
GPT-5.6 Sol Ultra and Claude Opus 4.7 represent two different visions of frontier AI. One is positioned around agentic orchestration, deep reasoning modes, and OpenAI’s expanding product ecosystem. The other is built around careful execution, long-context work, coding reliability, and enterprise-grade workflow discipline. The real question is no longer simply “which model is smarter?” It is “which model fits the way you actually work?”
The AI model race has changed. A year ago, most model comparisons focused on answer quality: which model wrote the best essay, solved the hardest riddle, summarized the longest PDF, or produced the cleanest code snippet. That still matters, but it is no longer enough. In 2026, the frontier is shifting toward AI systems that can plan, use tools, manage context, recover from errors, and keep working through multi-step objectives. The most valuable model is not always the one that gives the most impressive single response. It is often the model that can complete the most useful workflow with the least friction.
That is why the comparison between GPT-5.6 Sol Ultra and Claude Opus 4.7 is interesting. These models are not just chatbot upgrades. They are candidates for becoming the intelligence layer behind software engineering agents, research copilots, financial analysis systems, enterprise automations, and decision-support workflows. For developers, the question becomes whether GPT-5.6 Sol Ultra or Claude Opus 4.7 is better for coding, debugging, architecture, and agentic execution. For businesses, the question becomes which model gives better value per dollar. For investors and analysts, the question becomes which model can turn noisy information into structured insight.
This article compares the two models across public information, pricing, coding use cases, reasoning behavior, benchmark context, developer workflows, AI agent performance, and real-world research scenarios. Where reliable public numbers exist, we use them. Where independent benchmark coverage is still limited, especially for GPT-5.6 Sol Ultra during its early preview period, we avoid pretending that exact rankings are already settled. A good AI comparison should help people make better decisions, not manufacture fake certainty.
Important note on sources: GPT-5.6 Sol Ultra is still early in the public cycle. The most useful public reporting describes GPT-5.6 as a limited preview model suite with Sol as the flagship, plus Max and Ultra modes for deeper reasoning and sub-agent orchestration. Claude Opus 4.7 has more direct official information from Anthropic, including API availability, pricing, and tester feedback. This comparison therefore separates confirmed data from practical interpretation.
The AI Race Has Changed: From Chatbots to Intelligent Agents

The easiest way to misunderstand GPT-5.6 Sol Ultra vs Claude Opus 4.7 is to treat the comparison like a simple chatbot contest. That framing is outdated. The best models are no longer competing only on whether they can write a better paragraph or answer a trivia question. They are competing on whether they can operate as intelligent workers inside a larger system.
In the chatbot era, the user did most of the work. The user broke the problem into pieces, wrote careful prompts, copied output into other tools, checked mistakes manually, asked follow-up questions, and stitched the final answer together. The model was powerful, but it was passive. It waited for instructions.
In the agent era, the model is expected to do more of the coordination. It should understand the goal, plan the steps, gather evidence, use tools, write or modify code, test the result, inspect failures, revise its approach, and provide a decision-ready output. This does not mean that AI is autonomous in the magical sense. It means the unit of value is shifting from one answer to one completed workflow.
GPT-5.6 Sol Ultra appears designed for that shift. Public reporting describes Sol as OpenAI’s flagship in the GPT-5.6 suite, with strengths in coding, cybersecurity, biology, and long-horizon agentic tasks. The Ultra mode is especially notable because it is described as leveraging sub-agents. That framing matters. Sub-agent orchestration suggests a model designed not only to reason in one stream, but to distribute work across specialized internal or external processes.
Claude Opus 4.7 comes from a different but equally important direction. Anthropic’s public materials emphasize complex multi-step workflows, coding, tool use, long-running tasks, data discipline, instruction following, and consistency. Early tester quotes highlighted Claude Opus 4.7’s ability to catch logical faults during planning, continue through tool failures, and avoid plausible but unsupported fallbacks. That is not just “better writing.” That is workflow reliability.
This creates the central contrast: GPT-5.6 Sol Ultra looks like a model optimized for orchestration and agent ecosystems, while Claude Opus 4.7 looks like a model optimized for careful, reliable execution across long and complex work. The winner depends on whether your use case values broad ecosystem integration and agentic flexibility, or long-context consistency and conservative precision.
GPT-5.6 Sol Ultra vs Claude Opus 4.7: Quick Comparison
Before going deep into benchmarks and workflows, here is the high-level comparison. This table is not meant to declare a universal winner. It is meant to clarify where each model appears strongest based on current public information and practical usage patterns.
Category GPT-5.6 Sol Ultra Claude Opus 4.7 Core positioning Flagship OpenAI model suite variant focused on advanced reasoning, coding, and agentic workflows, with Ultra mode described around sub-agent orchestration. Anthropic frontier Opus model focused on coding, long-context work, complex tasks, consistent execution, and careful instruction following. Best fit Agent workflows, OpenAI ecosystem apps, tool orchestration, automated research, multimodal and productized AI experiences. Long documents, complex coding tasks, careful analysis, enterprise engineering workflows, Claude Code, and structured reasoning. Coding Strong candidate for agentic coding and automated debugging, especially where OpenAI tooling is central. Very strong public positioning in coding and long-running software tasks; available in Claude Code and GitHub Copilot integrations. Pricing Public reporting lists GPT-5.6 Sol at $5 per million input tokens and $30 per million output tokens during the preview context. Anthropic states Claude Opus 4.7 remains $5 per million input tokens and $25 per million output tokens. Benchmark certainty Independent public benchmark data is still limited because of the early preview cycle. More public ecosystem feedback and official Anthropic claims are available; independent benchmark coverage varies by test. Agent capability Potentially stronger for sub-agent orchestration and broad AI product workflows. Potentially stronger for reliable long-running execution and tool-dependent workflows. Best practical choice Choose it when you want an OpenAI-native agent system, broad ecosystem integration, and high-end reasoning modes. Choose it when you want disciplined coding, document reasoning, long-context reliability, and careful outputs.
Model Philosophy: OpenAI Sol Ultra vs Anthropic Opus
OpenAI and Anthropic have different product philosophies, and those differences show up in model behavior. OpenAI’s frontier models increasingly feel like components of an expanding AI operating system: ChatGPT, API workflows, multimodal inputs, tool use, coding environments, enterprise integrations, and agentic product surfaces. The model is not just a brain. It is part of a system that wants to handle more of the user’s work from beginning to end.
GPT-5.6 Sol Ultra fits that direction. The “Sol” branding suggests the flagship tier, while “Ultra” suggests the most capable mode for complex tasks. The key phrase is sub-agent orchestration. In practical terms, the most advanced AI systems are beginning to look less like one giant answer generator and more like a manager of specialized workers. One agent may inspect source code. Another may search documentation. Another may evaluate security implications. Another may summarize trade-offs. The main model coordinates these efforts into a final result.
Anthropic’s Opus philosophy feels more centered on dependable intelligence. Claude has long been known for writing quality, long-context understanding, and a cautious style. Claude Opus 4.7 extends that pattern into professional work. Anthropic’s announcement emphasized testing feedback from coding, data, research, and workflow companies. The language is less about flashy demos and more about fewer tool errors, better planning, stronger long-running task performance, and better disclosure when data is missing.
That difference matters because many AI failures in production are not caused by lack of raw intelligence. They are caused by bad workflow behavior. The model invents missing information. It stops too early. It fails silently. It follows the wrong instruction hierarchy. It uses tools incorrectly. It changes the task without explaining why. It produces impressive output that is not actually grounded in the available evidence. Anthropic’s messaging around Claude Opus 4.7 directly targets those production problems.
The practical takeaway is simple: GPT-5.6 Sol Ultra may be more exciting for builders who want AI systems to coordinate multiple tasks and integrate deeply into a product ecosystem. Claude Opus 4.7 may be more attractive for teams that need careful execution, strong context management, and fewer reasoning surprises in long professional workflows.
Benchmark Comparison: Which AI Model Is Smarter?

Benchmarks are useful, but only if they are interpreted correctly. A leaderboard number is not the same thing as product fit. A model can score well on a benchmark and still be frustrating in a real workflow. Another model can be slightly behind on a synthetic test but better at following instructions, using tools, or maintaining context across a long task.
For GPT-5.6 Sol Ultra, the honest benchmark situation is that independent public results are still limited. Because the model was introduced in a limited preview context, broad third-party benchmark coverage has not yet stabilized. That means any article claiming exact universal rankings for GPT-5.6 Sol Ultra across every benchmark should be treated carefully unless it links to a real public leaderboard or official eval release.
For Claude Opus 4.7, there is more public material. Anthropic’s own announcement includes early tester feedback across coding, research-agent tasks, data analysis, and multi-step workflows. GitHub also announced that Claude Opus 4.7 was rolling out to GitHub Copilot, with early testing pointing to stronger multi-step task performance and more reliable agentic execution. Those are not the same as neutral academic benchmarks, but they are meaningful because they come from developer-product contexts where real workflows matter.
Independent benchmark sites such as SWE-bench and Artificial Analysis are important because they provide external context. SWE-bench focuses on real software engineering issues, including a human-filtered Verified subset. Artificial Analysis compares models across intelligence, speed, price, output tokens, and cost-per-task style metrics. These platforms are valuable because they help separate marketing claims from measurable behavior. However, they also require caution: benchmark results depend on scaffolding, tool access, prompt design, agent framework, and evaluation rules.
The best way to read the benchmark landscape is not “GPT wins” or “Claude wins.” Instead, think in categories:
Reasoning benchmarks test whether a model can solve hard problems, but may not reflect production tool use.
Coding benchmarks test software repair or generation, but results depend heavily on the agent scaffold.
Long-context benchmarks test retrieval and synthesis across large inputs, but real projects include messy files, conflicting requirements, and incomplete information.
Agent benchmarks are closer to real work, but they are still evolving quickly.
Cost benchmarks matter because a model that is 5% better but 3x more expensive may be worse for production.
If you need a strict benchmark answer today, Claude Opus 4.7 currently has more public grounding because Anthropic has released official details and ecosystem partners have discussed its performance. GPT-5.6 Sol Ultra has stronger strategic promise around sub-agent orchestration, but independent validation is still catching up. That gap may close quickly as the preview expands.
Coding Comparison: GPT-5.6 Sol Ultra vs Claude Opus 4.7 for Developers

Coding is one of the most important battlegrounds for frontier models because developers are among the most valuable AI users. They use models frequently, they pay for premium tools, and they push models into hard real-world tasks: refactoring legacy systems, debugging flaky tests, designing architecture, reading unfamiliar codebases, writing migrations, generating test cases, and operating inside IDEs.
Claude Opus 4.7 has a clear public advantage in coding credibility today because Anthropic and GitHub have both positioned it around software engineering workflows. Anthropic’s announcement includes feedback from early testers who describe better planning, fewer tool errors, and stronger performance on complex coding workflows. GitHub’s changelog says Opus 4.7 is rolling out in GitHub Copilot and describes improvements in multi-step tasks, long-horizon reasoning, and tool-dependent workflows. For developers, that matters more than a single code snippet demo.
The reason Claude often performs well in coding is not only that it writes code. Many models can write code. The hard part is understanding a project’s existing architecture, preserving style, following constraints, making minimal changes, diagnosing failures, and knowing when not to over-engineer. Claude’s careful style is useful here. It tends to reason through the problem, explain trade-offs, and avoid rushing to a solution too quickly. In a large codebase, that caution can be a feature.
GPT-5.6 Sol Ultra’s coding story is different. Public reporting emphasizes that GPT-5.6 Sol is especially skilled at coding and long-horizon agentic tasks. If Ultra mode truly improves sub-agent orchestration, the model could be very strong in coding workflows that require parallel reasoning: one sub-agent reads tests, another inspects implementation, another searches docs, another proposes a patch, and another validates edge cases. That structure is highly relevant to modern AI software engineering.
For a solo developer inside an IDE, Claude Opus 4.7 may feel more immediately reliable if the task is reading and modifying an existing codebase. For a platform builder creating automated coding agents, GPT-5.6 Sol Ultra may be more interesting because the architecture points toward orchestration. But until independent coding benchmarks and real developer reports are broader, the right conclusion is not that GPT-5.6 has already beaten Claude. The right conclusion is that the two models may be optimized for different coding workflows.
Where Claude Opus 4.7 may be stronger for coding
Understanding large codebases with many constraints.
Following detailed instructions across long sessions.
Explaining trade-offs and avoiding unsupported assumptions.
Working inside Claude Code and GitHub Copilot integrations.
Complex refactoring where careful context handling matters.
Where GPT-5.6 Sol Ultra may be stronger for coding
Agentic coding systems that use multiple tools and sub-agents.
Automated workflows that require planning, execution, and validation loops.
OpenAI-native developer products and API-based coding agents.
Tasks that combine code, documents, logs, screenshots, and multimodal context.
Fast iteration inside broader AI product ecosystems.
If your question is “which model should I use in Cursor, Claude Code, Copilot, or an internal coding agent?” the answer is to test both on your real repository. Use five tasks: one bug fix, one refactor, one feature, one test-generation task, and one architecture explanation. Measure not only whether the code compiles, but how many turns it takes, how many files it touches, whether it respects style, and whether it invents APIs. That will tell you more than a leaderboard.
Reasoning Ability: Deep Thinking vs Practical Intelligence
Reasoning is the most overused word in AI marketing. Every frontier model claims better reasoning. The more useful question is: what kind of reasoning does the model perform well?
GPT-5.6 Sol Ultra’s reasoning story is tied to modes. Public reporting says Sol includes a Max mode for deeper reasoning and an Ultra mode for sub-agent orchestration. That implies a model designed to allocate more computation and structure to difficult tasks. In user terms, this may show up as better planning, stronger decomposition, improved tool coordination, and fewer shallow answers on hard problems.
Claude Opus 4.7’s reasoning story is tied to discipline. Anthropic’s public examples emphasize catching logical faults during planning, correctly reporting missing data, resisting traps, and continuing through tool failures. That type of reasoning is extremely valuable in professional work. It is not just about solving a puzzle. It is about knowing what evidence exists, what is missing, what can be inferred, and what should not be claimed.
Apply this research method to your stock
Generate bull/bear views, risk notes, and an evidence trail for GPT.
For a user, the difference may feel like this: GPT-5.6 Sol Ultra is more likely to behave like a high-energy strategist that can coordinate a complex workflow, while Claude Opus 4.7 is more likely to behave like a careful senior analyst that protects against weak assumptions. Both styles are useful. The best model depends on the cost of being wrong.
If you are brainstorming a product strategy, building an AI agent workflow, or generating multiple options quickly, GPT-5.6 Sol Ultra may be the more powerful creative engine. If you are reviewing a contract, analyzing a long financial report, validating a data pipeline, or investigating a production incident, Claude Opus 4.7’s caution may be more valuable.
The deepest reasoning systems will eventually combine both styles: bold decomposition plus conservative verification. That is why agent workflows matter. A good AI system should not depend on one model personality. It should use one model to generate hypotheses, another to challenge them, another to verify sources, and another to turn the result into an actionable decision. This is especially important in financial research, where confident but ungrounded conclusions can be costly.
Long Context and Document Work
Long context is one of Claude’s strongest brand associations. Claude models have been widely used for reading documents, contracts, codebases, research papers, and business reports. Claude Opus 4.7 continues that pattern by emphasizing long-context consistency and professional knowledge work. Anthropic’s announcement includes tester feedback praising data discipline, missing-data disclosure, and strong long-context performance.
Long context is not just about the size of the window. A million-token context window sounds impressive, but what matters is whether the model uses the context correctly. Can it find the relevant detail? Can it avoid being distracted by irrelevant text? Can it reconcile conflicting sources? Can it tell the user when the answer is not present? Can it preserve constraints from the beginning of the task through the end?
Claude Opus 4.7 appears especially well suited for tasks where the input is long, messy, and important. Examples include legal review, policy analysis, investment memos, technical documentation, customer support knowledge bases, due diligence folders, compliance manuals, and large code repositories. In these situations, hallucination control and context discipline may matter more than speed.
GPT-5.6 Sol Ultra may be more compelling when long context is part of a broader workflow. For example, instead of simply reading a long report, an agentic system might summarize the report, extract key metrics, compare them with market data, check recent news, generate investment hypotheses, debate risk factors, and produce a final thesis. If Ultra mode’s sub-agent orchestration works well, GPT-5.6 could be powerful in this kind of multi-source workflow.
So the distinction is not “Claude for long context, GPT for everything else.” It is more precise: Claude Opus 4.7 may be stronger for careful long-context reading and grounded synthesis, while GPT-5.6 Sol Ultra may be stronger for long-context workflows that require orchestration, tool use, and multi-stage execution.
AI Agent Performance: The Real Difference
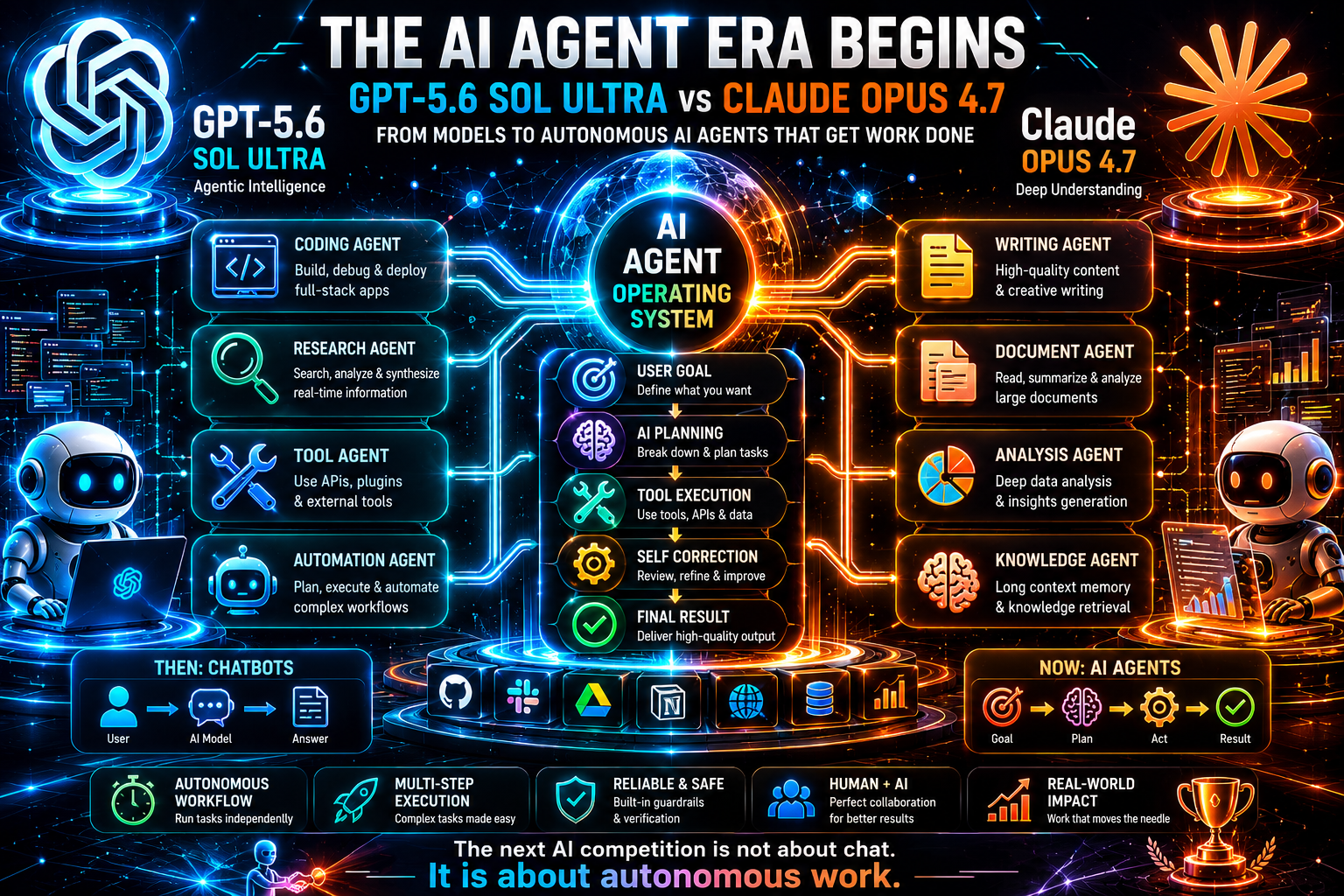
The most important category in this comparison is AI agent performance. This is where the market is going. Chatbots are useful, but agents are where productivity gains become measurable. An AI agent can take a goal, plan steps, call tools, use APIs, inspect outputs, revise its plan, and continue until a task is complete or a human decision is needed.
GPT-5.6 Sol Ultra’s strongest narrative is agentic orchestration. The Ultra mode description points toward sub-agents, which is one of the most important patterns in advanced AI system design. A single model call can be powerful, but complex work benefits from specialized roles: researcher, critic, coder, tester, risk analyst, summarizer, and decision agent. If GPT-5.6 Sol Ultra is optimized for that structure, it could become a strong foundation for next-generation AI products.
Claude Opus 4.7’s strongest narrative is agentic reliability. Anthropic and GitHub both emphasize multi-step task performance, long-running work, tool-dependent workflows, and fewer failures. In production, reliability is often more valuable than raw ambition. An agent that attempts too much and breaks silently is dangerous. An agent that proceeds carefully, reports uncertainty, and recovers from tool failures is easier to trust.
This creates a useful distinction for builders:
Use GPT-5.6 Sol Ultra when the agent needs broad orchestration, multiple specialized steps, and integration with OpenAI-native workflows.
Use Claude Opus 4.7 when the agent needs careful context handling, long-running coding or research, and reliable execution under complex constraints.
Use both when the task is high value: one model can generate and plan, while the other critiques, verifies, or rewrites.
The future of AI agents will not be one model replacing every other model. It will be intelligent routing. A platform will choose the best model for each stage of the workflow. It may use a cheaper model for classification, a fast model for extraction, Claude for long document analysis, GPT for orchestration, and a specialized coding model for repository changes. The winning product will not simply be the product with the biggest model. It will be the product with the best workflow design.
Pricing Comparison: Which Model Gives Better Value?

Pricing is where the comparison becomes concrete. Based on public reporting, GPT-5.6 Sol is priced at $5 per million input tokens and $30 per million output tokens. Anthropic states that Claude Opus 4.7 is priced at $5 per million input tokens and $25 per million output tokens. That makes Claude Opus 4.7 cheaper on output tokens if those numbers are the pricing basis for your deployment.
Model Input price Output price Pricing takeaway GPT-5.6 Sol $5 / 1M tokens $30 / 1M tokens Same input price as Opus 4.7, higher output price based on current public reporting. Claude Opus 4.7 $5 / 1M tokens $25 / 1M tokens Lower output price, strong fit for long coding and document workflows if token use is controlled.
However, token price alone does not determine real cost. Real cost depends on output length, context size, prompt caching, retry rate, tool calls, latency, and how often the model gets the answer right the first time. A cheaper model can become expensive if it requires many retries. A more expensive model can be cheaper if it completes the task with fewer calls. For coding agents, the biggest cost driver is often not the initial prompt. It is the iterative loop: inspect files, propose changes, run tests, read errors, revise, and repeat.
Business Insider reported that Anthropic updated its Claude Code token-spend estimates, saying average enterprise developer cost was around $13 per active day and $150 to $250 per developer per month, with 90% of users under $30 per active day. The important point is not that Claude is uniquely expensive. The point is that AI agent usage changes the cost structure. When models become workers instead of answer engines, they consume more tokens because they do more work.
For production teams, the pricing question should be framed as cost per completed workflow. For example:
How much does it cost to resolve one support ticket?
How much does it cost to fix one bug?
How much does it cost to generate one investment brief?
How much does it cost to analyze one earnings call?
How much does it cost to monitor one stock for a week?
Once you measure cost this way, the best model may vary by task. Claude Opus 4.7 may be more cost-effective for careful long-context outputs because its output token price is lower and its style may reduce rework. GPT-5.6 Sol Ultra may be more cost-effective for workflows where orchestration reduces human coordination time. The only reliable way to know is to run task-level evaluations with real prompts, real files, and real success criteria.
Developer Experience: Claude Code, GitHub Copilot, APIs and Agent Frameworks
Model quality matters, but developer experience determines adoption. A model that is slightly better but harder to integrate may lose to a model that fits naturally into existing workflows. This is why Claude Code, GitHub Copilot, ChatGPT, API tooling, and agent frameworks are so important.
Claude Opus 4.7 benefits from being integrated into developer environments where users already work. GitHub’s announcement that Opus 4.7 is rolling out in Copilot gives it distribution inside one of the most important coding products in the world. Claude Code also gives Anthropic a direct interface for agentic software engineering. For developers who want a powerful coding partner rather than a raw API, this matters.
GPT-5.6 Sol Ultra benefits from OpenAI’s broader ecosystem. ChatGPT remains a mainstream AI interface, OpenAI’s API has strong developer mindshare, and the company’s product direction increasingly supports tools, multimodal workflows, and agentic applications. If your team already builds on OpenAI APIs, GPT-5.6 Sol Ultra may be easier to adopt as an upgrade path.
The developer experience question should include:
Does the model work inside the tools your team already uses?
Can it call your internal tools safely?
Can you monitor token usage and workflow success?
Can you route tasks between models?
Can you add guardrails for security, privacy, and compliance?
Can the model explain what it did and why?
For internal AI platforms, the best answer may be a model router rather than a single-model commitment. Use Claude Opus 4.7 for tasks that require careful reading and long-context codebase reasoning. Use GPT-5.6 Sol Ultra for planning-heavy, tool-heavy, multi-agent orchestration. Use cheaper models for extraction, classification, and repetitive tasks. This architecture is more resilient than betting everything on one frontier model.
Research and Analysis: Which Model Handles Complex Information Better?
Research is where AI models can create enormous leverage. A human analyst may spend hours reading reports, filings, transcripts, news, forum discussions, market data, and internal documents. A good AI model can compress that process. But a bad AI research system can produce confident nonsense.
Claude Opus 4.7 has a strong case for research tasks because of its long-context discipline and cautious handling of missing data. Anthropic’s announcement includes tester feedback describing better disclosure and data discipline. This matters in research because the most dangerous errors are often not obvious hallucinations. They are subtle unsupported inferences that sound reasonable.
GPT-5.6 Sol Ultra has a strong case for research workflows because of its agentic orientation. Research is not only reading. It is asking the right questions, gathering sources, comparing perspectives, identifying contradictions, updating a thesis, and deciding what to watch next. If Ultra mode improves sub-agent orchestration, GPT-5.6 could be especially useful for research systems that divide work among multiple agents.
For example, a financial research workflow might include:
A news agent that gathers recent company developments.
A filings agent that extracts revenue, margin, debt, and guidance changes.
A market agent that checks price action, volume, volatility, and sector movement.
A risk agent that challenges the bullish thesis.
A valuation agent that compares multiples and assumptions.
A final synthesis agent that produces a decision-ready brief.
This is where GPT-5.6 Sol Ultra and Claude Opus 4.7 could both be valuable. GPT may coordinate the workflow. Claude may critique the evidence. Another model may extract structured numbers cheaply. The final product is not a chatbot answer. It is an AI-native research process.
Why AI-Native Investment Research Is Becoming Possible
Investment research is a perfect example of why the AI model race is becoming a workflow race. Investors do not simply need answers. They need structured thinking under uncertainty. They need to know what changed, why it matters, what evidence supports the thesis, what could be wrong, and what signal should be monitored next.
Traditional financial research tools are often static. They show charts, ratios, headlines, analyst ratings, and filings. These are useful, but they require the user to connect the dots manually. The user still has to decide which information matters, which risks are underpriced, which narrative is changing, and which data point contradicts the consensus.
AI agents can change that. A research agent can read earnings transcripts. A risk agent can challenge assumptions. A valuation agent can compare scenarios. A news agent can track catalysts. A monitoring agent can watch for thesis-breaking events. A debate agent can simulate bull and bear arguments. This is not about replacing human judgment. It is about giving human investors a better research operating system.
That is where platforms like AlphaVue.ai fit into the broader AI shift. The next generation of investment platforms will not simply display data. They will help users reason through data. They will turn market information into workflows: scan, research, debate, compare, monitor, and decide. GPT-5.6 Sol Ultra and Claude Opus 4.7 are important not because one model will permanently defeat the other, but because both show how close the market is to AI-native investment intelligence.
For investors, the key question is no longer “can AI summarize this stock?” That is table stakes. The real question is: can AI help me understand what matters, what changed, what is priced in, what is uncertain, and what to do next? That requires agentic workflows, model routing, source discipline, and transparent reasoning. It also requires product design. A powerful model without a good workflow is like a Bloomberg terminal with no search, no alerts, and no structure.
AlphaVue.ai Perspective: From AI Models to AI Investment Agents
The future of financial research will not be one giant chatbot. It will be a network of specialized AI agents that research companies, compare market signals, test bull and bear cases, and help investors monitor what matters. AlphaVue.ai is built for this AI-native investment workflow: smarter research, clearer decisions, and faster insight.
Real-World Use Cases: Which Model Should You Choose?
There is no universal winner between GPT-5.6 Sol Ultra and Claude Opus 4.7. The right model depends on the job. Here is a practical decision framework.
Choose GPT-5.6 Sol Ultra when:
You are building AI agents that need planning, tool use, and orchestration.
You already use OpenAI APIs and want a frontier upgrade path.
Your workflow combines text, code, structured data, and possibly multimodal inputs.
You want the model to coordinate specialized sub-tasks.
You value ecosystem integration and product velocity.
Choose Claude Opus 4.7 when:
You need careful long-context reading and document analysis.
You work heavily with codebases, refactoring, and complex engineering tasks.
You value cautious reasoning and missing-data disclosure.
You use Claude Code or GitHub Copilot integrations that support Opus 4.7.
You want slightly lower output-token pricing based on listed rates.
Use both when:
The task is high-value enough to justify cross-model verification.
You need one model to generate and another to critique.
You are building a production AI platform with model routing.
You want to reduce single-model failure modes.
You care about both creativity and caution.
The most sophisticated teams will not ask “which model is best?” They will ask “which model should handle which step?” That is the right question for 2026. AI has become too important to treat model selection as a brand preference.
Final Verdict: GPT-5.6 Sol Ultra or Claude Opus 4.7?

If you want the simplest answer, it is this: Claude Opus 4.7 is the safer choice today for careful coding, long-context research, and disciplined professional workflows, while GPT-5.6 Sol Ultra is the more strategically exciting choice for agentic orchestration and OpenAI-native AI systems.
Claude Opus 4.7 has more public grounding right now. Anthropic has published official pricing and availability. GitHub has discussed its rollout in Copilot. Early tester feedback emphasizes exactly the capabilities that matter for real work: multi-step execution, fewer tool errors, stronger planning, and better long-context performance. If your team needs a model today for coding and research workflows, Claude Opus 4.7 deserves serious evaluation.
GPT-5.6 Sol Ultra is harder to judge with certainty because independent benchmark coverage is still limited. But its direction is important. The combination of flagship reasoning, Max mode, Ultra mode, and sub-agent orchestration points toward where AI is going: from answering questions to coordinating work. If OpenAI executes well, GPT-5.6 Sol Ultra could become one of the most important models for agent-native products.
The real winner may not be either model alone. The real winner is the workflow layer that uses the right model at the right time. In coding, that means agents that can read, patch, test, and explain. In research, that means systems that can gather, verify, debate, and monitor. In investing, that means platforms that turn market data into structured intelligence.
GPT-5.6 Sol Ultra vs Claude Opus 4.7 is therefore not just a model comparison. It is a preview of the next AI platform war. The future will belong to systems that combine reasoning, tools, memory, verification, and workflow design. The smartest chatbot will not win. The most useful AI worker will.
FAQ: GPT-5.6 Sol Ultra vs Claude Opus 4.7
Is GPT-5.6 Sol Ultra better than Claude Opus 4.7?
Not universally. GPT-5.6 Sol Ultra appears more focused on agentic orchestration and OpenAI-native workflows, while Claude Opus 4.7 has stronger public evidence for careful coding, long-context work, and reliable multi-step execution. The better model depends on your use case.
Which model is better for coding?
Claude Opus 4.7 currently has stronger public coding credibility because Anthropic and GitHub have both highlighted its performance in coding and agentic developer workflows. GPT-5.6 Sol Ultra may become highly competitive for agentic coding systems, especially if its Ultra mode improves sub-agent orchestration.
Which model is cheaper?
Based on public pricing, both models are listed at $5 per million input tokens. Claude Opus 4.7 is listed at $25 per million output tokens, while public reporting lists GPT-5.6 Sol at $30 per million output tokens. Real cost depends on retries, output length, tool use, caching, and workflow success rate.
Which model is better for AI agents?
GPT-5.6 Sol Ultra may be more interesting for agent orchestration because Ultra mode is described around sub-agents. Claude Opus 4.7 may be better for reliable long-running agent execution, especially in coding and document-heavy workflows. For high-value use cases, using both through a model router may be best.
Which model should startups choose?
Startups should choose based on workflow economics. If the product depends on OpenAI ecosystem integration and multi-agent orchestration, test GPT-5.6 Sol Ultra. If the product depends on long-context reasoning, coding reliability, and careful analysis, test Claude Opus 4.7. In production, route tasks by model strength rather than using one model for everything.
Which model is better for investment research?
Claude Opus 4.7 may be stronger for reading long filings and producing cautious analysis. GPT-5.6 Sol Ultra may be stronger for multi-agent research workflows that gather news, compare financial data, debate risks, and monitor thesis changes. The best investment research systems will likely combine multiple models and specialized agents.