
GPT-5.6 Sol Ultra y Claude Opus 4.7 representan dos visiones diferentes de la IA de frontera. Uno está posicionado en torno a la orquestación agentiva, los modos de razonamiento profundo y el creciente ecosistema de productos de OpenAI. El otro se construye en torno a la ejecución cuidadosa, el trabajo con contextos largos, la fiabilidad en la codificación y la disciplina de flujos de trabajo de nivel empresarial. La verdadera pregunta ya no es simplemente «¿qué modelo es más inteligente?». Es «¿qué modelo se adapta a la forma en que realmente trabajas?»
La carrera de modelos de IA ha cambiado. Hace un año, la mayoría de las comparaciones de modelos se centraban en la calidad de las respuestas: qué modelo escribía el mejor ensayo, resolvía el enigma más difícil, resumía el PDF más largo o producía el fragmento de código más limpio. Eso sigue siendo importante, pero ya no es suficiente. En 2026, la frontera se desplaza hacia sistemas de IA que pueden planificar, usar herramientas, gestionar contexto, recuperarse de errores y seguir trabajando en objetivos de varios pasos. El modelo más valioso no siempre es el que ofrece la respuesta individual más impresionante. A menudo es el modelo que puede completar el flujo de trabajo más útil con la menor fricción.
Por eso la comparación entre GPT-5.6 Sol Ultra y Claude Opus 4.7 resulta interesante. Estos modelos no son solo actualizaciones de chatbots. Son candidatos a convertirse en la capa de inteligencia detrás de agentes de ingeniería de software, copilotos de investigación, sistemas de análisis financiero, automatizaciones empresariales y flujos de trabajo de apoyo a la toma de decisiones. Para los desarrolladores, la cuestión es si GPT-5.6 Sol Ultra o Claude Opus 4.7 es mejor para codificar, depurar, diseñar arquitecturas y ejecutar de forma agentiva. Para las empresas, la pregunta es qué modelo ofrece mejor valor por dólar. Para inversores y analistas, la pregunta es qué modelo puede convertir información ruidosa en conocimiento estructurado.
Este artículo compara los dos modelos en función de información pública, precios, casos de uso de codificación, comportamiento de razonamiento, contexto de benchmarks, flujos de trabajo para desarrolladores, rendimiento de agentes de IA y escenarios de investigación en el mundo real. Donde existen cifras públicas fiables, las utilizamos. Donde la cobertura de benchmarks independiente aún es limitada, especialmente para GPT-5.6 Sol Ultra durante su periodo de vista previa temprana, evitamos fingir que los rankings exactos ya están decididos. Una buena comparación de IA debe ayudar a la gente a tomar mejores decisiones, no a fabricar certeza falsa.
Nota importante sobre las fuentes: GPT-5.6 Sol Ultra aún está en una fase temprana del ciclo público. Los informes públicos más útiles describen a GPT-5.6 como una suite de modelos en vista previa limitada con Sol como buque insignia, además de modos Max y Ultra para razonamiento más profundo y orquestación de subagentes. Claude Opus 4.7 cuenta con información oficial más directa por parte de Anthropic, incluida la disponibilidad de API, precios y comentarios de evaluadores. Por ello, esta comparación separa los datos confirmados de la interpretación práctica.
La carrera de la IA ha cambiado: de chatbots a agentes inteligentes

La forma más fácil de malinterpretar la comparación entre GPT-5.6 Sol Ultra y Claude Opus 4.7 es tratarla como un simple concurso de chatbots. Ese enfoque está desactualizado. Los mejores modelos ya no compiten únicamente por escribir un mejor párrafo o responder una pregunta de trivia. Compiten por si pueden operar como trabajadores inteligentes dentro de un sistema más amplio.
En la era de los chatbots, el usuario realizaba la mayor parte del trabajo. El usuario dividía el problema en piezas, redactaba prompts cuidadosos, copiaba la salida en otras herramientas, comprobaba los errores manualmente, hacía preguntas de seguimiento y ensamblaba la respuesta final. El modelo era potente, pero pasivo. Esperaba instrucciones.
En la era de los agentes, se espera que el modelo haga más de la coordinación. Debe comprender el objetivo, planear los pasos, recopilar evidencia, usar herramientas, escribir o modificar código, probar el resultado, inspeccionar fallos, revisar su enfoque y ofrecer una salida lista para la toma de decisiones. Esto no significa que la IA sea autónoma en un sentido mágico. Significa que la unidad de valor está cambiando de una única respuesta a un flujo de trabajo completado.
GPT-5.6 Sol Ultra parece diseñado para ese cambio. Los informes públicos describen a Sol como el buque insignia de OpenAI en la suite GPT-5.6, con fortalezas en programación, ciberseguridad, biología y tareas agentivas a largo plazo. El modo Ultra es especialmente notable porque se describe como aprovechando subagentes. Ese encuadre importa. La orquestación de subagentes sugiere un modelo diseñado no solo para razonar en un único hilo, sino para distribuir el trabajo entre procesos especializados internos o externos.
Claude Opus 4.7 procede de una dirección distinta pero igualmente importante. Los materiales públicos de Anthropic enfatizan flujos de trabajo complejos de múltiples pasos, programación, uso de herramientas, tareas de larga duración, disciplina de datos, seguimiento de instrucciones y consistencia. Citas de primeros evaluadores destacaron la capacidad de Claude Opus 4.7 para detectar fallos lógicos durante la planificación, continuar ante fallos de herramientas y evitar soluciones plausibles pero no respaldadas. Eso no es solo “mejor redacción”. Es fiabilidad del flujo de trabajo.
Esto crea el contraste central: GPT-5.6 Sol Ultra parece un modelo optimizado para la orquestación y los ecosistemas de agentes, mientras que Claude Opus 4.7 parece optimizado para una ejecución cuidadosa y fiable en trabajos largos y complejos. El vencedor depende de si su caso de uso valora la integración amplia del ecosistema y la flexibilidad agentiva, o la consistencia en largos contextos y la precisión conservadora.
GPT-5.6 Sol Ultra vs Claude Opus 4.7: Comparación rápida
Antes de profundizar en benchmarks y flujos de trabajo, aquí está la comparación a alto nivel. Esta tabla no pretende declarar un ganador universal. Pretende aclarar dónde parece ser más fuerte cada modelo en base a la información pública actual y a los patrones prácticos de uso.
Categoría GPT-5.6 Sol Ultra Claude Opus 4.7 Posicionamiento central Variante de la suite de modelos insignia de OpenAI centrada en razonamiento avanzado, programación y flujos de trabajo agentivos, con el modo Ultra descrito en torno a la orquestación de subagentes. Modelo frontier de Anthropic Opus centrado en programación, trabajo con contexto largo, tareas complejas, ejecución consistente y seguimiento cuidadoso de instrucciones. Mejor encaje Flujos de trabajo con agentes, aplicaciones del ecosistema OpenAI, orquestación de herramientas, investigación automatizada, experiencias de IA multimodal y productizadas. Documentos largos, tareas de programación complejas, análisis cuidadoso, flujos de trabajo de ingeniería empresarial, Claude Code y razonamiento estructurado. Programación Candidato fuerte para programación agentiva y depuración automatizada, especialmente cuando las herramientas de OpenAI son centrales. Posicionamiento público muy fuerte en programación y tareas de software de larga duración; disponible en Claude Code e integraciones con GitHub Copilot. Precios Los informes públicos sitúan a GPT-5.6 Sol en $5 por millón de tokens de entrada y $30 por millón de tokens de salida durante el periodo de vista previa. Anthropic afirma que Claude Opus 4.7 se mantiene en $5 por millón de tokens de entrada y $25 por millón de tokens de salida. Certidumbre de los benchmarks Los datos públicos independientes de benchmark todavía son limitados debido al ciclo temprano de la vista previa. Hay más retroalimentación pública del ecosistema y reclamaciones oficiales de Anthropic disponibles; la cobertura de benchmarks independientes varía según la prueba. Capacidad de agente Potencialmente más fuerte para la orquestación de subagentes y amplios flujos de producto de IA. Potencialmente más fuerte para ejecución fiable de larga duración y flujos de trabajo dependientes de herramientas. Mejor elección práctica Elígelo cuando quieras un sistema de agentes nativo de OpenAI, una amplia integración del ecosistema y modos de razonamiento de alta gama. Elígelo cuando quieras programación disciplinada, razonamiento documental, fiabilidad con contexto largo y salidas cuidadosas.
Filosofía del modelo: OpenAI Sol Ultra vs Anthropic Opus
OpenAI y Anthropic tienen diferentes filosofías de producto, y esas diferencias se reflejan en el comportamiento del modelo. Los modelos frontier de OpenAI cada vez se sienten más como componentes de un sistema operativo de IA en expansión: ChatGPT, flujos de trabajo por API, entradas multimodales, uso de herramientas, entornos de programación, integraciones empresariales y superficies de producto agentivas. El modelo no es solo un cerebro. Es parte de un sistema que pretende encargarse de más trabajo del usuario de principio a fin.
GPT-5.6 Sol Ultra encaja en esa dirección. La marca “Sol” sugiere el nivel insignia, mientras que “Ultra” sugiere el modo más capaz para tareas complejas. La frase clave es orquestación de subagentes. En términos prácticos, los sistemas de IA más avanzados comienzan a parecerse menos a un gran generador de respuestas y más a un gestor de trabajadores especializados. Un agente puede inspeccionar el código fuente. Otro puede buscar en la documentación. Otro puede evaluar implicaciones de seguridad. Otro puede resumir compensaciones. El modelo principal coordina estos esfuerzos en un resultado final.
La filosofía de Opus de Anthropic se siente más centrada en una inteligencia fiable. Claude es conocido desde hace tiempo por la calidad de su redacción, la comprensión de contextos largos y un estilo cauteloso. Claude Opus 4.7 amplía ese patrón hacia el trabajo profesional. El anuncio de Anthropic enfatizó la retroalimentación de pruebas procedente de empresas de programación, datos, investigación y flujos de trabajo. El lenguaje es menos sobre demostraciones llamativas y más sobre menos errores de herramientas, mejor planificación, mayor desempeño en tareas de larga duración y mejor divulgación cuando faltan datos.
Esa diferencia importa porque muchas fallas de IA en producción no se deben a la falta de inteligencia pura. Se deben a un mal comportamiento del flujo de trabajo. El modelo inventa información faltante. Se detiene demasiado pronto. Falla de forma silenciosa. Sigue la jerarquía de instrucciones equivocada. Usa las herramientas de forma incorrecta. Cambia la tarea sin explicar por qué. Produce resultados impresionantes que en realidad no están fundamentados en la evidencia disponible. El mensaje de Anthropic sobre Claude Opus 4.7 apunta directamente a esos problemas de producción.
El punto práctico es simple: GPT-5.6 Sol Ultra puede resultar más emocionante para los desarrolladores que quieren que los sistemas de IA coordinen múltiples tareas e se integren profundamente en un ecosistema de producto. Claude Opus 4.7 puede ser más atractivo para equipos que necesitan una ejecución cuidadosa, una gestión sólida del contexto y menos sorpresas de razonamiento en flujos de trabajo profesionales extensos.
Comparación de benchmarks: ¿Qué modelo de IA es más inteligente?

Los benchmarks son útiles, pero solo si se interpretan correctamente. Un número en una tabla de clasificación no es lo mismo que el ajuste al producto. Un modelo puede obtener buena puntuación en un benchmark y aun así resultar frustrante en un flujo de trabajo real. Otro modelo puede quedar ligeramente por detrás en una prueba sintética pero ser mejor siguiendo instrucciones, usando herramientas o manteniendo el contexto a lo largo de una tarea larga.
En cuanto a GPT-5.6 Sol Ultra, la situación honesta de los benchmarks es que los resultados públicos e independientes siguen siendo limitados. Debido a que el modelo se presentó en un contexto de vista previa limitada, la cobertura amplia de benchmarks por terceros aún no se ha estabilizado. Eso significa que cualquier artículo que afirme clasificaciones universales exactas para GPT-5.6 Sol Ultra en todos los benchmarks debe tratarse con cautela a menos que enlace a una tabla de clasificación pública real o a un lanzamiento oficial de evaluación.
Para Claude Opus 4.7 hay más material público. El propio anuncio de Anthropic incluye comentarios de probadores tempranos sobre codificación, tareas de agentes de investigación, análisis de datos y flujos de trabajo multietapa. GitHub también anunció que Claude Opus 4.7 se estaba implementando en GitHub Copilot, con pruebas iniciales que apuntan a un mejor rendimiento en tareas multietapa y a una ejecución agentiva más fiable. Eso no es lo mismo que benchmarks académicos neutrales, pero tiene sentido porque proviene de contextos producto-desarrollador donde importan los flujos de trabajo reales.
Sitios de benchmark independientes como SWE-bench y Artificial Analysis son importantes porque aportan contexto externo. SWE-bench se centra en problemas reales de ingeniería de software, incluida una subsección Verificada filtrada por humanos. Artificial Analysis compara modelos en aspectos como inteligencia, velocidad, precio, tokens de salida y métricas tipo costo por tarea. Estas plataformas son valiosas porque ayudan a separar las afirmaciones de marketing del comportamiento medible. Sin embargo, también requieren cautela: los resultados de los benchmarks dependen del andamiaje, el acceso a herramientas, el diseño de prompts, el marco de agente y las reglas de evaluación.
La mejor forma de leer el panorama de benchmarks no es «GPT gana» o «Claude gana». En lugar de eso, piensa en categorías:
-
Pruebas de razonamiento evalúan si un modelo puede resolver problemas difíciles, pero pueden no reflejar el uso en herramientas de producción.
-
Pruebas de codificación evalúan la reparación o generación de software, pero los resultados dependen en gran medida del andamiaje del agente.
-
Pruebas de contexto largo evalúan la recuperación y síntesis a través de entradas extensas, pero los proyectos reales incluyen archivos desordenados, requisitos contradictorios e información incompleta.
-
Pruebas de agentes se acercan más al trabajo real, pero todavía están evolucionando rápidamente.
-
Pruebas de costo importan porque un modelo que sea un 5 % mejor pero 3 veces más caro puede ser peor para producción.
Si necesita una respuesta estricta de benchmark hoy, Claude Opus 4.7 actualmente tiene más respaldo público porque Anthropic ha publicado detalles oficiales y socios del ecosistema han comentado su rendimiento. GPT-5.6 Sol Ultra tiene una promesa estratégica más fuerte en torno a la orquestación de sub-agentes, pero la validación independiente aún está poniéndose al día. Esa brecha puede cerrarse rápidamente a medida que se expanda la vista previa.
Comparación de codificación: GPT-5.6 Sol Ultra vs Claude Opus 4.7 para desarrolladores

La codificación es uno de los campos de batalla más importantes para los modelos de vanguardia porque los desarrolladores están entre los usuarios de IA más valiosos. Los usan con frecuencia, pagan por herramientas premium y llevan a los modelos a tareas difíciles del mundo real: refactorizar sistemas heredados, depurar pruebas inestables, diseñar arquitecturas, leer bases de código desconocidas, escribir migraciones, generar casos de prueba y operar dentro de IDEs.
Claude Opus 4.7 tiene hoy una clara ventaja pública en credibilidad para codificación porque Anthropic y GitHub lo han posicionado en flujos de trabajo de ingeniería de software. El anuncio de Anthropic incluye comentarios de probadores tempranos que describen mejor planificación, menos errores de herramientas y un rendimiento más sólido en flujos de trabajo de codificación complejos. El registro de cambios de GitHub dice que Opus 4.7 se está desplegando en GitHub Copilot y describe mejoras en tareas de múltiples pasos, razonamiento a largo plazo y flujos de trabajo dependientes de herramientas. Para los desarrolladores, eso importa más que una demostración con un solo fragmento de código.
La razón por la que Claude suele desempeñarse bien en codificación no es solo que escribe código. Muchos modelos pueden escribir código. La parte difícil es entender la arquitectura existente de un proyecto, preservar el estilo, seguir las restricciones, hacer cambios mínimos, diagnosticar fallos y saber cuándo no sobreingenierizar. El estilo cuidadoso de Claude es útil aquí. Tiende a razonar sobre el problema, explicar las compensaciones y evitar apresurarse demasiado hacia una solución. En una base de código grande, esa cautela puede ser una ventaja.
La historia de codificación de GPT-5.6 Sol Ultra es diferente. Los reportes públicos enfatizan que GPT-5.6 Sol es especialmente hábil en codificación y en tareas orientadas a agentes con horizonte largo. Si el modo Ultra realmente mejora la orquestación de sub-agentes, el modelo podría ser muy fuerte en flujos de trabajo de codificación que requieren razonamiento paralelo: un sub-agente lee las pruebas, otro inspecciona la implementación, otro busca en la documentación, otro propone un parche y otro valida casos límite. Esa estructura es altamente relevante para la ingeniería de software con IA moderna.
Para un desarrollador en solitario dentro de un IDE, Claude Opus 4.7 puede sentirse más inmediatamente confiable si la tarea es leer y modificar una base de código existente. Para un creador de plataformas que desarrolla agentes de codificación automatizados, GPT-5.6 Sol Ultra puede resultar más interesante porque la arquitectura apunta hacia la orquestación. Pero hasta que existan benchmarks de codificación independientes y más informes reales de desarrolladores, la conclusión correcta no es que GPT-5.6 ya haya vencido a Claude. La conclusión correcta es que los dos modelos pueden estar optimizados para distintos flujos de trabajo de codificación.
Dónde Claude Opus 4.7 puede ser más fuerte para la codificación
-
Comprender grandes bases de código con muchas restricciones.
-
Seguir instrucciones detalladas a lo largo de sesiones largas.
-
Explicar compensaciones y evitar suposiciones no fundamentadas.
-
Trabajar dentro de integraciones como Claude Code y GitHub Copilot.
-
Refactorizaciones complejas donde importa manejar cuidadosamente el contexto.
Dónde GPT-5.6 Sol Ultra puede ser más fuerte para la codificación
-
Sistemas de codificación agente que usan múltiples herramientas y subagentes.
-
Flujos de trabajo automatizados que requieren planificación, ejecución y bucles de validación.
-
Productos para desarrolladores nativos de OpenAI y agentes de codificación basados en API.
-
Tareas que combinan código, documentos, registros, capturas de pantalla y contexto multimodal.
-
Iteración rápida dentro de ecosistemas de productos de IA más amplios.
Si tu pregunta es "¿qué modelo debería usar en Cursor, Claude Code, Copilot o en un agente de codificación interno?" la respuesta es probar ambos en tu repositorio real. Usa cinco tareas: una corrección de bug, una refactorización, una nueva función, una tarea de generación de pruebas y una explicación de arquitectura. Mide no solo si el código compila, sino cuántas iteraciones requiere, cuántos archivos toca, si respeta el estilo y si inventa APIs. Eso te dirá más que una tabla de posiciones.
Capacidad de razonamiento: pensamiento profundo vs inteligencia práctica
Razonamiento es la palabra más sobreutilizada en el marketing de IA. Todo modelo de vanguardia afirma mejor razonamiento. La pregunta más útil es: ¿qué tipo de razonamiento realiza bien el modelo?
La historia del razonamiento de GPT-5.6 Sol Ultra está ligada a modos. Informes públicos dicen que Sol incluye un modo Max para un razonamiento más profundo y un modo Ultra para la orquestación de subagentes. Eso implica un modelo diseñado para asignar más computación y estructura a tareas difíciles. En términos de usuario, esto puede manifestarse como mejor planificación, descomposición más fuerte, coordinación de herramientas mejorada y menos respuestas superficiales en problemas complejos.
La historia del razonamiento de Claude Opus 4.7 está ligada a la disciplina. Los ejemplos públicos de Anthropic enfatizan detectar fallos lógicos durante la planificación, informar correctamente sobre datos faltantes, resistir trampas y continuar pese a fallos de herramientas. Ese tipo de razonamiento es extremadamente valioso en el trabajo profesional. No se trata solo de resolver un rompecabezas. Se trata de saber qué evidencia existe, qué falta, qué puede inferirse y qué no debe afirmarse.
Apply this research method to your stock
Generate bull/bear views, risk notes, and an evidence trail for GPT.
Para un usuario, la diferencia puede sentirse así: GPT-5.6 Sol Ultra es más propenso a comportarse como un estratega enérgico que puede coordinar un flujo de trabajo complejo, mientras que Claude Opus 4.7 es más propenso a comportarse como un analista sénior cuidadoso que protege contra supuestos débiles. Ambos estilos son útiles. El mejor modelo depende del costo de equivocarse.
Si estás ideando una estrategia de producto, construyendo un flujo de trabajo con agentes de IA o generando múltiples opciones rápidamente, GPT-5.6 Sol Ultra puede ser el motor creativo más potente. Si estás revisando un contrato, analizando un informe financiero extenso, validando una canalización de datos o investigando un incidente de producción, la cautela de Claude Opus 4.7 puede resultar más valiosa.
Los sistemas de razonamiento más profundos acabarán combinando ambos estilos: una descomposición audaz más una verificación conservadora. Por eso importan los flujos de trabajo con agentes. Un buen sistema de IA no debería depender de una sola personalidad de modelo. Debería usar un modelo para generar hipótesis, otro para desafiarlas, otro para verificar las fuentes y otro para convertir el resultado en una decisión accionable. Esto es especialmente importante en la investigación financiera, donde conclusiones seguras pero sin fundamento pueden resultar costosas.
Contexto largo y trabajo con documentos
El contexto largo es una de las asociaciones de marca más fuertes de Claude. Los modelos de Claude se han utilizado ampliamente para leer documentos, contratos, bases de código, artículos de investigación e informes empresariales. Claude Opus 4.7 continúa ese patrón al enfatizar la consistencia en contextos largos y el trabajo de conocimiento profesional. El anuncio de Anthropic incluye comentarios de evaluadores que elogian la disciplina con los datos, la divulgación de datos faltantes y el sólido rendimiento en contextos largos.
El contexto largo no se trata solo del tamaño de la ventana. Una ventana de contexto de un millón de tokens suena impresionante, pero lo que importa es si el modelo utiliza correctamente ese contexto. ¿Puede encontrar el detalle relevante? ¿Puede evitar distraerse con texto irrelevante? ¿Puede reconciliar fuentes contradictorias? ¿Puede decirle al usuario cuando la respuesta no está presente? ¿Puede mantener las restricciones desde el inicio hasta el final de la tarea?
Claude Opus 4.7 parece especialmente adecuado para tareas en las que la entrada es larga, desordenada e importante. Ejemplos incluyen la revisión legal, el análisis de políticas, los memorandos de inversión, la documentación técnica, las bases de conocimiento de soporte al cliente, las carpetas de diligencia debida, los manuales de cumplimiento y los grandes repositorios de código. En estas situaciones, el control de alucinaciones y la disciplina del contexto pueden importar más que la velocidad.
GPT-5.6 Sol Ultra puede ser más atractivo cuando el contexto largo forma parte de un flujo de trabajo más amplio. Por ejemplo, en lugar de limitarse a leer un informe extenso, un sistema basado en agentes podría resumir el informe, extraer métricas clave, compararlas con datos de mercado, comprobar noticias recientes, generar hipótesis de inversión, debatir factores de riesgo y producir una tesis final. Si la orquestación de subagentes del modo Ultra funciona bien, GPT-5.6 podría ser potente en este tipo de flujo de trabajo de múltiples fuentes.
Así que la distinción no es “Claude para contexto largo, GPT para todo lo demás.” Es más preciso: Claude Opus 4.7 puede ser más fuerte para la lectura cuidadosa de contextos largos y la síntesis fundamentada, mientras que GPT-5.6 Sol Ultra puede ser más potente para flujos de trabajo con contexto largo que requieren orquestación, uso de herramientas y ejecución en múltiples etapas.
Rendimiento de agentes de IA: la diferencia real
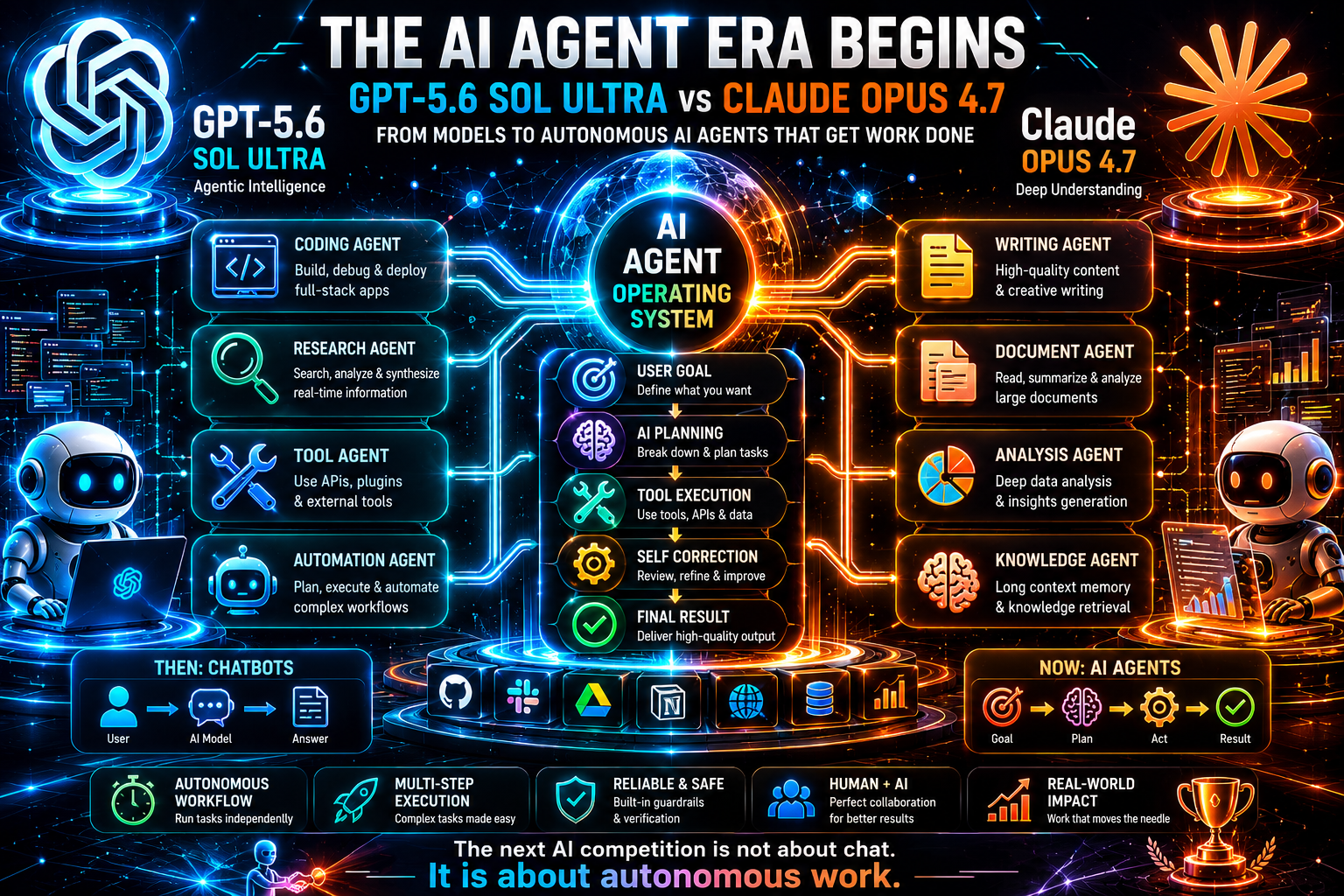
La categoría más importante en esta comparación es el rendimiento de los agentes de IA. Aquí es hacia donde se dirige el mercado. Los chatbots son útiles, pero los agentes son donde las ganancias de productividad se vuelven medibles. Un agente de IA puede recibir un objetivo, planear pasos, invocar herramientas, usar APIs, inspeccionar resultados, revisar su plan y continuar hasta que la tarea esté completa o se necesite una decisión humana.
La narrativa más fuerte de GPT-5.6 Sol Ultra es la orquestación de agentes. La descripción del modo Ultra apunta hacia subagentes, que es uno de los patrones más importantes en el diseño de sistemas de IA avanzados. Una única llamada al modelo puede ser poderosa, pero el trabajo complejo se beneficia de roles especializados: investigador, crítico, programador, probador, analista de riesgos, resumidor y agente decisor. Si GPT-5.6 Sol Ultra está optimizado para esa estructura, podría convertirse en una base sólida para productos de IA de próxima generación.
La narrativa más fuerte de Claude Opus 4.7 es la fiabilidad de agentes. Anthropic y GitHub enfatizan el desempeño en tareas multietapa, trabajos de larga duración, flujos de trabajo dependientes de herramientas y menos fallos. En producción, la fiabilidad a menudo vale más que la ambición pura. Un agente que intenta demasiado y falla silenciosamente es peligroso. Un agente que procede con cautela, informa la incertidumbre y se recupera de fallos de herramientas es más fácil de confiar.
Esto crea una distinción útil para los desarrolladores:
-
Utilice GPT-5.6 Sol Ultra cuando el agente necesite una amplia orquestación, múltiples pasos especializados e integración con flujos de trabajo nativos de OpenAI.
-
Utilice Claude Opus 4.7 cuando el agente necesite un manejo cuidadoso del contexto, codificación o investigación de larga duración y ejecución fiable bajo restricciones complejas.
-
Utilice ambos cuando la tarea sea de alto valor: un modelo puede generar y planificar, mientras que el otro critica, verifica o reescribe.
El futuro de los agentes de IA no será un modelo que reemplace a todos los demás. Será un enrutamiento inteligente. Una plataforma elegirá el mejor modelo para cada etapa del flujo de trabajo. Puede usar un modelo más barato para clasificación, un modelo rápido para extracción, Claude para análisis de documentos largos, GPT para orquestación y un modelo especializado en codificación para cambios en repositorios. El producto ganador no será simplemente el que tenga el modelo más grande. Será el producto con el mejor diseño de flujo de trabajo.
Comparación de precios: ¿Qué modelo ofrece mejor valor?

Los precios son el aspecto donde la comparación se vuelve concreta. Según reportes públicos, GPT-5.6 Sol tiene un precio de $5 por millón de tokens de entrada y $30 por millón de tokens de salida. Anthropic indica que Claude Opus 4.7 tiene un precio de $5 por millón de tokens de entrada y $25 por millón de tokens de salida. Eso hace que Claude Opus 4.7 sea más barato en tokens de salida si esos números son la base de precios para su implementación.
Modelo Precio de entrada Precio de salida Conclusión de precios GPT-5.6 Sol $5 / 1M tokens $30 / 1M tokens Mismo precio de entrada que Opus 4.7, precio de salida más alto según reportes públicos actuales. Claude Opus 4.7 $5 / 1M tokens $25 / 1M tokens Precio de salida más bajo, buen ajuste para flujos de trabajo de codificación y documentación de larga duración si se controla el uso de tokens.
Sin embargo, el precio por token por sí solo no determina el coste real. El coste real depende de la longitud de la salida, el tamaño del contexto, el almacenamiento en caché de prompts, la tasa de reintentos, las llamadas a herramientas, la latencia y de cuántas veces el modelo acierta en la respuesta a la primera. Un modelo más barato puede volverse caro si requiere muchos reintentos. Un modelo más caro puede resultar más barato si completa la tarea con menos llamadas. Para los agentes de programación, el principal factor de coste a menudo no es el prompt inicial. Es el bucle iterativo: inspeccionar archivos, proponer cambios, ejecutar pruebas, leer errores, revisar y repetir.
Business Insider informó que Anthropic actualizó sus estimaciones de gasto en tokens de Claude Code, indicando que el coste medio por desarrollador empresarial activo era alrededor de $13 por día activo y $150 a $250 por desarrollador por mes, con el 90% de los usuarios por debajo de $30 por día activo. El punto importante no es que Claude sea especialmente caro. Lo importante es que el uso de agentes de IA cambia la estructura de costes. Cuando los modelos se convierten en trabajadores en lugar de motores de respuestas, consumen más tokens porque hacen más trabajo.
Para los equipos de producción, la cuestión del precio debe plantearse como el coste por flujo de trabajo completado. Por ejemplo:
-
¿Cuánto cuesta resolver un ticket de soporte?
-
¿Cuánto cuesta corregir un error?
-
¿Cuánto cuesta generar un informe de inversión?
-
¿Cuánto cuesta analizar una llamada de resultados?
-
¿Cuánto cuesta monitorizar una acción durante una semana?
Una vez que midas el coste de esta manera, el mejor modelo puede variar según la tarea. Claude Opus 4.7 puede ser más rentable para salidas cuidadosas con contexto extenso porque su precio por token de salida es más bajo y su estilo puede reducir retrabajos. GPT-5.6 Sol Ultra puede ser más rentable para flujos de trabajo donde la orquestación reduce el tiempo de coordinación humana. La única forma fiable de saberlo es ejecutar evaluaciones a nivel de tarea con prompts reales, archivos reales y criterios de éxito reales.
Experiencia del desarrollador: Claude Code, GitHub Copilot, APIs y marcos de agentes
La calidad del modelo importa, pero la experiencia del desarrollador determina la adopción. Un modelo que sea ligeramente mejor pero más difícil de integrar puede perder frente a un modelo que encaje de forma natural en los flujos de trabajo existentes. Por eso Claude Code, GitHub Copilot, ChatGPT, las herramientas para APIs y los marcos de agentes son tan importantes.
Claude Opus 4.7 se beneficia de estar integrado en los entornos de desarrollo donde los usuarios ya trabajan. El anuncio de GitHub de que Opus 4.7 se está desplegando en Copilot le da distribución dentro de uno de los productos de programación más importantes del mundo. Claude Code también proporciona a Anthropic una interfaz directa para la ingeniería de software basada en agentes. Para los desarrolladores que quieren un compañero de codificación potente en lugar de una API cruda, esto importa.
GPT-5.6 Sol Ultra se beneficia del ecosistema más amplio de OpenAI. ChatGPT sigue siendo una interfaz de IA de uso general, la API de OpenAI tiene una gran cuota de atención entre desarrolladores, y la dirección de producto de la compañía apoya cada vez más las herramientas, los flujos de trabajo multimodales y las aplicaciones basadas en agentes. Si tu equipo ya construye sobre las APIs de OpenAI, GPT-5.6 Sol Ultra puede ser más fácil de adoptar como una vía de actualización.
La cuestión de la experiencia del desarrollador debería incluir:
-
¿Funciona el modelo dentro de las herramientas que su equipo ya utiliza?
-
¿Puede llamar a sus herramientas internas de forma segura?
-
¿Puede supervisar el uso de tokens y el éxito de los flujos de trabajo?
-
¿Puede enrutar tareas entre modelos?
-
¿Puede añadir salvaguardas para la seguridad, la privacidad y el cumplimiento?
-
¿Puede el modelo explicar lo que hizo y por qué?
Para plataformas internas de IA, la mejor respuesta puede ser un enrutador de modelos en lugar de comprometerse con un único modelo. Use Claude Opus 4.7 para tareas que requieren lectura cuidadosa y razonamiento sobre bases de código con contexto extenso. Use GPT-5.6 Sol Ultra para orquestación orientada a la planificación, intensiva en herramientas y multiagente. Use modelos más económicos para extracción, clasificación y tareas repetitivas. Esta arquitectura es más resiliente que apostar todo a un único modelo de vanguardia.
Investigación y análisis: ¿Qué modelo maneja mejor la información compleja?
La investigación es donde los modelos de IA pueden generar un apalancamiento enorme. Un analista humano puede pasar horas leyendo informes, presentaciones regulatorias, transcripciones, noticias, debates en foros, datos de mercado y documentos internos. Un buen modelo de IA puede comprimir ese proceso. Pero un mal sistema de investigación con IA puede producir tonterías con confianza.
Claude Opus 4.7 tiene un argumento sólido para tareas de investigación debido a su disciplina con contextos largos y su manejo cauteloso de los datos faltantes. El anuncio de Anthropic incluye comentarios de evaluadores que describen una mejor divulgación y disciplina de los datos. Esto importa en la investigación porque los errores más peligrosos a menudo no son alucinaciones obvias. Son inferencias sutiles y no respaldadas que suenan razonables.
GPT-5.6 Sol Ultra tiene un argumento sólido para flujos de trabajo de investigación debido a su orientación hacia agentes. La investigación no es solo leer. Es formular las preguntas correctas, recopilar fuentes, comparar perspectivas, identificar contradicciones, actualizar una tesis y decidir qué vigilar a continuación. Si el modo Ultra mejora la orquestación de subagentes, GPT-5.6 podría ser especialmente útil para sistemas de investigación que dividen el trabajo entre múltiples agentes.
Por ejemplo, un flujo de trabajo de investigación financiera podría incluir:
-
Un agente de noticias que recopile los desarrollos recientes de la empresa.
-
Un agente de presentaciones regulatorias que extraiga ingresos, márgenes, deuda y cambios en las previsiones.
-
Un agente de mercado que verifique la acción del precio, el volumen, la volatilidad y el movimiento del sector.
-
Un agente de riesgos que cuestione la tesis alcista.
-
Un agente de valoración que compare múltiplos y supuestos.
-
Un agente de síntesis final que produzca un informe listo para la toma de decisiones.
Aquí es donde GPT-5.6 Sol Ultra y Claude Opus 4.7 podrían ser ambos valiosos. GPT puede coordinar el flujo de trabajo. Claude puede criticar la evidencia. Otro modelo puede extraer números estructurados de forma económica. El producto final no es una respuesta de chatbot. Es un proceso de investigación nativo en IA.
Por qué la investigación de inversiones nativa en IA se está volviendo posible
La investigación de inversiones es un ejemplo perfecto de por qué la carrera de modelos de IA se está convirtiendo en una carrera de flujos de trabajo. Los inversores no solo necesitan respuestas. Necesitan pensamiento estructurado bajo incertidumbre. Necesitan saber qué cambió, por qué importa, qué evidencia respalda la tesis, qué podría estar mal y qué señal debe vigilarse a continuación.
Las herramientas tradicionales de investigación financiera suelen ser estáticas. Muestran gráficos, ratios, titulares, calificaciones de analistas y presentaciones. Esto es útil, pero requiere que el usuario conecte los puntos manualmente. El usuario aún debe decidir qué información importa, qué riesgos están infravalorados, qué narrativa está cambiando y qué dato contradice el consenso.
Los agentes de IA pueden cambiar eso. Un agente de investigación puede leer las transcripciones de resultados. Un agente de riesgos puede desafiar supuestos. Un agente de valoración puede comparar escenarios. Un agente de noticias puede rastrear catalizadores. Un agente de monitorización puede vigilar eventos que rompen la tesis. Un agente de debate puede simular argumentos alcistas y bajistas. No se trata de reemplazar el juicio humano. Se trata de ofrecer a los inversores humanos un mejor sistema operativo de investigación.
Ahí es donde plataformas como AlphaVue.ai encajan en el cambio más amplio hacia la IA. La próxima generación de plataformas de inversión no se limitará a mostrar datos. Ayudarán a los usuarios a razonar sobre los datos. Convertirán la información del mercado en flujos de trabajo: escanear, investigar, debatir, comparar, monitorizar y decidir. GPT-5.6 Sol Ultra y Claude Opus 4.7 son importantes no porque un modelo vaya a derrotar permanentemente al otro, sino porque ambos muestran lo cerca que está el mercado de la inteligencia de inversión nativa de IA.
Para los inversores, la pregunta clave ya no es «¿puede la IA resumir esta acción?». Eso es lo básico. La verdadera pregunta es: ¿puede la IA ayudarme a entender qué importa, qué cambió, qué está descontado, qué es incierto y qué hacer a continuación? Eso requiere flujos de trabajo agentivos, enrutamiento de modelos, disciplina de fuentes y razonamiento transparente. También requiere diseño de producto. Un modelo potente sin un buen flujo de trabajo es como una terminal Bloomberg sin búsqueda, sin alertas y sin estructura.
Perspectiva de AlphaVue.ai: De modelos de IA a agentes de inversión con IA
El futuro de la investigación financiera no será un único chatbot gigante. Será una red de agentes de IA especializados que investiguen empresas, comparen señales del mercado, prueben casos alcistas y bajistas y ayuden a los inversores a monitorizar lo que importa. AlphaVue.ai está diseñada para este flujo de trabajo de inversión nativo de IA: investigación más inteligente, decisiones más claras e ideas más rápidas.
Casos de uso en el mundo real: ¿Qué modelo deberías elegir?
No hay un ganador universal entre GPT-5.6 Sol Ultra y Claude Opus 4.7. El modelo adecuado depende del trabajo. Aquí hay un marco de decisión práctico.
Elige GPT-5.6 Sol Ultra cuando:
-
Estás construyendo agentes de IA que necesitan planificación, uso de herramientas y orquestación.
-
Ya usas las API de OpenAI y quieres una ruta de actualización de vanguardia.
-
Tu flujo de trabajo combina texto, código, datos estructurados y posiblemente entradas multimodales.
-
Quieres que el modelo coordine subtareas especializadas.
-
Valoras la integración del ecosistema y la velocidad del producto.
Elige Claude Opus 4.7 cuando:
-
Necesitas lectura cuidadosa de contextos extensos y análisis de documentos.
-
Trabajas intensamente con bases de código, refactorizaciones y tareas de ingeniería complejas.
-
Valoras el razonamiento cauteloso y la divulgación de datos faltantes.
-
Usas integraciones de Claude Code o GitHub Copilot que son compatibles con Opus 4.7.
-
Quieres una tarifa ligeramente más baja por token de salida basada en las tarifas indicadas.
Úsalos ambos cuando:
-
La tarea tiene suficiente valor como para justificar la verificación cruzada entre modelos.
-
Necesitas que un modelo genere y otro critique.
-
Estás construyendo una plataforma de IA de producción con enrutamiento de modelos.
-
Quieres reducir los modos de fallo de un único modelo.
-
Te importa tanto la creatividad como la cautela.
Los equipos más sofisticados no preguntarán “¿qué modelo es el mejor?” Preguntarán “¿qué modelo debe manejar cada paso?” Esa es la pregunta correcta para 2026. La IA se ha vuelto demasiado importante como para tratar la selección de modelos como una preferencia de marca.
Veredicto final: GPT-5.6 Sol Ultra o Claude Opus 4.7?

Si quieres la respuesta más simple, es esta: Claude Opus 4.7 es la opción más segura hoy para codificación cuidadosa, investigación de contexto extenso y flujos de trabajo profesionales disciplinados, mientras que GPT-5.6 Sol Ultra es la opción estratégicamente más emocionante para la orquestación de agentes y los sistemas de IA nativos de OpenAI.
Claude Opus 4.7 tiene más respaldo público en este momento. Anthropic ha publicado precios y disponibilidad oficiales. GitHub ha hablado de su despliegue en Copilot. Las primeras opiniones de los probadores enfatizan exactamente las capacidades que importan para el trabajo real: ejecución en múltiples pasos, menos errores de herramientas, mejor planificación y mayor rendimiento en contextos largos. Si tu equipo necesita hoy un modelo para flujos de trabajo de codificación e investigación, Claude Opus 4.7 merece una seria evaluación.
GPT-5.6 Sol Ultra es más difícil de juzgar con certeza porque la cobertura independiente de benchmarks aún es limitada. Pero su dirección es importante. La combinación de razonamiento insignia, Max mode, Ultra mode y la orquestación de subagentes apunta hacia dónde va la IA: de responder preguntas a coordinar trabajo. Si OpenAI ejecuta bien, GPT-5.6 Sol Ultra podría convertirse en uno de los modelos más importantes para productos nativos de agentes.
El verdadero ganador puede que no sea ninguno de los dos modelos por sí solo. El verdadero ganador es la capa de flujo de trabajo que usa el modelo correcto en el momento adecuado. En codificación, eso significa agentes que pueden leer, parchear, probar y explicar. En investigación, eso significa sistemas que pueden recopilar, verificar, debatir y monitorizar. En inversión, eso significa plataformas que convierten datos de mercado en inteligencia estructurada.
GPT-5.6 Sol Ultra vs Claude Opus 4.7 no es por tanto solo una comparación de modelos. Es un adelanto de la próxima guerra de plataformas de IA. El futuro pertenecerá a los sistemas que combinen razonamiento, herramientas, memoria, verificación y diseño de flujos de trabajo. El chatbot más inteligente no ganará. El trabajador de IA más útil sí lo hará.
FAQ: GPT-5.6 Sol Ultra vs Claude Opus 4.7
¿Es GPT-5.6 Sol Ultra mejor que Claude Opus 4.7?
No de forma universal. GPT-5.6 Sol Ultra parece estar más centrado en la orquestación basada en agentes y en flujos de trabajo nativos de OpenAI, mientras que Claude Opus 4.7 tiene evidencia pública más sólida en cuanto a codificación cuidadosa, trabajo con contexto largo y ejecución fiable de múltiples pasos. El mejor modelo depende de tu caso de uso.
¿Qué modelo es mejor para programación?
Claude Opus 4.7 actualmente cuenta con mayor credibilidad pública en codificación porque Anthropic y GitHub han destacado su rendimiento en codificación y flujos de trabajo basados en agentes para desarrolladores. GPT-5.6 Sol Ultra puede volverse muy competitivo para sistemas de codificación basados en agentes, especialmente si su modo Ultra mejora la orquestación de subagentes.
¿Qué modelo es más barato?
Según precios públicos, ambos modelos aparecen a $5 por millón de tokens de entrada. Claude Opus 4.7 figura a $25 por millón de tokens de salida, mientras que los informes públicos sitúan a GPT-5.6 Sol en $30 por millón de tokens de salida. El coste real depende de reintentos, longitud de la salida, uso de herramientas, caché y tasa de éxito del flujo de trabajo.
¿Qué modelo es mejor para agentes de IA?
GPT-5.6 Sol Ultra puede ser más interesante para la orquestación de agentes porque el modo Ultra se describe en torno a subagentes. Claude Opus 4.7 puede ser mejor para la ejecución fiable y de larga duración de agentes, especialmente en flujos de trabajo centrados en código y documentos. Para casos de alto valor, usar ambos mediante un enrutador de modelos puede ser lo mejor.
¿Qué modelo deberían elegir las startups?
Las startups deberían elegir según la economía del flujo de trabajo. Si el producto depende de la integración con el ecosistema de OpenAI y de la orquestación multiagente, prueben GPT-5.6 Sol Ultra. Si el producto depende de razonamiento con contexto largo, fiabilidad en codificación y análisis cuidadoso, prueben Claude Opus 4.7. En producción, enruten las tareas según la fortaleza del modelo en lugar de usar un único modelo para todo.
¿Qué modelo es mejor para investigación de inversiones?
Claude Opus 4.7 puede ser más fuerte para leer largos informes y producir análisis cautelosos. GPT-5.6 Sol Ultra puede ser más fuerte para flujos de trabajo de investigación multiagente que recopilan noticias, comparan datos financieros, debaten riesgos y supervisan cambios en la tesis. Los mejores sistemas de investigación de inversiones probablemente combinarán múltiples modelos y agentes especializados.