeugte den saubersten Codeausschnitt. Das ist weiterhin wichtig, aber nicht mehr ausreichend. 2026 verschiebt sich die Grenze hin zu KI-Systemen, die planen können, Werkzeuge nutzen, Kontext verwalten, sich von Fehlern erholen und bei mehrstufigen Zielen weiterarbeiten können. Das wertvollste Modell ist nicht immer dasjenige, das die eindrucksvollste Einzelantwort liefert. Oft ist es das Modell, das den nützlichsten Workflow mit dem geringsten Reibungsverlust abschließt.
Deshalb ist der Vergleich zwischen GPT-5.6 Sol Ultra und Claude Opus 4.7 interessant. Diese Modelle sind nicht nur Chatbot-Upgrades. Sie sind Kandidaten dafür, die Intelligenzschicht hinter Software-Engineering-Agenten, Forschungs-Copiloten, Finanzanalysesystemen, Unternehmensautomatisierungen und Entscheidungsunterstützungs-Workflows zu werden. Für Entwickler stellt sich die Frage, ob GPT-5.6 Sol Ultra oder Claude Opus 4.7 besser zum Coden, Debuggen, zur Architektur und zur agentischen Ausführung geeignet ist. Für Unternehmen lautet die Frage, welches Modell das bessere Preis-Leistungs-Verhältnis bietet. Für Investoren und Analysten lautet die Frage, welches Modell laute Informationen in strukturierte Erkenntnisse verwandeln kann.
Dieser Artikel vergleicht die beiden Modelle anhand öffentlicher Informationen, Preisgestaltung, Anwendungsfälle beim Programmieren, Denkverhalten, Benchmark-Kontext, Entwickler-Workflows, KI-Agenten-Performance und reale Forschungsszenarien. Wo verlässliche öffentliche Zahlen existieren, nutzen wir sie. Wo die unabhängige Benchmark-Berichterstattung noch begrenzt ist, insbesondere für GPT-5.6 Sol Ultra während seiner frühen Preview-Phase, vermeiden wir es, so zu tun, als seien exakte Ranglisten bereits festgelegt. Ein guter KI-Vergleich sollte Menschen helfen, bessere Entscheidungen zu treffen, und keine falsche Gewissheit erzeugen.
Wichtiger Hinweis zu den Quellen: GPT-5.6 Sol Ultra befindet sich noch in einer frühen Phase des öffentlichen Zyklus. Die nützlichsten öffentlichen Berichte beschreiben GPT-5.6 als ein begrenztes Preview-Modell-Set mit Sol als Flaggschiff sowie Max- und Ultra-Modi für tieferes Denken und Sub-Agenten-Orchestrierung. Für Claude Opus 4.7 liegen von Anthropic direktere offizielle Informationen vor, einschließlich API-Verfügbarkeit, Preisgestaltung und Tester-Feedback. Dieser Vergleich trennt daher bestätigte Daten von praktischer Interpretation.
Das KI-Rennen hat sich verändert: Von Chatbots zu intelligenten Agenten

Der einfachste Weg, GPT-5.6 Sol Ultra und Claude Opus 4.7 misszuverstehen, ist, den Vergleich wie einen einfachen Chatbot-Wettbewerb zu behandeln. Diese Einordnung ist veraltet. Die besten Modelle konkurrieren nicht mehr nur darum, wer einen besseren Absatz schreiben oder eine Triviafrage beantworten kann. Sie konkurrieren darum, ob sie als intelligente Arbeitskräfte innerhalb eines größeren Systems agieren können.
In der Chatbot-Ära erledigte der Nutzer den Großteil der Arbeit. Der Nutzer zerlegte das Problem in Teile, schrieb sorgfältige Prompts, kopierte Ausgaben in andere Werkzeuge, überprüfte Fehler manuell, stellte Nachfragen und setzte die finale Antwort zusammen. Das Modell war leistungsfähig, aber passiv. Es wartete auf Anweisungen.
In der Agenten-Ära wird erwartet, dass das Modell mehr Koordination übernimmt. Es sollte das Ziel verstehen, die Schritte planen, Belege sammeln, Werkzeuge nutzen, Code schreiben oder ändern, das Ergebnis testen, Fehler analysieren, seinen Ansatz überarbeiten und eine entscheidungsbereite Ausgabe liefern. Das bedeutet nicht, dass KI im magischen Sinne autonom ist. Es bedeutet, dass sich die Einheit des Mehrwerts von einer einzelnen Antwort zu einem abgeschlossenen Workflow verschiebt.
GPT-5.6 Sol Ultra scheint für diesen Wandel konzipiert zu sein. Öffentliche Berichte beschreiben Sol als OpenAIs Flaggschiff der GPT-5.6-Reihe mit Stärken in Programmierung, Cybersicherheit, Biologie und langfristigen agentischen Aufgaben. Der Ultra-Modus ist besonders bemerkenswert, weil er angeblich Subagenten nutzt. Diese Einordnung ist wichtig. Die Orchestrierung von Subagenten deutet auf ein Modell hin, das nicht nur in einem Strom denkt, sondern Arbeit über spezialisierte interne oder externe Prozesse verteilt.
Claude Opus 4.7 kommt aus einer anderen, aber ebenso wichtigen Richtung. Die öffentlichen Materialien von Anthropic betonen komplexe mehrstufige Workflows, Programmierung, Werkzeugnutzung, lange laufende Aufgaben, Daten-Disziplin, Befolgung von Anweisungen und Konsistenz. Zitate früher Tester hoben die Fähigkeit von Claude Opus 4.7 hervor, logische Fehler während der Planung zu erkennen, trotz Werkzeugausfällen weiterzumachen und plausible, aber nicht gestützte Rückgriffe zu vermeiden. Das ist nicht nur „besseres Schreiben“. Das ist Workflow-Zuverlässigkeit.
Das schafft den zentralen Gegensatz: GPT-5.6 Sol Ultra wirkt wie ein Modell, das für Orchestrierung und Agenten-Ökosysteme optimiert ist, während Claude Opus 4.7 wie ein Modell wirkt, das für sorgfältige, zuverlässige Ausführung über lange und komplexe Aufgaben optimiert ist. Der Gewinner hängt davon ab, ob Ihr Anwendungsfall breite Ökosystemintegration und agentische Flexibilität oder Konsistenz über lange Kontexte und konservative Präzision wertschätzt.
GPT-5.6 Sol Ultra vs Claude Opus 4.7: Kurzer Vergleich
Bevor wir in Benchmarks und Workflows eintauchen, hier der Überblick. Diese Tabelle soll keinen universellen Sieger verkünden. Sie soll verdeutlichen, in welchen Bereichen jedes Modell nach aktuellen öffentlichen Informationen und praktischen Nutzungsmustern am stärksten erscheint.
Category GPT-5.6 Sol Ultra Claude Opus 4.7 Kernpositionierung Flaggschiff OpenAI-Modellsuite-Variante, die sich auf fortgeschrittenes Schlussfolgern, Programmierung und agentenbasierte Workflows konzentriert, wobei der Ultra-Modus um Sub-Agenten-Orchestrierung beschrieben wird. Anthropic Frontier-Opus-Modell, das sich auf Programmierung, Arbeiten mit langen Kontexten, komplexe Aufgaben, konstante Ausführung und sorgfältiges Befolgen von Anweisungen fokussiert. Beste Einsatzgebiete: agentenbasierte Workflows, OpenAI-Ökosystem-Apps, Tool-Orchestrierung, automatisierte Recherche, multimodale und produktisierte KI-Erfahrungen. Lange Dokumente, komplexe Programmieraufgaben, sorgfältige Analysen, Enterprise-Engineering-Workflows, Claude Code und strukturiertes Schlussfolgern. Programmierung: Starker Kandidat für agentenbasierte Programmierung und automatisiertes Debugging, besonders dort, wo OpenAI-Tooling zentral ist. Sehr starke öffentliche Positionierung im Bereich Programmierung und langlaufende Softwareaufgaben; verfügbar in Claude Code- und GitHub Copilot-Integrationen. Preisgestaltung: Öffentliche Berichte listen GPT-5.6 Sol während der Preview-Phase mit 5 $ pro Million Input-Token und 30 $ pro Million Output-Token. Anthropic gibt an, dass Claude Opus 4.7 weiterhin 5 $ pro Million Input-Token und 25 $ pro Million Output-Token kostet. Benchmark-Sicherheit: Unabhängige öffentliche Benchmark-Daten sind aufgrund des frühen Preview-Zyklus noch begrenzt. Es gibt mehr öffentliches Feedback aus dem Ökosystem und offizielle Aussagen von Anthropic; die unabhängige Benchmark-Abdeckung variiert je nach Test. Agentenfähigkeiten: Potenziell stärker bei Sub-Agenten-Orchestrierung und breiten KI-Produktworkflows. Potenziell stärker bei verlässlicher, langlaufender Ausführung und tool-abhängigen Workflows. Praktische Empfehlung: Wählen Sie es, wenn Sie ein OpenAI‑nativen Agentensystem, breite Ökosystemintegration und hochentwickelte Reasoning-Modi wünschen. Wählen Sie es, wenn Sie disziplinierte Programmierung, Dokumenten-Reasoning, Zuverlässigkeit bei langen Kontexten und sorgfältige Ausgaben benötigen.
Modellphilosophie: OpenAI Sol Ultra vs. Anthropic Opus
OpenAI und Anthropic verfolgen unterschiedliche Produktphilosophien, und diese Unterschiede zeigen sich im Verhalten der Modelle. Die Frontier-Modelle von OpenAI wirken zunehmend wie Komponenten eines wachsenden KI-Betriebssystems: ChatGPT, API-Workflows, multimodale Eingaben, Tool-Nutzung, Programmierumgebungen, Unternehmensintegrationen und agentenbasierte Produktoberflächen. Das Modell ist nicht nur ein Gehirn. Es ist Teil eines Systems, das mehr von der Arbeit des Nutzers von Anfang bis Ende übernehmen möchte.
GPT-5.6 Sol Ultra passt zu dieser Richtung. Das „Sol“-Branding deutet auf die Flaggschiff-Stufe hin, während „Ultra“ den leistungsfähigsten Modus für komplexe Aufgaben nahelegt. Der Schlüsselbegriff ist Sub-Agenten-Orchestrierung. Praktisch gesehen beginnen die fortschrittlichsten KI-Systeme weniger wie ein einziger großer Antwortgenerator auszusehen und mehr wie ein Koordinator spezialisierter Arbeiter. Ein Agent kann Quellcode prüfen. Ein anderer kann Dokumentation durchsuchen. Ein weiterer kann Sicherheitsimplikationen bewerten. Wieder ein anderer kann Abwägungen zusammenfassen. Das Hauptmodell koordiniert diese Bemühungen zu einem Endergebnis.
Anthropics Opus-Philosophie erscheint stärker auf verlässliche Intelligenz ausgerichtet. Claude ist seit langem für hohe Schreibleistung, Verständnis langer Kontexte und einen vorsichtigen Stil bekannt. Claude Opus 4.7 setzt dieses Muster in professionelle Arbeitskontexte fort. Anthropics Ankündigung betonte Test-Feedback aus Unternehmen aus den Bereichen Programmierung, Daten, Forschung und Workflows. Die Sprache drehte sich weniger um spektakuläre Demos und mehr um weniger Tool-Fehler, bessere Planung, stärkere Leistung bei langlaufenden Aufgaben und klarere Hinweise, wenn Daten fehlen.
Dieser Unterschied ist wichtig, weil viele Ausfälle von KI im Produktivbetrieb nicht durch mangelnde rohe Intelligenz verursacht werden. Sie werden durch schlechtes Workflow-Verhalten verursacht. Das Modell erfindet fehlende Informationen. Es bricht zu früh ab. Es versagt stillschweigend. Es folgt der falschen Instruktionshierarchie. Es verwendet Werkzeuge falsch. Es ändert die Aufgabe, ohne zu erklären, warum. Es liefert beeindruckende Ausgaben, die tatsächlich nicht auf den verfügbaren Beweisen basieren. Die Kommunikation von Anthropic rund um Claude Opus 4.7 zielt direkt auf diese Produktionsprobleme.
Die praktische Schlussfolgerung ist einfach: GPT-5.6 Sol Ultra könnte für Entwickler spannender sein, die möchten, dass KI-Systeme mehrere Aufgaben koordinieren und sich tief in ein Produkt-Ökosystem integrieren. Claude Opus 4.7 könnte für Teams attraktiver sein, die sorgfältige Ausführung, starke Kontextverwaltung und weniger überraschende Schlussfolgerungen in langen professionellen Workflows benötigen.
Benchmark-Vergleich: Welches KI-Modell ist klüger?

Benchmarks sind nützlich, aber nur, wenn sie richtig interpretiert werden. Eine Platzierungszahl in einem Leaderboard ist nicht dasselbe wie die Eignung für ein Produkt. Ein Modell kann in einem Benchmark gut abschneiden und in einem realen Workflow dennoch frustrierend sein. Ein anderes Modell kann in einem synthetischen Test etwas zurückliegen, aber besser darin sein, Anweisungen zu befolgen, Werkzeuge zu nutzen oder den Kontext über eine lange Aufgabe hinweg aufrechtzuerhalten.
Für GPT-5.6 Sol Ultra ist die ehrliche Benchmark-Lage so, dass unabhängige öffentliche Ergebnisse noch begrenzt sind. Da das Modell in einem eingeschränkten Preview-Kontext eingeführt wurde, hat sich eine breite Drittanbieter-Benchmark-Abdeckung noch nicht stabilisiert. Das bedeutet, dass jeder Artikel, der genaue universelle Ranglisten für GPT-5.6 Sol Ultra über alle Benchmarks hinweg behauptet, mit Vorsicht zu behandeln ist, es sei denn, er verweist auf ein echtes öffentliches Leaderboard oder eine offizielle Evaluierungsveröffentlichung.
Für Claude Opus 4.7 gibt es mehr öffentliches Material. Die eigene Ankündigung von Anthropic enthält frühes Tester-Feedback zu Kodierung, Research-Agent-Aufgaben, Datenanalyse und mehrstufigen Workflows. GitHub hat zudem angekündigt, dass Claude Opus 4.7 in GitHub Copilot ausgerollt wird, wobei frühe Tests auf bessere Leistungen bei mehrstufigen Aufgaben und eine zuverlässigere agentische Ausführung hinweisen. Das sind nicht dasselbe wie neutrale akademische Benchmarks, aber sie sind aussagekräftig, weil sie aus Entwickler-Produkt-Kontexten stammen, in denen reale Workflows entscheidend sind.
Unabhängige Benchmark-Seiten wie SWE-bench und Artificial Analysis sind wichtig, weil sie externen Kontext liefern. SWE-bench konzentriert sich auf echte Software-Engineering-Probleme, einschließlich einer von Menschen gefilterten 'Verified'-Teilmenge. Artificial Analysis vergleicht Modelle in Bezug auf Intelligenz, Geschwindigkeit, Preis, ausgegebene Token und Metriken im Stil von Kosten pro Aufgabe. Diese Plattformen sind wertvoll, weil sie helfen, Marketing-Aussagen von messbarem Verhalten zu trennen. Sie erfordern jedoch auch Vorsicht: Benchmark-Ergebnisse hängen vom Testgerüst, Tool-Zugang, Prompt-Design, Agenten-Framework und den Evaluierungsregeln ab.
Die beste Art, die Benchmark-Landschaft zu lesen, ist nicht "GPT gewinnt" oder "Claude gewinnt". Denken Sie stattdessen in Kategorien:
-
Reasoning-Benchmarks prüfen, ob ein Modell schwierige Probleme lösen kann, spiegeln aber möglicherweise nicht die Nutzung in Produktionswerkzeugen wider.
-
Coding-Benchmarks testen die Reparatur oder Erzeugung von Software, wobei die Ergebnisse stark vom Agentengerüst abhängen.
-
Benchmarks mit langem Kontext prüfen das Abrufen und die Synthese über große Eingaben, aber reale Projekte enthalten unordentliche Dateien, widersprüchliche Anforderungen und unvollständige Informationen.
-
Agenten-Benchmarks kommen der realen Arbeit näher, entwickeln sich aber weiterhin schnell weiter.
-
Kosten-Benchmarks sind wichtig, weil ein Modell, das 5% besser, aber 3x teurer ist, für den Produktionseinsatz schlechter sein kann.
Wenn Sie heute eine strikte Benchmark-Antwort benötigen: Claude Opus 4.7 hat derzeit mehr öffentliche Fundierung, weil Anthropic offizielle Details veröffentlicht hat und Partner im Ökosystem seine Leistung diskutiert haben. GPT-5.6 Sol Ultra besitzt stärkeres strategisches Potenzial in Bezug auf die Orchestrierung von Subagenten, aber unabhängige Validierungen holen noch auf. Diese Lücke kann sich schnell schließen, sobald die Vorschau erweitert wird.
Code-Vergleich: GPT-5.6 Sol Ultra vs Claude Opus 4.7 für Entwickler

Coding ist eines der wichtigsten Schlachtfelder für führende Modelle, weil Entwickler zu den wertvollsten KI-Nutzern gehören. Sie verwenden Modelle häufig, bezahlen für Premium-Tools und setzen Modelle in anspruchsvolle reale Aufgaben ein: Refaktorisierung von Legacy-Systemen, Debugging von instabilen Tests, Entwurf von Architektur, Einarbeitung in fremde Codebasen, Schreiben von Migrationen, Generierung von Testfällen und Arbeiten in IDEs.
Claude Opus 4.7 hat heute einen klaren öffentlichen Vorteil in puncto Coding-Glaubwürdigkeit, weil Anthropic und GitHub es beide rund um Software-Engineering-Workflows positioniert haben. Anthropics Ankündigung enthält Feedback von frühen Testern, die eine bessere Planung, weniger Tool-Fehler und stärkere Performance bei komplexen Coding-Workflows beschreiben. Das Changelog von GitHub sagt, dass Opus 4.7 in GitHub Copilot ausgerollt wird und beschreibt Verbesserungen bei Mehrschrittaufgaben, dem Denken über lange Horizonte und werkzeugabhängigen Workflows. Für Entwickler ist das wichtiger als eine einzelne Code-Snippet-Demo.
Der Grund, warum Claude oft im Coding gut abschneidet, liegt nicht nur darin, dass es Code schreibt. Viele Modelle können Code schreiben. Das Schwierige ist, die bestehende Architektur eines Projekts zu verstehen, Stil zu bewahren, Vorgaben einzuhalten, minimale Änderungen vorzunehmen, Fehler zu diagnostizieren und zu wissen, wann man nicht überentwickeln sollte. Claudes vorsichtiger Stil ist hier nützlich. Es neigt dazu, das Problem durchzudenken, Kompromisse zu erklären und zu vermeiden, zu schnell zu einer Lösung zu eilen. In einer großen Codebasis kann diese Vorsicht ein Vorteil sein.
Die Coding-Geschichte von GPT-5.6 Sol Ultra ist anders. Öffentliche Berichte heben hervor, dass GPT-5.6 Sol besonders geschickt im Coding und bei agentenbasierten, langfristigen Aufgaben ist. Wenn der Ultra-Modus die Orchestrierung von Subagenten wirklich verbessert, könnte das Modell in Coding-Workflows sehr stark sein, die paralleles Denken erfordern: Ein Subagent liest Tests, ein anderer inspiziert die Implementierung, ein weiterer durchsucht die Dokumentation, ein anderer schlägt einen Patch vor und ein weiterer validiert Randfälle. Diese Struktur ist hochrelevant für modernes AI-gestütztes Software-Engineering.
Für einen Solo-Entwickler in einer IDE mag sich Claude Opus 4.7 unmittelbar zuverlässiger anfühlen, wenn die Aufgabe darin besteht, einen bestehenden Codebestand zu lesen und zu ändern. Für einen Plattformentwickler, der automatisierte Programmieragenten erstellt, könnte GPT-5.6 Sol Ultra interessanter sein, weil die Architektur in Richtung Orchestrierung weist. Bis jedoch unabhängige Programmier-Benchmarks und reale Entwicklerberichte breiter vorliegen, ist die richtige Schlussfolgerung nicht, dass GPT-5.6 Claude bereits geschlagen hat. Die richtige Schlussfolgerung ist, dass die beiden Modelle möglicherweise für unterschiedliche Programmier-Workflows optimiert sind.
Wo Claude Opus 4.7 beim Programmieren stärker sein kann
-
Verständnis großer Codebasen mit vielen Einschränkungen.
-
Befolgung detaillierter Anweisungen über lange Sitzungen hinweg.
-
Erklärung von Kompromissen und Vermeidung unbelegter Annahmen.
-
Arbeiten innerhalb von Claude Code- und GitHub Copilot-Integrationen.
-
Komplexes Refactoring, bei dem sorgfältiges Kontextmanagement wichtig ist.
Wo GPT-5.6 Sol Ultra beim Programmieren stärker sein kann
-
Agentische Codingsysteme, die mehrere Werkzeuge und Subagenten nutzen.
-
Automatisierte Workflows, die Planungs-, Ausführungs- und Validierungsschleifen erfordern.
-
OpenAI-native Entwicklerprodukte und API-basierte Coding-Agenten.
-
Aufgaben, die Code, Dokumente, Logs, Screenshots und multimodalen Kontext kombinieren.
-
Schnelle Iteration innerhalb größerer KI-Produktökosysteme.
Wenn Ihre Frage lautet „Welches Modell sollte ich in Cursor, Claude Code, Copilot oder einem internen Coding-Agenten verwenden?“, lautet die Antwort: Testen Sie beide an Ihrem realen Repository. Verwenden Sie fünf Aufgaben: eine Fehlerbehebung, ein Refactoring, ein Feature, eine Testgenerierungsaufgabe und eine Architektur-Erklärung. Messen Sie nicht nur, ob der Code kompiliert, sondern wie viele Interaktionsschritte es braucht, wie viele Dateien betroffen sind, ob Stilvorgaben eingehalten werden und ob es APIs erfindet. Das wird Ihnen mehr sagen als eine Bestenliste.
Schlussfolgerungsvermögen: Tiefes Denken vs. praktische Intelligenz
Schlussfolgerungsvermögen ist das im KI-Marketing am meisten überstrapazierte Wort. Jedes Frontier-Modell behauptet besseres Schlussfolgern zu leisten. Die nützlichere Frage ist: Welche Art von Schlussfolgerungen kann das Modell gut durchführen?
Die Reasoning-Story von GPT-5.6 Sol Ultra hängt mit Modi zusammen. Öffentliche Berichte besagen, dass Sol einen Max-Modus für tieferes Schlussfolgern und einen Ultra-Modus für die Orchestrierung von Subagenten enthält. Das impliziert ein Modell, das darauf ausgelegt ist, für schwierige Aufgaben mehr Rechenkapazität und strukturierte Verfahren einzusetzen. Für Nutzer kann sich das als bessere Planung, stärkere Zerlegung, verbesserte Tool-Koordination und weniger oberflächliche Antworten bei schwierigen Problemen bemerkbar machen.
Die Reasoning-Story von Claude Opus 4.7 ist mit Disziplin verknüpft. Anthropics öffentliche Beispiele betonen das Erkennen logischer Fehler während der Planung, das korrekte Melden fehlender Daten, das Nichtauf-Fallen-in-Fallen und das Fortfahren trotz Ausfällen von Tools. Diese Art von Schlussfolgern ist in der professionellen Arbeit äußerst wertvoll. Es geht nicht nur darum, ein Puzzle zu lösen. Es geht darum zu wissen, welche Beweise vorliegen, was fehlt, was daraus geschlossen werden kann und was nicht behauptet werden sollte.
Apply this research method to your stock
Generate bull/bear views, risk notes, and an evidence trail for GPT.
Für einen Nutzer kann sich der Unterschied so anfühlen: GPT-5.6 Sol Ultra verhält sich eher wie ein dynamischer Stratege, der einen komplexen Workflow koordinieren kann, während Claude Opus 4.7 eher wie ein vorsichtiger Senior-Analyst agiert, der vor schwachen Annahmen schützt. Beide Stile sind nützlich. Welches Modell das beste ist, hängt von den Kosten eines Fehlers ab.
Wenn Sie eine Produktstrategie entwerfen, einen Workflow für KI-Agenten aufbauen oder schnell mehrere Optionen generieren, könnte GPT-5.6 Sol Ultra die leistungsfähigere kreative Engine sein. Wenn Sie dagegen einen Vertrag prüfen, einen langen Finanzbericht analysieren, eine Datenpipeline validieren oder einen Produktionsvorfall untersuchen, kann die Vorsicht von Claude Opus 4.7 wertvoller sein.
Die tiefsten Denk- und Schlussfolgerungssysteme werden schließlich beide Stile kombinieren: mutige Zerlegung plus konservative Verifikation. Deshalb sind Agenten-Workflows wichtig. Ein gutes KI-System sollte nicht von einer einzigen Modellpersönlichkeit abhängen. Es sollte ein Modell nutzen, um Hypothesen zu erzeugen, ein anderes, um sie herauszufordern, ein weiteres, um Quellen zu verifizieren, und ein weiteres, um das Ergebnis in eine umsetzbare Entscheidung zu überführen. Das ist besonders wichtig in der Finanzforschung, wo selbstbewusste, aber nicht fundierte Schlussfolgerungen teuer sein können.
Langer Kontext und Dokumentenarbeit
Langer Kontext ist eine der stärksten Markenassoziationen von Claude. Claude-Modelle werden häufig zum Lesen von Dokumenten, Verträgen, Codebasen, Forschungsarbeiten und Geschäftsberichten eingesetzt. Claude Opus 4.7 setzt dieses Muster fort, indem es Konsistenz über lange Kontexte und professionelle Wissensarbeit betont. Anthropics Ankündigung enthält Tester-Feedback, das Daten-Disziplin, die Offenlegung fehlender Daten und starke Langkontext-Leistung lobt.
Langer Kontext ist nicht nur die Größe des Fensters. Ein Kontextfenster mit einer Million Token klingt beeindruckend, aber entscheidend ist, ob das Modell den Kontext korrekt nutzt. Kann es die relevanten Details finden? Kann es vermeiden, sich von irrelevanten Texten ablenken zu lassen? Kann es widersprüchliche Quellen in Einklang bringen? Kann es dem Nutzer sagen, wenn die Antwort nicht vorhanden ist? Kann es Einschränkungen vom Beginn bis zum Ende der Aufgabe erhalten?
Claude Opus 4.7 scheint besonders gut für Aufgaben geeignet zu sein, bei denen die Eingabe lang, unordentlich und wichtig ist. Beispiele sind Rechtsprüfungen, Politikanalysen, Investment-Memos, technische Dokumentationen, Wissensdatenbanken des Kundensupports, Due-Diligence-Akten, Compliance-Handbücher und große Code-Repositorien. In diesen Situationen können Halluzinationskontrolle und Kontextdisziplin wichtiger sein als Geschwindigkeit.
GPT-5.6 Sol Ultra kann dann überzeugender sein, wenn langer Kontext Teil eines breiteren Workflows ist. Anstatt nur einen langen Bericht zu lesen, könnte ein agentisches System den Bericht zusammenfassen, Schlüsselkennzahlen extrahieren, diese mit Marktdaten vergleichen, aktuelle Nachrichten überprüfen, Investment-Hypothesen generieren, Risikofaktoren diskutieren und eine finale These ausarbeiten. Wenn die Orchestrierung von Subagenten im Ultra-Modus gut funktioniert, könnte GPT-5.6 in diesem mehrstufigen, multiquellenbasierten Workflow sehr leistungsfähig sein.
Die Unterscheidung lautet also nicht „Claude für langen Kontext, GPT für alles andere.“ Präziser ist: Claude Opus 4.7 könnte stärker sein für sorgfältiges Lesen über lange Kontexte und fundierte Synthese, während GPT-5.6 Sol Ultra stärker sein könnte für Langkontext-Workflows, die Orchestrierung, Werkzeugnutzung und mehrstufige Ausführung erfordern.
KI-Agentenleistung: Der eigentliche Unterschied
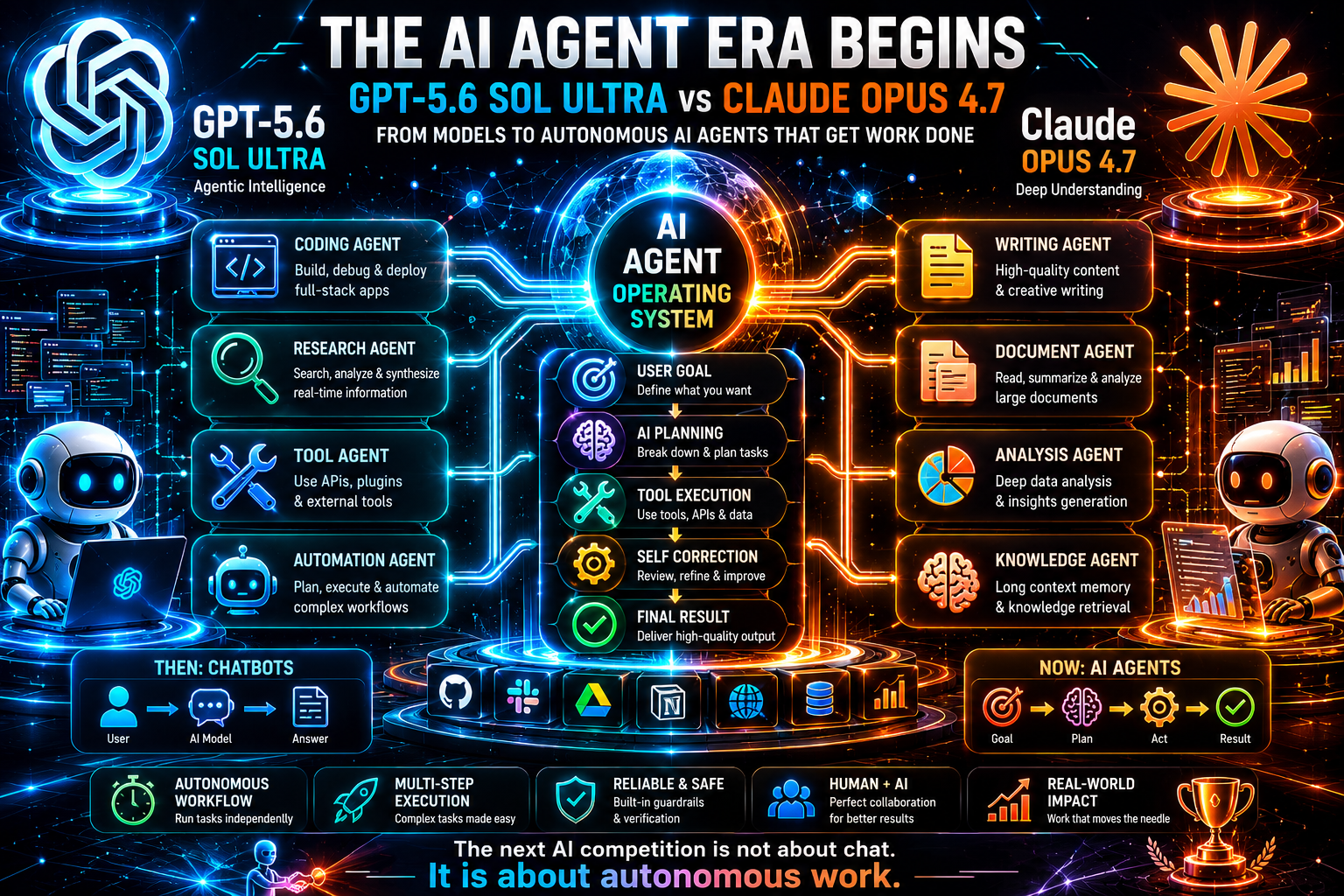
Die wichtigste Kategorie in diesem Vergleich ist die Leistung von KI‑Agenten. Darin geht der Markt. Chatbots sind nützlich, aber bei Agenten werden Produktivitätsgewinne messbar. Ein KI‑Agent kann ein Ziel übernehmen, Schritte planen, Tools aufrufen, APIs nutzen, Ausgaben prüfen, seinen Plan überarbeiten und weitermachen, bis eine Aufgabe abgeschlossen ist oder eine menschliche Entscheidung erforderlich ist.
Die stärkste Erzählung von GPT-5.6 Sol Ultra ist agentische Orchestrierung. Die Ultra‑Modus‑Beschreibung deutet auf Sub‑Agenten hin, eines der wichtigsten Muster im Design fortgeschrittener KI‑Systeme. Ein einzelner Modellaufruf kann mächtig sein, aber komplexe Arbeit profitiert von spezialisierten Rollen: Forscher, Kritiker, Entwickler, Tester, Risikoanalyst, Zusammenfasser und Entscheidungsagent. Wenn GPT-5.6 Sol Ultra für diese Struktur optimiert ist, könnte es zur starken Grundlage für KI‑Produkte der nächsten Generation werden.
Die stärkste Erzählung von Claude Opus 4.7 ist agentische Zuverlässigkeit. Anthropic und GitHub betonen beide die Ausführung mehrstufiger Aufgaben, lang andauernde Arbeiten, toolabhängige Workflows und weniger Ausfälle. In der Produktion ist Zuverlässigkeit oft wertvoller als bloßer Ehrgeiz. Ein Agent, der zu viel versucht und stillschweigend versagt, ist gefährlich. Ein Agent, der vorsichtig vorgeht, Unsicherheiten meldet und sich von Tool‑Fehlern erholt, ist leichter zu vertrauen.
Das schafft für Entwickler eine nützliche Unterscheidung:
-
Verwenden Sie GPT-5.6 Sol Ultra wenn der Agent breite Orchestrierung, mehrere spezialisierte Schritte und Integration in OpenAI‑native Workflows benötigt.
-
Verwenden Sie Claude Opus 4.7 wenn der Agent sorgfältige Kontextbehandlung, länger andauernde Codier‑ oder Rechercheaufgaben und zuverlässige Ausführung unter komplexen Einschränkungen benötigt.
-
Beide verwenden wenn die Aufgabe einen hohen Wert hat: Ein Modell kann generieren und planen, während das andere kritisiert, verifiziert oder umschreibt.
Die Zukunft der KI‑Agenten wird nicht darin bestehen, dass ein Modell alle anderen Modelle ersetzt. Es wird intelligentes Routing sein. Eine Plattform wird das beste Modell für jede Phase des Workflows wählen. Sie könnte ein günstigeres Modell für Klassifikation, ein schnelles Modell für Extraktion, Claude für die Analyse langer Dokumente, GPT für Orchestrierung und ein spezialisiertes Codiermodell für Repository‑Änderungen verwenden. Das erfolgreiche Produkt wird nicht einfach das mit dem größten Modell sein. Es wird das Produkt mit dem besten Workflow‑Design sein.
Preisvergleich: Welches Modell bietet besseren Wert?

Preisgestaltung ist der Punkt, an dem der Vergleich konkret wird. Basierend auf öffentlichen Angaben wird GPT-5.6 Sol mit 5 $ pro Million Eingabe‑Tokens und 30 $ pro Million Ausgabe‑Tokens bepreist. Anthropic gibt an, dass Claude Opus 4.7 mit 5 $ pro Million Eingabe‑Tokens und 25 $ pro Million Ausgabe‑Tokens bepreist ist. Das macht Claude Opus 4.7 bei Ausgabe‑Tokens günstiger, sofern diese Zahlen die Grundlage Ihrer Bereitstellungspreise sind.
Modell Eingabepreis Ausgabepreis Preisfazit GPT-5.6 Sol $5 / 1M Tokens $30 / 1M Tokens Gleicher Eingabepreis wie Opus 4.7, höherer Ausgabepreis basierend auf aktuellen öffentlichen Angaben. Claude Opus 4.7 $5 / 1M Tokens $25 / 1M Tokens Niedrigerer Ausgabepreis, gute Eignung für längere Codier‑ und Dokumenten‑Workflows, wenn der Token‑Einsatz kontrolliert wird.
Der Tokenpreis allein bestimmt jedoch nicht die tatsächlichen Kosten. Die realen Kosten hängen von der Ausgabelänge, der Kontextgröße, dem Prompt‑Caching, der Wiederholungsrate, Tool‑Aufrufen, der Latenz und davon ab, wie oft das Modell die Antwort beim ersten Mal korrekt liefert. Ein günstigeren Modell kann teuer werden, wenn es viele Wiederholungen erfordert. Ein teureres Modell kann günstiger sein, wenn es die Aufgabe mit weniger Aufrufen abschließt. Bei Coding‑Agenten ist der größte Kostenfaktor oft nicht der initiale Prompt. Es ist die iterative Schleife: Dateien inspizieren, Änderungen vorschlagen, Tests ausführen, Fehler lesen, überarbeiten und wiederholen.
Business Insider berichtete, dass Anthropic seine Schätzungen zum Token‑Verbrauch von Claude Code aktualisiert habe und angab, die durchschnittlichen Kosten für Unternehmensentwickler lägen bei etwa 13 US‑Dollar pro aktivem Tag und 150 bis 250 US‑Dollar pro Entwickler und Monat, wobei 90 % der Nutzer unter 30 US‑Dollar pro aktivem Tag lägen. Wichtig ist nicht, dass Claude per se teuer sei. Entscheidend ist, dass die Nutzung von KI‑Agenten die Kostenstruktur verändert. Wenn Modelle zu Arbeitern statt zu reinen Antwortmaschinen werden, verbrauchen sie mehr Tokens, weil sie mehr Arbeit leisten.
Für Produktionsteams sollte die Preisfrage als Kosten pro abgeschlossenem Workflow formuliert werden. Zum Beispiel:
-
Wie viel kostet es, ein Support‑Ticket zu lösen?
-
Wie viel kostet es, einen Fehler zu beheben?
-
Wie viel kostet es, ein Investment‑Briefing zu erstellen?
-
Wie viel kostet es, einen Earnings‑Call zu analysieren?
-
Wie viel kostet es, eine Aktie eine Woche lang zu überwachen?
Sobald Sie die Kosten auf diese Weise messen, kann das beste Modell je nach Aufgabe variieren. Claude Opus 4.7 kann für sorgfältige Ausgaben mit langem Kontext kosteneffizienter sein, weil sein Preis pro Ausgabe‑Token niedriger ist und sein Stil Nacharbeit reduzieren kann. GPT‑5.6 Sol Ultra kann für Workflows kosteneffizienter sein, bei denen Orchestrierung die Zeit menschlicher Koordination reduziert. Die einzige verlässliche Methode, dies herauszufinden, besteht darin, Aufgabenbewertungen auf Ebene einzelner Workflows mit echten Prompts, echten Dateien und echten Erfolgskriterien durchzuführen.
Entwicklererfahrung: Claude Code, GitHub Copilot, APIs und Agent‑Frameworks
Modellqualität ist wichtig, aber die Entwicklererfahrung bestimmt die Akzeptanz. Ein Modell, das etwas besser, aber schwerer zu integrieren ist, kann gegen ein Modell verlieren, das sich nahtlos in bestehende Workflows einfügt. Deshalb sind Claude Code, GitHub Copilot, ChatGPT, API‑Tools und Agent‑Frameworks so wichtig.
Claude Opus 4.7 profitiert davon, in Entwicklerumgebungen integriert zu sein, in denen Nutzer bereits arbeiten. GitHubs Ankündigung, dass Opus 4.7 in Copilot ausgerollt wird, verschafft ihm Verbreitung in einem der wichtigsten Coding‑Produkte der Welt. Claude Code bietet Anthropic außerdem eine direkte Schnittstelle für agentische Softwareentwicklung. Für Entwickler, die einen leistungsfähigen Coding‑Partner statt einer rohen API wollen, ist das wichtig.
GPT‑5.6 Sol Ultra profitiert vom breiteren Ökosystem von OpenAI. ChatGPT bleibt eine weit verbreitete KI‑Schnittstelle, die OpenAI‑API hat eine starke Entwickler‑Mindshare und die Produktstrategie des Unternehmens unterstützt zunehmend Tools, multimodale Workflows und agentische Anwendungen. Wenn Ihr Team bereits auf OpenAI‑APIs aufbaut, kann GPT‑5.6 Sol Ultra als Upgrade‑Pfad leichter zu übernehmen sein.
Die Frage der Entwicklererfahrung sollte Folgendes umfassen:
-
Funktioniert das Modell innerhalb der Tools, die Ihr Team bereits verwendet?
-
Kann es Ihre internen Tools sicher aufrufen?
-
Können Sie die Token-Nutzung und den Erfolg von Workflows überwachen?
-
Können Sie Aufgaben zwischen Modellen weiterleiten?
-
Können Sie Leitplanken für Sicherheit, Datenschutz und Compliance hinzufügen?
-
Kann das Modell erklären, was es getan hat und warum?
Für interne KI-Plattformen kann die beste Lösung ein Modell-Router sein, statt sich auf ein einzelnes Modell festzulegen. Setzen Sie Claude Opus 4.7 für Aufgaben ein, die sorgfältiges Lesen und Argumentieren über lange Kontexte in Codebasen erfordern. Verwenden Sie GPT-5.6 Sol Ultra für planungsintensive, stark toolgestützte Multi-Agenten-Orchestrierung. Nutzen Sie günstigere Modelle für Extraktion, Klassifikation und repetitive Aufgaben. Diese Architektur ist widerstandsfähiger, als alles auf ein einzelnes Spitzemodell zu setzen.
Forschung und Analyse: Welches Modell bewältigt komplexe Informationen besser?
Forschung ist der Bereich, in dem KI-Modelle enorme Hebelwirkung erzeugen können. Ein menschlicher Analyst kann Stunden damit verbringen, Berichte, Einreichungen, Transkripte, Nachrichten, Forendiskussionen, Marktdaten und interne Dokumente zu lesen. Ein gutes KI-Modell kann diesen Prozess komprimieren. Ein schlechtes KI-Forschungssystem kann jedoch selbstbewussten Unsinn produzieren.
Claude Opus 4.7 spricht stark für Forschungstasks wegen seiner Disziplin im Umgang mit langen Kontexten und seiner vorsichtigen Handhabung fehlender Daten. Die Ankündigung von Anthropic enthält Tester-Feedback, das von besserer Offenlegung und Datendisziplin berichtet. Das ist in der Forschung wichtig, weil die gefährlichsten Fehler oft keine offensichtlichen Halluzinationen sind. Es sind subtile, nicht abgesicherte Schlussfolgerungen, die vernünftig klingen.
GPT-5.6 Sol Ultra hat ein starkes Argument für Forschungs-Workflows aufgrund seiner agentischen Ausrichtung. Forschung ist nicht nur Lesen. Es bedeutet, die richtigen Fragen zu stellen, Quellen zu sammeln, Perspektiven zu vergleichen, Widersprüche zu identifizieren, eine These zu aktualisieren und zu entscheiden, worauf als Nächstes geachtet werden sollte. Wenn der Ultra-Modus die Orchestrierung von Unteragenten verbessert, könnte GPT-5.6 besonders nützlich für Forschungssysteme sein, die Arbeit auf mehrere Agenten aufteilen.
Zum Beispiel könnte ein Workflow für Finanzforschung folgende Komponenten umfassen:
-
Ein Nachrichten-Agent, der aktuelle Unternehmensentwicklungen sammelt.
-
Ein Filings-Agent, der Umsätze, Margen, Schulden und Änderungen der Guidance extrahiert.
-
Ein Markt-Agent, der Kursbewegungen, Volumen, Volatilität und Sektorbewegungen prüft.
-
Ein Risiko-Agent, der die optimistische These hinterfragt.
-
Ein Bewertungs-Agent, der Multiples und Annahmen vergleicht.
-
Ein abschließender Synthese-Agent, der ein entscheidungsbereites Briefing erstellt.
Hier könnten sowohl GPT-5.6 Sol Ultra als auch Claude Opus 4.7 wertvoll sein. GPT könnte den Workflow koordinieren. Claude könnte die Beweislage kritisieren. Ein anderes Modell könnte strukturierte Zahlen kostengünstig extrahieren. Das Endprodukt ist keine Chatbot-Antwort. Es ist ein KI-nativer Forschungsprozess.
Warum KI-native Investmentforschung möglich wird
Investmentforschung ist ein perfektes Beispiel dafür, warum das Rennen um KI-Modelle zu einem Rennen um Workflows wird. Investoren brauchen nicht einfach nur Antworten. Sie brauchen strukturiertes Denken unter Unsicherheit. Sie müssen wissen, was sich geändert hat, warum es wichtig ist, welche Belege die These stützen, was falsch sein könnte und welches Signal als Nächstes überwacht werden sollte.
Traditionelle Werkzeuge für die Finanzrecherche sind oft statisch. Sie zeigen Diagramme, Kennzahlen, Schlagzeilen, Analystenbewertungen und Einreichungen. Das ist nützlich, aber es verlangt vom Nutzer, die Zusammenhänge manuell herzustellen. Der Nutzer muss weiterhin entscheiden, welche Informationen wichtig sind, welche Risiken unterbewertet sind, welche Erzählung sich verändert und welcher Datenpunkt dem Konsens widerspricht.
KI‑Agenten können das ändern. Ein Research‑Agent kann Earnings‑Transkripte lesen. Ein Risiko‑Agent kann Annahmen hinterfragen. Ein Bewertungs‑Agent kann Szenarien vergleichen. Ein News‑Agent kann Katalysatoren verfolgen. Ein Überwachungs‑Agent kann nach thesis‑brechenden Ereignissen Ausschau halten. Ein Debatten‑Agent kann Bullen‑ und Bären‑Argumente simulieren. Dabei geht es nicht darum, menschliches Urteilsvermögen zu ersetzen. Es geht darum, menschlichen Anlegern ein besseres Research‑Betriebssystem zu geben.
Genau hier fügen sich Plattformen wie AlphaVue.ai in den breiteren KI‑Wandel ein. Die nächste Generation von Investment‑Plattformen wird nicht einfach nur Daten anzeigen. Sie wird Nutzern helfen, durch Daten hindurch zu denken. Sie wird Marktinformationen in Workflows verwandeln: scannen, recherchieren, debattieren, vergleichen, überwachen und entscheiden. GPT‑5.6 Sol Ultra und Claude Opus 4.7 sind wichtig, nicht weil ein Modell das andere dauerhaft besiegen wird, sondern weil beide zeigen, wie nah der Markt an KI‑nativer Investment‑Intelligenz ist.
Für Anleger lautet die zentrale Frage nicht länger „Kann KI diese Aktie zusammenfassen?“ Das ist schon Standard. Die eigentliche Frage lautet: Kann KI mir helfen zu verstehen, was wichtig ist, was sich geändert hat, was eingepreist ist, was unsicher ist und was als Nächstes zu tun ist? Das erfordert agentenbasierte Workflows, Modell‑Routing, Quellendisziplin und transparente Argumentation. Es erfordert auch Produktgestaltung. Ein leistungsstarkes Modell ohne guten Workflow ist wie ein Bloomberg‑Terminal ohne Suche, ohne Alerts und ohne Struktur.
AlphaVue.ai‑Perspektive: Von KI‑Modellen zu KI‑Investment‑Agenten
Die Zukunft der Finanzforschung wird kein riesiger Chatbot sein. Sie wird ein Netzwerk spezialisierter KI‑Agenten sein, die Unternehmen recherchieren, Marktsignale vergleichen, Bullen‑ und Bärenfälle testen und Anlegern helfen, das Wesentliche zu überwachen. AlphaVue.ai ist für diesen KI‑nativen Investment‑Workflow gebaut: intelligentere Recherche, klarere Entscheidungen und schnellere Erkenntnisse.
Praxisszenarien: Welches Modell sollten Sie wählen?
Es gibt keinen universellen Sieger zwischen GPT‑5.6 Sol Ultra und Claude Opus 4.7. Das richtige Modell hängt von der Aufgabe ab. Hier ist ein praktischer Entscheidungsrahmen.
Wählen Sie GPT‑5.6 Sol Ultra, wenn:
-
Sie KI‑Agenten bauen, die Planung, Werkzeugnutzung und Orchestrierung benötigen.
-
Sie bereits OpenAI‑APIs verwenden und einen Upgrade‑Pfad an die technologische Spitze wünschen.
-
Ihr Workflow Text, Code, strukturierte Daten und möglicherweise multimodale Eingaben kombiniert.
-
Sie möchten, dass das Modell spezialisierte Unteraufgaben koordiniert.
-
Sie Wert auf Integration ins Ökosystem und schnelle Produktentwicklung legen.
Wählen Sie Claude Opus 4.7, wenn:
-
Sie benötigen sorgfältige Langkontext-Lektüre und Dokumentenanalyse.
-
Sie arbeiten intensiv mit Codebasen, Refactoring und komplexen Engineering-Aufgaben.
-
Sie legen Wert auf vorsichtiges Schlussfolgern und die Offenlegung fehlender Daten.
-
Sie verwenden Claude Code oder GitHub Copilot-Integrationen, die Opus 4.7 unterstützen.
-
Sie möchten leicht niedrigere Preise für Output-Tokens basierend auf den aufgeführten Tarifen.
Beide verwenden, wenn:
-
Die Aufgabe ist wertvoll genug, um eine Überprüfung durch mehrere Modelle zu rechtfertigen.
-
Sie benötigen ein Modell zum Generieren und ein anderes zum Kritisieren.
-
Sie bauen eine produktive KI-Plattform mit Modell-Routing.
-
Sie wollen Single-Model-Ausfallmodi reduzieren.
-
Sie achten sowohl auf Kreativität als auch auf Vorsicht.
Die fortschrittlichsten Teams werden nicht fragen „Welches Modell ist das beste?“ Sie werden fragen „Welches Modell sollte welchen Schritt übernehmen?“ Das ist die richtige Frage für 2026. KI ist zu wichtig geworden, um die Modellauswahl als Markenpräferenz zu behandeln.
Endgültiges Urteil: GPT-5.6 Sol Ultra oder Claude Opus 4.7?

Wenn Sie die einfachste Antwort möchten, lautet sie so: Claude Opus 4.7 ist heute die sicherere Wahl für sorgfältiges Codieren, Langkontext-Recherche und disziplinierte professionelle Workflows, während GPT-5.6 Sol Ultra die strategisch spannendere Wahl für agentische Orchestrierung und OpenAI-native KI-Systeme ist.
Claude Opus 4.7 hat derzeit mehr öffentliche Verankerung. Anthropic hat offizielle Preise und Verfügbarkeit veröffentlicht. GitHub hat den Rollout in Copilot thematisiert. Feedback von frühen Testern hebt genau die Fähigkeiten hervor, die für echte Arbeit zählen: mehrstufige Ausführung, weniger Tool-Fehler, stärkere Planung und bessere Langkontext-Leistung. Wenn Ihr Team heute ein Modell für Coding- und Research-Workflows benötigt, sollte Claude Opus 4.7 ernsthaft in Betracht gezogen werden.
GPT-5.6 Sol Ultra ist schwieriger mit Sicherheit zu beurteilen, da unabhängige Benchmark-Abdeckungen noch begrenzt sind. Aber seine Ausrichtung ist wichtig. Die Kombination aus Flaggschiff-Reasoning, Max-Modus, Ultra-Modus und Sub-Agenten-Orchestrierung weist in die Richtung, in die KI geht: vom Beantworten von Fragen hin zur Koordination von Arbeiten. Wenn OpenAI gut liefert, könnte GPT-5.6 Sol Ultra zu einem der wichtigsten Modelle für agenten-native Produkte werden.
Der eigentliche Gewinner ist möglicherweise keines der Modelle allein. Der eigentliche Gewinner ist die Workflow-Ebene, die das richtige Modell zur richtigen Zeit einsetzt. Beim Programmieren bedeutet das Agenten, die lesen, patchen, testen und erklären können. In der Forschung bedeutet das Systeme, die sammeln, verifizieren, debattieren und überwachen können. Im Investmentbereich bedeutet das Plattformen, die Marktdaten in strukturierte Erkenntnisse umwandeln.
GPT-5.6 Sol Ultra vs Claude Opus 4.7 ist daher nicht nur ein Modellvergleich. Es ist eine Vorschau auf den nächsten KI-Plattform-Kampf. Die Zukunft gehört Systemen, die Reasoning, Tools, Memory, Verifikation und Workflow-Design kombinieren. Der intelligenteste Chatbot wird nicht gewinnen. Der nützlichste KI-Arbeiter wird es.
FAQ: GPT-5.6 Sol Ultra vs Claude Opus 4.7
Ist GPT-5.6 Sol Ultra besser als Claude Opus 4.7?
Nicht universell. GPT-5.6 Sol Ultra scheint stärker auf agentische Orchestrierung und OpenAI-native Workflows fokussiert zu sein, während Claude Opus 4.7 öffentlich stärkere Hinweise auf sorgfältiges Codieren, Arbeiten mit langen Kontexten und zuverlässige mehrstufige Ausführung aufweist. Welches Modell besser ist, hängt von Ihrem Anwendungsfall ab.
Welches Modell ist besser zum Programmieren?
Claude Opus 4.7 hat derzeit eine stärkere öffentliche Glaubwürdigkeit im Bereich Programmierung, da sowohl Anthropic als auch GitHub seine Leistung beim Codieren und in agentischen Entwickler-Workflows hervorgehoben haben. GPT-5.6 Sol Ultra könnte für agentische Kodiersysteme sehr wettbewerbsfähig werden, insbesondere wenn sein Ultra-Modus die Orchestrierung von Sub-Agenten verbessert.
Welches Modell ist günstiger?
Basierend auf öffentlichen Preisangaben sind beide Modelle mit 5 USD pro Million Eingabetoken gelistet. Claude Opus 4.7 ist mit 25 USD pro Million Ausgabetoken angegeben, während öffentliches Reporting GPT-5.6 Sol mit 30 USD pro Million Ausgabetoken listet. Die tatsächlichen Kosten hängen von Wiederholungen, Ausgabelänge, Tool-Nutzung, Caching und der Erfolgquote des Workflows ab.
Welches Modell ist besser für KI-Agenten?
GPT-5.6 Sol Ultra könnte für Agenten-Orchestrierung interessanter sein, da der Ultra-Modus auf Sub-Agenten ausgerichtet beschrieben wird. Claude Opus 4.7 könnte sich besser für zuverlässige, lang laufende Agentenausführungen eignen, insbesondere in kodier- und dokumentenintensiven Workflows. Bei besonders wertvollen Anwendungsfällen ist es oft am besten, beide Modelle über einen Modell-Router einzusetzen.
Welches Modell sollten Startups wählen?
Startups sollten basierend auf der Ökonomie ihres Workflows wählen. Wenn das Produkt auf Integration ins OpenAI-Ökosystem und Multi-Agenten-Orchestrierung angewiesen ist, testen Sie GPT-5.6 Sol Ultra. Wenn das Produkt auf Schlussfolgerungen über lange Kontexte, Zuverlässigkeit beim Codieren und sorgfältige Analysen angewiesen ist, testen Sie Claude Opus 4.7. In der Produktion sollten Aufgaben nach den Stärken der Modelle geroutet werden, statt ein Modell für alles zu verwenden.
Welches Modell ist besser für Investment-Research?
Claude Opus 4.7 könnte stärker sein beim Lesen langer Einreichungen (Filings) und bei der Erstellung vorsichtiger Analysen. GPT-5.6 Sol Ultra könnte stärker sein für Multi-Agenten-Research-Workflows, die Nachrichten sammeln, Finanzdaten vergleichen, Risiken debattieren und Thesenänderungen überwachen. Die besten Investment-Research-Systeme werden wahrscheinlich mehrere Modelle und spezialisierte Agenten kombinieren.