
GPT-5.6 Sol UltraとClaude Opus 4.7はフロンティアAIの二つの異なるビジョンを表しています。 一方はエージェント的なオーケストレーション、深い推論モード、そしてOpenAIの拡大するプロダクト・エコシステムを中心に据えています。もう一方は慎重な実行、長文コンテキスト作業、コーディングの信頼性、企業グレードのワークフロー規律を重視して設計されています。重要なのはもはや単に「どちらのモデルがより賢いか」ではなく、「どちらのモデルが実際のあなたの働き方に合っているか」です。
AIモデル競争は変化しました。1年前は、多くのモデル比較が応答の質に焦点を当てていました:どのモデルがもっとも良いエッセイを書いたか、最も難しい謎を解いたか、最長のPDFを要約したか、または最もきれいなコードスニペットを生成したか。これらは依然重要ですが、もはやそれだけでは不十分です。2026年には、フロンティアは計画し、ツールを使い、コンテキストを管理し、エラーから回復し、複数ステップの目的を通して作業を継続できるAIシステムへとシフトしています。最も価値のあるモデルは、常に最も印象的な単一の応答を返すものではありません。しばしば最も有用なワークフローを最小の摩擦で完了できるモデルの方が価値があります。
だからこそGPT-5.6 Sol UltraとClaude Opus 4.7の比較は興味深いのです。これらのモデルは単なるチャットボットのアップグレードではありません。ソフトウェアエンジニアリングエージェント、研究コパイロット、金融分析システム、企業自動化、意思決定支援ワークフローの背後にあるインテリジェンス層になる候補です。開発者にとっては、GPT-5.6 Sol UltraとClaude Opus 4.7のどちらがコーディング、デバッグ、アーキテクチャ、エージェント的実行に適しているかが問題になります。企業にとっては、どちらのモデルがドル当たりの価値をより良く提供するかが問題になります。投資家やアナリストにとっては、どちらのモデルがノイズの多い情報を構造化されたインサイトに変えられるかが課題です。
この記事では、公開情報、価格設定、コーディングユースケース、推論挙動、ベンチマーク文脈、開発者ワークフロー、AIエージェントの性能、実世界のリサーチシナリオにわたって両モデルを比較します。信頼できる公開数値が存在する箇所ではそれらを用います。特にGPT-5.6 Sol Ultraが早期プレビュー段階にある場合など、独立したベンチマーク報道がまだ限定的な箇所では、正確な順位がすでに確定しているかのように装うことは避けます。良いAI比較は人々がより良い意思決定を行えるよう助けるべきであり、偽の確実性を作り出してはなりません。
重要な情報源に関する注意:GPT-5.6 Sol Ultraは依然としてパブリックサイクルの初期段階にあります。最も有用な公開報道は、Solをフラッグシップとする限定プレビューのモデルスイートとしてGPT-5.6が説明されており、より深い推論やサブエージェントのオーケストレーション向けにMaxやUltraモードが用意されていると述べています。Claude Opus 4.7はAnthropicからのAPI提供、価格設定、テスターのフィードバックなど、より直接的な公式情報が存在します。したがって本比較では確認されたデータと実務的な解釈を分けて扱います。
AI競争は変わった:チャットボットからインテリジェントエージェントへ

GPT-5.6 Sol Ultra と Claude Opus 4.7 の比較を誤解する最も簡単な方法は、その比較を単純なチャットボット対決のように扱うことだ。その枠組みは時代遅れだ。優れたモデルはもはやより良い段落を書けるか、トリビアの質問に答えられるかだけで競っているわけではない。彼らが競っているのは、より大きなシステムの中で知的な作業者として機能できるかどうかだ。
チャットボット時代には、ユーザーがほとんどの作業を行っていた。ユーザーは問題を分割し、注意深いプロンプトを作成し、出力を他のツールにコピーし、誤りを手動で確認し、フォローアップの質問を行い、最終的な答えをつなぎ合わせた。モデルは強力だったが、受動的だった。指示を待っていた。
エージェント時代では、モデルがより多くの調整を行うことが期待される。目標を理解し、手順を計画し、証拠を集め、ツールを使い、コードを書いたり修正したりし、結果をテストし、失敗を検査し、アプローチを修正し、意思決定に使える出力を提供すべきだ。これはAIが魔法のように自律的であるという意味ではない。価値の単位が「1つの回答」から「完了したワークフロー」へと移りつつあるということだ。
GPT-5.6 Sol Ultra はその変化に対応するよう設計されているように見える。公表されている報道によれば Sol は GPT-5.6 スイートにおける OpenAI の旗艦であり、コーディング、サイバーセキュリティ、生物学、長期的なエージェンシータスクに強みがあるとされている。Ultra モードは特に注目に値する。サブエージェントを活用すると説明されているからだ。その枠組みは重要だ。サブエージェントのオーケストレーションは、単一のストリームで推論するだけでなく、専門化された内部または外部のプロセスに作業を分配するよう設計されたモデルを示唆する。
Claude Opus 4.7 は異なるが同じく重要な方向性から来ている。Anthropic の公開資料は、複雑な複数ステップのワークフロー、コーディング、ツール使用、長時間実行タスク、データ管理、指示遵守、一貫性を強調している。初期テスターの引用では、計画段階で論理的な欠陥を見つける能力、ツール障害時にも処理を継続する能力、もっともらしいが裏付けのないフォールバックを避ける能力が強調された。それは単なる「より良い文章」ではない。それはワークフローの信頼性だ。
ここに中心的な対比が生まれる:GPT-5.6 Sol Ultra はオーケストレーションとエージェント・エコシステム向けに最適化されたモデルのように見えるのに対し、Claude Opus 4.7 は長く複雑な作業において慎重で信頼性の高い実行に最適化されたモデルのように見える。どちらが適切かは、あなたのユースケースが広範なエコシステム統合とエージェント的柔軟性を重視するか、長いコンテキストでの一貫性と保守的な精度を重視するかによる。
GPT-5.6 Sol Ultra vs Claude Opus 4.7:クイック比較
ベンチマークやワークフローを詳細に見ていく前に、ここでハイレベルな比較を示す。この表は普遍的な勝者を決めるためのものではない。現在の公開情報と実際の使用パターンに基づいて、各モデルがどの点で強みを持つように見えるかを明確にすることを目的としている。
Category GPT-5.6 Sol Ultra Claude Opus 4.7 Core positioning フラッグシップ。OpenAIのモデルスイートのバリアントで、高度な推論、コーディング、エージェント指向ワークフローに注力しており、Ultraモードはサブエージェントのオーケストレーションを中心に説明されている。AnthropicのフロンティアOpusモデルはコーディング、長いコンテキストでの作業、複雑なタスク、一貫した実行、慎重な指示遵守に注力している。適合分野 エージェントワークフロー、OpenAIエコシステムのアプリ、ツールのオーケストレーション、自動化されたリサーチ、マルチモーダルおよび製品化されたAI体験に最適。長文ドキュメント、複雑なコーディングタスク、綿密な分析、エンタープライズ向けエンジニアリングワークフロー、Claude Code、構造化された推論に適している。コーディングに関しては、特にOpenAIのツールチェーンが中心となる環境で、エージェント的なコーディングと自動デバッグの有力候補である。コーディングおよび長時間実行されるソフトウェア作業における公開上のポジショニングは非常に強力で、Claude CodeやGitHub Copilotの統合で利用可能である。価格設定 公開報告では、プレビューコンテキストにおいてGPT-5.6 Solは入力トークン100万あたり$5、出力トークン100万あたり$30と記載されている。AnthropicはClaude Opus 4.7が入力トークン100万あたり$5、出力トークン100万あたり$25のままであると述べている。ベンチマークの確度 初期プレビューサイクルのため独立した公開ベンチマークデータはまだ限られている。より多くの公開エコシステムからのフィードバックとAnthropicの公式主張は入手可能だが、独立ベンチマークのカバレッジはテストによって異なる。エージェント能力 サブエージェントのオーケストレーションや幅広いAIプロダクトワークフローで潜在的に強みがある。長時間にわたる堅牢な実行やツール依存のワークフローにおいても信頼性が高い可能性がある。実用的な選択肢として フラッグシップのOpenAIネイティブなエージェントシステム、広範なエコシステム統合、高度な推論モードを求める場合はこれを選ぶとよい。規律あるコーディング、ドキュメント推論、長いコンテキストの信頼性、慎重な出力を求める場合はこれを選ぶとよい。
モデル哲学:OpenAI Sol Ultra vs Anthropic Opus
OpenAIとAnthropicは製品哲学が異なり、その違いはモデルの振る舞いにも表れている。OpenAIのフロンティアモデルは、チャットGPT、APIワークフロー、マルチモーダル入力、ツール使用、コーディング環境、エンタープライズ統合、エージェンティックなプロダクト面を含む拡張するAIオペレーティングシステムの構成要素のように感じられるようになってきている。モデルは単なる「頭脳」ではなく、ユーザーの作業を始めから終わりまでより多く扱おうとするシステムの一部である。
GPT-5.6 Sol Ultraはその方向性に合致している。「Sol」というブランドはフラッグシップ階層を示唆し、「Ultra」は複雑なタスクに対する最も能力の高いモードを示唆している。重要なフレーズはサブエージェントのオーケストレーションである。実務的には、最も進んだAIシステムは一つの巨大な解答生成器のように見えるよりも、専門化されたワーカーを管理するマネージャーのように見え始めている。あるエージェントはソースコードを検査し、別のエージェントはドキュメントを検索し、別のエージェントはセキュリティ上の影響を評価し、別のエージェントはトレードオフを要約する。主要モデルがこれらの作業を調整して最終結果にまとめるのだ。
AnthropicのOpus哲学は、より信頼できる知性に重心を置いているように感じられる。Claudeは以前から高品質な文章作成、長いコンテキストの理解、そして慎重なスタイルで知られている。Claude Opus 4.7はそのパターンをプロフェッショナルな作業へと拡張している。Anthropicの発表はコーディング、データ、研究、ワークフロー企業からのテストフィードバックを強調しており、言葉は派手なデモよりもツールエラーの削減、より良い計画、長時間実行タスクの強化、データ不足時のより良い開示について語っている。
その違いは重要です。なぜなら、多くの本番環境でのAIの失敗は、単に純粋な知能の不足が原因ではないからです。多くはワークフローの振る舞いの不具合によって引き起こされます。モデルが欠落した情報を捏造する。途中で処理を打ち切る。エラーや警告を出さずに静かに失敗する。誤った指示階層に従う。ツールを誤って使う。理由を説明せずにタスクを変更する。見た目は優れた出力を出すが、実際には利用可能な証拠に裏付けられていない出力を生成する。Anthropic(アンソロピック)がClaude Opus 4.7に関して発信しているメッセージは、まさにそうした本番運用上の問題を直接的に狙ったものです。
実務上の結論は単純です:GPT-5.6 Sol Ultraは、複数タスクを調整し、製品エコシステムに深く統合されるようなAIシステムを求める開発者にとってより魅力的かもしれません。Claude Opus 4.7は、慎重な実行、強力なコンテキスト管理、そして長期の専門的ワークフローでの推論上の驚きを減らすことを重視するチームにとってより好ましい選択かもしれません。
ベンチマーク比較:どのAIモデルがより賢いか?

ベンチマークは有用ですが、正しく解釈される場合に限ります。リーダーボードの数値は製品適合性と同じではありません。あるモデルはベンチマークで高得点を取っても、実際のワークフローではフラストレーションを招くことがあります。別のモデルは合成テストでやや劣るかもしれませんが、指示に従う能力、ツールの使用、長いタスクにわたるコンテキスト維持において優れていることがあります。
GPT-5.6 Sol Ultraについて正直に言えば、独立した公開結果はまだ限られています。モデルが限定プレビューの文脈で導入されたため、広範なサードパーティのベンチマークカバレッジはまだ安定していません。したがって、GPT-5.6 Sol Ultraがあらゆるベンチマークで正確に普遍的にランク付けされていると断言する記事は、実際の公開リーダーボードや公式の評価リリースへのリンクがない限り慎重に扱うべきです。
Claude Opus 4.7については、より多くの公開資料があります。Anthropic自身の発表には、コーディング、リサーチエージェントタスク、データ分析、複数ステップのワークフローに関する初期テスターのフィードバックが含まれています。GitHubもClaude Opus 4.7をGitHub Copilotに展開していると発表しており、初期テストでは複数ステップタスクの性能向上や、エージェント的な実行の信頼性向上が示唆されています。これらは中立的な学術ベンチマークと同じものではありませんが、実際のワークフローが重要となる開発者向けプロダクト文脈から得られているため意味があります。
SWE-benchやArtificial Analysisといった独立系ベンチマークサイトは、外部の文脈を提供するという点で重要です。SWE-benchは人手でフィルタリングされたVerifiedサブセットを含む、実際のソフトウェア工学上の課題に焦点を当てています。Artificial Analysisは、知能、速度、価格、出力トークン、およびタスク当たりコストのような指標でモデルを比較します。これらのプラットフォームは、マーケティング上の主張と測定可能な振る舞いを切り分けるのに役立つため価値があります。しかし同時に注意も必要です:ベンチマーク結果は、支援構造(スキャフォールディング)、ツールへのアクセス、プロンプト設計、エージェントフレームワーク、評価ルールに依存します。
ベンチマークの状況を読み解く最良の方法は「GPTが勝ち」あるいは「Claudeが勝ち」と単純化することではありません。代わりに、カテゴリ別に考えてください:
-
推論ベンチマークはモデルが難しい問題を解けるかを評価するが、実運用ツールとしての利用を反映しない場合がある。
-
コーディングベンチマークはソフトウェアの修復や生成を評価するが、結果はエージェントのスキャフォールド(枠組み)に大きく依存する。
-
長文コンテキストベンチマークは大規模な入力にまたがる検索や統合を評価するが、実際のプロジェクトは乱雑なファイル、矛盾する要件、不完全な情報を含む。
-
エージェントベンチマークは実務に近いが、依然として急速に進化している。
-
コストベンチマークは重要で、5%優れていても3倍高価なモデルは本番運用では不利になり得る。
今日、厳密なベンチマークの結論が必要なら、Claude Opus 4.7は現時点で公開情報に基づく裏付けがより多い。Anthropicが公式の詳細を公開し、エコシステムのパートナーがその性能について言及しているためだ。GPT-5.6 Sol Ultraはサブエージェントのオーケストレーションに関して戦略的に有望性が高いが、独立した検証はまだ追いついていない。その差はプレビューの拡大に伴い速やかに縮まる可能性がある。
コーディング比較:開発者向け GPT-5.6 Sol Ultra vs Claude Opus 4.7

コーディングはフロンティアモデルにとって最も重要な戦場の一つだ。開発者はモデルを頻繁に使い、プレミアムツールに対価を支払い、モデルを難しい実務タスク(レガシーシステムのリファクタリング、フレークするテストのデバッグ、アーキテクチャ設計、未知のコードベースの読み取り、マイグレーション作成、テストケースの生成、IDE内での操作など)に投入する。
Claude Opus 4.7は、AnthropicとGitHubがともにソフトウェアエンジニアリングワークフローの文脈で位置づけているため、現時点でコーディングにおける信頼性で明確な公的優位性を持つ。Anthropicの発表には、初期テスターからのフィードバックとしてより良い計画立案、ツールエラーの減少、複雑なコーディングワークフローにおける性能向上が含まれている。GitHubの変更ログにはOpus 4.7がGitHub Copilotに展開されていると記され、マルチステップタスク、長期的推論、ツール依存ワークフローの改善が説明されている。開発者にとっては、単一のコードスニペットデモよりもこちらの方が重要だ。
Claudeがコーディングでよく機能する理由は、単にコードを書くからだけではない。多くのモデルがコードを書けるが、難しいのはプロジェクトの既存アーキテクチャを理解し、スタイルを維持し、制約に従い、最小限の変更で済ませ、失敗を診断し、過度に設計しない判断をすることだ。Claudeの慎重なスタイルはここで有用で、問題を順を追って考え、トレードオフを説明し、解決に急ぎすぎない傾向がある。大規模なコードベースでは、その慎重さがむしろ利点になることがある。
GPT-5.6 Sol Ultraのコーディングに関する話はやや異なる。公的な報告ではGPT-5.6 Solが特にコーディングや長期的なエージェント的タスクに優れていると強調されている。もしUltraモードがサブエージェントのオーケストレーションを実際に改善するなら、このモデルは並列的な推論を必要とするコーディングワークフローで非常に強力になり得る:あるサブエージェントがテストを読み、別のサブエージェントが実装を検査し、別のサブエージェントがドキュメントを検索し、別のサブエージェントがパッチを提案し、別のサブエージェントがエッジケースを検証する。このような構成は現代のAI活用ソフトウェア工学にとって非常に関連性が高い。
IDE内で作業する一人の開発者にとって、既存のコードベースを読み書きするタスクではClaude Opus 4.7の方がより信頼できると即座に感じられるかもしれない。自動化されたコーディングエージェントを作るプラットフォームビルダーにとっては、アーキテクチャがオーケストレーションを志向していることからGPT-5.6 Sol Ultraの方が興味深いことがある。しかし、独立したコーディングベンチマークや実際の開発者の報告がもっと広まるまでは、正しい結論はGPT-5.6がすでにClaudeに勝った、ということではない。正しい結論は、両モデルが異なるコーディングワークフローに最適化されている可能性がある、ということだ。
Claude Opus 4.7 がコーディングで強い可能性のある領域
-
多数の制約を抱える大規模なコードベースを理解すること。
-
長時間のセッションにわたり詳細な指示に従うこと。
-
トレードオフを説明し、裏付けのない仮定を避けること。
-
Claude Code や GitHub Copilot といった統合環境内での作業。
-
注意深いコンテキスト処理が重要となる複雑なリファクタリング。
GPT-5.6 Sol Ultra がコーディングで強い可能性のある領域
-
複数のツールやサブエージェントを利用するエージェント型のコーディングシステム。
-
計画、実行、検証のループを必要とする自動化ワークフロー。
-
OpenAIネイティブの開発者向けプロダクトやAPIベースのコーディングエージェント。
-
コード、ドキュメント、ログ、スクリーンショットなどのマルチモーダルなコンテキストを組み合わせるタスク。
-
より広いAIプロダクトエコシステム内での高速な反復。
「Cursor、Claude Code、Copilot、あるいは社内のコーディングエージェントではどのモデルを使うべきか?」という問いなら、答えは実リポジトリで両方をテストすることだ。5つのタスクを使う:バグ修正1件、リファクタ1件、機能追加1件、テスト生成タスク1件、アーキテクチャ説明1件。コードがコンパイルするかだけでなく、何ターンかかるか、何ファイルに触れるか、スタイルを守っているか、APIを勝手に作り出していないかを測定せよ。それがリーダーボードよりも多くを教えてくれる。
推論能力:深い思考と実務的な知性
推論(reasoning)はAIマーケティングで最も使い古された語だ。最先端とされるモデルは皆、より優れた推論を主張する。より有益なのは次の問いだ:モデルはどのような種類の推論を得意とするのか?
GPT-5.6 Sol Ultraの推論に関する説明はモードに結びつく。公表されている報道では、Solにはより深い推論を行うMaxモードと、サブエージェントのオーケストレーション用のUltraモードが含まれるという。これは困難なタスクに対してより多くの計算資源と構造を割り当てるよう設計されたモデルを示唆する。ユーザーの観点では、これがより良い計画立案、強力な分解(タスクの分割)、ツール間の調整の改善、難問に対する浅い回答の減少として現れるかもしれない。
Claude Opus 4.7の推論に関する説明は規律に結びつく。Anthropicが公開する例は、計画の段階で論理的欠陥を検出すること、欠落データを正しく報告すること、罠に抵抗すること、ツールの失敗を乗り越えて作業を続けることを強調している。その種の推論はプロの仕事において非常に価値がある。単にパズルを解くことではない。どの証拠が存在するか、何が欠けているか、何が推論できるか、そして何を主張すべきでないかを知ることなのだ。
Apply this research method to your stock
Generate bull/bear views, risk notes, and an evidence trail for GPT.
ユーザーにとって、その違いは次のように感じられるかもしれない:GPT-5.6 Sol Ultraは複雑なワークフローを調整できる高エネルギーなストラテジストのように振る舞う可能性が高く、一方でClaude Opus 4.7は弱い仮定から守る注意深いシニアアナリストのように振る舞う可能性が高い。どちらのスタイルも有用である。どちらが最適かは、誤ることのコスト次第だ。
製品戦略をブレインストーミングしている場合、AIエージェントのワークフローを構築している場合、あるいは複数の選択肢を迅速に生成している場合は、GPT-5.6 Sol Ultraがより強力なクリエイティブエンジンかもしれません。契約書をレビューしている場合、長大な財務報告書を分析している場合、データパイプラインを検証している場合、あるいは本番環境のインシデントを調査している場合は、Claude Opus 4.7の慎重さの方が価値があるかもしれません。
最も高度な推論システムは最終的に両方のスタイルを組み合わせるでしょう:大胆な分解と慎重な検証。だからこそエージェントワークフローが重要なのです。優れたAIシステムは一つのモデルの性格に依存してはなりません。あるモデルで仮説を生成し、別のモデルでそれに異を唱え、さらに別のモデルで情報源を検証し、別のモデルで結果を実行可能な意思決定に変えるべきです。これは、根拠のない自信に満ちた結論が高くつくことがある金融リサーチでは特に重要です。
長いコンテキストと文書作業
長いコンテキストはClaudeの最も強いブランド連想の一つです。Claudeモデルは文書、契約書、コードベース、研究論文、業務報告書の閲読に広く使われてきました。Claude Opus 4.7は長いコンテキストの一貫性とプロフェッショナルなナレッジワークを強調することでその傾向を引き継いでいます。Anthropicの発表には、データ規律、欠落データの開示、強力な長コンテキスト性能を称賛するテスターのフィードバックが含まれています。
長いコンテキストは単にウィンドウの大きさだけではありません。百万トークンのコンテキストウィンドウは印象的に聞こえますが、重要なのはモデルがコンテキストを正しく使えるかどうかです。関連する詳細を見つけられるか?無関係なテキストに気を取られないか?矛盾する情報源を調整できるか?答えが存在しないときにユーザーに伝えられるか?タスクの開始時から終了時まで制約を保持できるか?
Claude Opus 4.7は入力が長く、散逸しており、重要なタスクに特に適しているように見えます。例としては、法務レビュー、政策分析、投資メモ、技術文書、カスタマーサポートのナレッジベース、デューデリジェンスフォルダ、コンプライアンスマニュアル、大規模なコードリポジトリなどが挙げられます。こうした状況では、幻覚(ハルシネーション)の制御とコンテキストの規律がスピードより重要になることがあります。
長いコンテキストがより広いワークフローの一部である場合、GPT-5.6 Sol Ultraの方が魅力的かもしれません。例えば、長いレポートを単に読むのではなく、エージェント的なシステムがレポートを要約し、主要指標を抽出し、それらを市場データと比較し、最近のニュースをチェックし、投資仮説を生成し、リスク要因を議論し、最終的な見解を作成するかもしれません。Ultraモードのサブエージェントのオーケストレーションがうまく機能すれば、GPT-5.6はこの種のマルチソースワークフローで強力になり得ます。
つまり区別は「長いコンテキストにはClaude、その他はGPT」という単純なものではありません。より正確には、Claude Opus 4.7は注意深い長コンテキストの読解と根拠ある統合に強く、GPT-5.6 Sol Ultraはオーケストレーション、ツールの使用、段階的な実行を要する長コンテキストワークフローに強い可能性がある、ということです。
AIエージェントの性能:真の違い
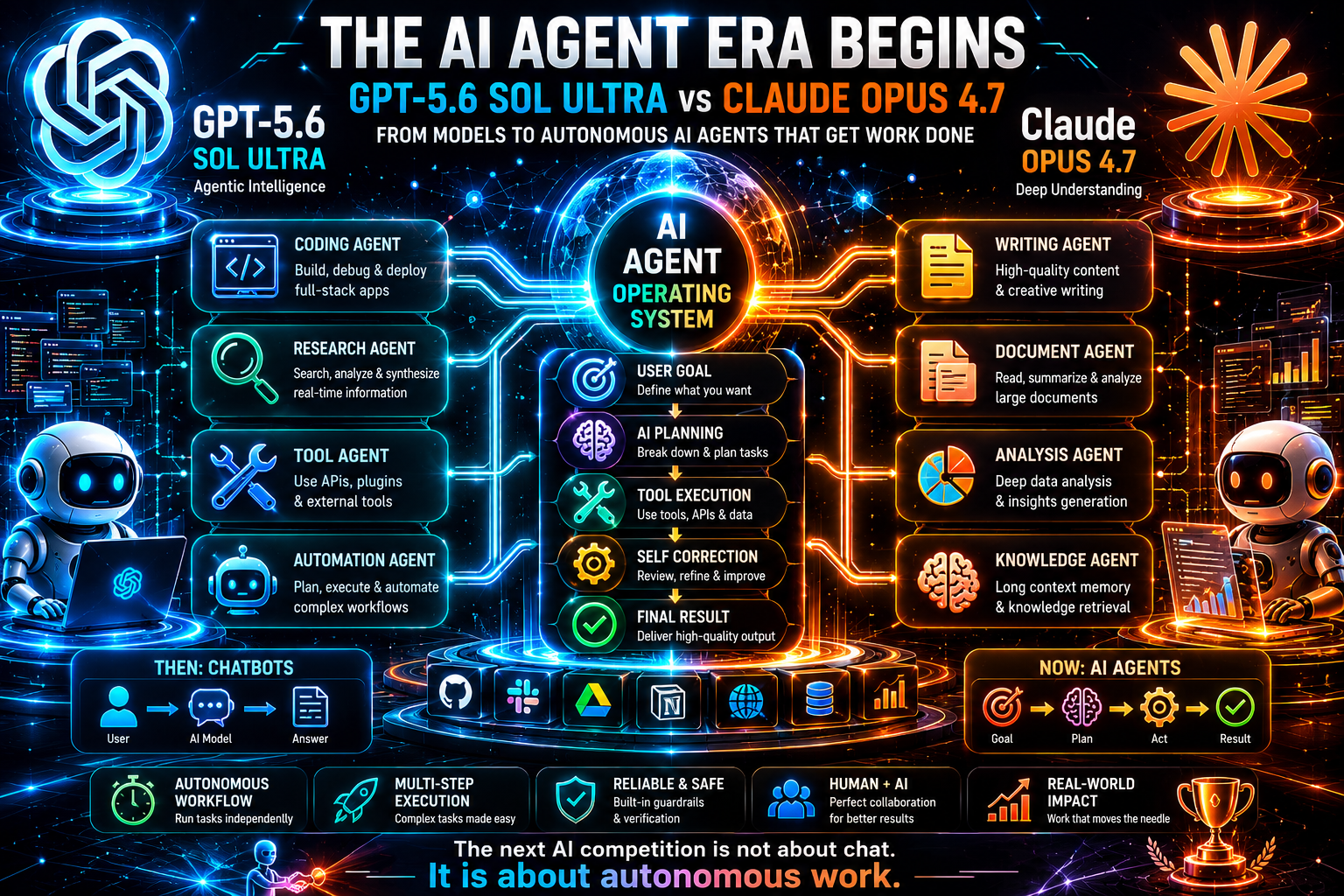
この比較で最も重要なカテゴリはAIエージェントのパフォーマンスです。ここが市場の向かう先です。チャットボットは有用ですが、生産性向上が測定可能になるのはエージェントの領域です。AIエージェントは目標を受け取り、手順を立て、ツールを呼び出し、APIを使用し、出力を検査し、計画を修正し、タスクが完了するか人の判断が必要になるまで継続できます。
GPT-5.6 Sol Ultra の最も強いストーリーはエージェンシックなオーケストレーションです。Ultraモードの説明はサブエージェントを示唆しており、これは高度なAIシステム設計における最重要パターンの一つです。単一のモデルコールは強力ですが、複雑な作業は研究者、批評家、コーダー、テスター、リスクアナリスト、要約者、意思決定エージェントといった専門化された役割から恩恵を受けます。GPT-5.6 Sol Ultra がその構造に最適化されているなら、次世代のAI製品の強力な基盤になり得ます。
Claude Opus 4.7 の最も強いストーリーはエージェンシックな信頼性です。Anthropic と GitHub はいずれもマルチステップのタスク実行、長時間にわたる作業、ツール依存のワークフロー、失敗の少なさを強調しています。本番環境では、信頼性はしばしば生の野心より価値が高いです。やりすぎて沈黙のうちに壊れるエージェントは危険です。慎重に進み、不確実性を報告し、ツールの失敗から回復できるエージェントのほうが信頼しやすいです。
これは開発者にとって有用な区別を生みます:
-
GPT-5.6 Sol Ultra を使用する エージェントが広範なオーケストレーション、複数の専門的なステップ、OpenAI ネイティブのワークフローとの統合を必要とする場合。
-
Claude Opus 4.7 を使用する エージェントが慎重なコンテキスト処理、長時間のコーディングや調査、複雑な制約下での信頼性の高い実行を必要とする場合。
-
両方を使用する タスクの価値が高い場合:一方のモデルが生成と計画を行い、もう一方が批評、検証、または書き直しを担当する。
AIエージェントの未来は、あるモデルが他のすべてのモデルを置き換えることではありません。インテリジェントなルーティングです。プラットフォームはワークフローの各段階に最適なモデルを選択します。分類にはより安価なモデル、抽出には高速なモデル、長文解析にはClaude、オーケストレーションにはGPT、リポジトリ変更には専門のコーディングモデルを使うかもしれません。勝つ製品は単に最大のモデルを持つ製品ではなく、最良のワークフローデザインを持つ製品になります。
価格比較:どのモデルがより価値を提供するか?

価格は比較を具体的にする部分です。公開情報に基づくと、GPT-5.6 Sol は入力トークン100万あたり$5、出力トークン100万あたり$30で価格設定されています。Anthropic は Claude Opus 4.7 を入力トークン100万あたり$5、出力トークン100万あたり$25としています。これらの数字が導入時の価格基準であれば、出力トークンでは Claude Opus 4.7 のほうが安価です。
モデル 入力価格 出力価格 価格の要点 GPT-5.6 Sol $5 / 1M tokens $30 / 1M tokens Opus 4.7 と同じ入力価格だが、公開情報に基づくと出力価格が高い。 Claude Opus 4.7 $5 / 1M tokens $25 / 1M tokens 出力価格が低く、トークン使用を管理できれば長時間のコーディングやドキュメントワークフローに適している。
しかし、トークン単価だけが実際のコストを決めるわけではありません。実際のコストは出力の長さ、コンテキストサイズ、プロンプトのキャッシュ、リトライ率、ツール呼び出し、レイテンシ、そしてモデルが一度で正しい答えを出す頻度に依存します。安いモデルでもリトライが多ければ高くつきますし、より高価なモデルが呼び出し回数を減らしてタスクを完了できれば安く済むこともあります。コーディングエージェントの場合、最大のコスト要因はしばしば初期プロンプトではなく、反復ループです:ファイルを検査し、変更を提案し、テストを実行し、エラーを読み、修正し、これを繰り返すことです。
Business Insiderは、AnthropicがClaude Codeのトークン消費見積もりを更新し、平均的なエンタープライズ開発者のコストはアクティブな日あたり約$13、開発者1人あたり月$150〜$250で、ユーザーの90%がアクティブな日あたり$30未満だと報じました。重要なのはClaudeが特別に高価だということではありません。重要なのはAIエージェントの利用がコスト構造を変えるという点です。モデルが回答エンジンではなく“働き手”になると、より多くの作業を行うためにトークンを多く消費します。
実運用チームにとって、価格の問題は完了したワークフローあたりのコストとして捉えるべきです。例えば:
-
サポートチケット1件を解決するのにいくらかかるか?
-
バグ1件を修正するのにいくらかかるか?
-
投資ブリーフ1件を作成するのにいくらかかるか?
-
決算説明会1回を分析するのにいくらかかるか?
-
株式1銘柄を1週間監視するのにいくらかかるか?
このようにコストを測定すれば、最適なモデルはタスクごとに異なる可能性があります。Claude Opus 4.7は出力トークン単価が低く、文体が手戻りを減らす可能性があるため、長いコンテキストを慎重に扱う出力ではコスト効率が良いことがあります。GPT-5.6 Sol Ultraは、オーケストレーションによって人的な調整時間が削減されるワークフローではよりコスト効率が良いかもしれません。確実に知る唯一の方法は、実際のプロンプト、実際のファイル、実際の成功基準を用いてタスクレベルの評価を実施することです。
開発者体験:Claude Code、GitHub Copilot、API、およびエージェントフレームワーク
モデルの品質は重要ですが、採用を左右するのは開発者体験です。若干優れていても統合が難しいモデルは、既存のワークフローに自然にフィットするモデルに負けることがあります。だからこそ、Claude Code、GitHub Copilot、ChatGPT、APIツール、エージェントフレームワークが重要なのです。
Claude Opus 4.7は、ユーザーが既に作業している開発環境に統合されていることから恩恵を受けます。GitHubがOpus 4.7をCopilotに展開すると発表したことで、世界で最も重要なコーディング製品の一つ内での流通が得られます。Claude Codeはまた、Anthropicにエージェント的なソフトウェアエンジニアリングのための直接的なインターフェースを提供します。生のAPIではなく、強力なコーディングパートナーを望む開発者にとっては、これは重要です。
GPT-5.6 Sol UltraはOpenAIの広範なエコシステムから恩恵を受けます。ChatGPTは主流のAIインターフェースであり、OpenAIのAPIは開発者の強い支持を得ており、同社のプロダクト方針はツールやマルチモーダルワークフロー、エージェント的なアプリケーションをますますサポートしています。もしあなたのチームが既にOpenAIのAPI上で構築しているなら、GPT-5.6 Sol Ultraはアップグレードの道として導入しやすいかもしれません。
開発者体験に関する問いには次の点を含めるべきです:
-
モデルはチームがすでに使用しているツール内で機能しますか?
-
社内ツールを安全に呼び出すことができますか?
-
トークン使用量とワークフローの成功を監視できますか?
-
モデル間でタスクをルーティングできますか?
-
セキュリティ、プライバシー、およびコンプライアンスのためのガードレール(安全策)を追加できますか?
-
モデルは自分が何を行ったか、なぜ行ったかを説明できますか?
内部のAIプラットフォームでは、単一モデルにこだわるよりもモデルルーターが最適な場合があります。綿密な読解や長いコンテキストでのコードベース推論を要するタスクには Claude Opus 4.7 を使用します。計画中心でツールを多用するマルチエージェントのオーケストレーションには GPT-5.6 Sol Ultra を使用します。抽出、分類、反復的な作業にはより安価なモデルを使います。このアーキテクチャは、すべてを一つの最先端モデルに賭けるよりも耐久性があります。
調査と分析:どのモデルが複雑な情報をよりよく扱えるか?
調査は、AIモデルが大きなレバレッジを生み出せる領域です。人間のアナリストはレポート、提出書類、議事録、ニュース、フォーラムの議論、市場データ、社内文書などを読むのに何時間も費やすことがあります。優れたAIモデルはそのプロセスを圧縮できます。しかし、品質の低いAIリサーチシステムは自信満々のナンセンスを生み出しかねません。
Claude Opus 4.7 は、長いコンテキストの規律と欠損データの慎重な扱いにより、リサーチタスクに強みがあります。Anthropic の発表には、テスターのフィードバックとしてより良い開示とデータの取り扱いが記載されています。これは研究において重要です。なぜなら、最も危険な誤りは明白な幻覚(hallucination)ではなく、もっともらしく聞こえるが裏付けのない微妙な推論であることが多いからです。
GPT-5.6 Sol Ultra は、そのエージェント志向性のため、リサーチワークフローに強みを持つ可能性があります。リサーチは単に読むだけではありません。適切な質問を投げかけ、情報源を集め、視点を比較し、矛盾を特定し、仮説を更新し、次に監視すべきシグナルを決めることです。Ultra モードがサブエージェントの調整を改善するならば、GPT-5.6 は複数のエージェントに作業を分担させるリサーチシステムで特に有用になり得ます。
例えば、ファイナンシャルリサーチのワークフローは次を含むかもしれません:
-
最近の企業動向を収集するニュース・エージェント。
-
売上高、マージン、負債、ガイダンスの変化を抽出する開示資料エージェント。
-
価格の動き、出来高、ボラティリティ、セクターの動きを確認するマーケット・エージェント。
-
強気の仮説に異議を唱えるリスク・エージェント。
-
マルチプルや前提を比較するバリュエーション・エージェント。
-
意思決定可能なブリーフを作成する最終合成エージェント。
ここで GPT-5.6 Sol Ultra と Claude Opus 4.7 の双方が価値を発揮する可能性があります。GPT はワークフローを調整し、Claude は証拠を批評し、別のモデルが安価に構造化された数値を抽出するかもしれません。最終成果物はチャットボットの回答ではなく、AIネイティブなリサーチプロセスです。
なぜAIネイティブな投資リサーチが可能になりつつあるのか
投資リサーチは、なぜAIモデルの競争がワークフローの競争になりつつあるかを示す典型例です。投資家は単に答えを求めているわけではありません。不確実性の下での構造化された思考が必要です。何が変わったのか、なぜそれが重要なのか、どの証拠が仮説を支持しているのか、何が間違っている可能性があるのか、次に監視すべきシグナルは何かを知る必要があります。
従来の金融リサーチツールはしばしば静的です。チャート、各種比率、見出し、アナリストの評価、開示資料を表示します。これらは有用ですが、ユーザーが手作業で点と点を結びつける必要があります。どの情報が重要か、どのリスクが過小評価されているか、どのナラティブが変化しているか、どのデータポイントがコンセンサスに矛盾しているかをユーザー自身が判断しなければなりません。
AIエージェントはそれを変え得ます。リサーチエージェントは決算書の書き起こしを読めます。リスクエージェントは前提に異議を唱えることができます。バリュエーションエージェントはシナリオを比較できます。ニュースエージェントは触媒(カタリスト)を追跡できます。モニタリングエージェントは仮説を破る出来事を監視できます。ディベートエージェントは強気・弱気の議論をシミュレートできます。これは人間の判断を置き換える話ではありません。人間の投資家により良いリサーチのオペレーティングシステムを提供することです。
ここに AlphaVue.ai のようなプラットフォームがより広いAIシフトの中で位置づけられます。次世代の投資プラットフォームは単にデータを表示するだけではありません。ユーザーがデータを論理的に解釈するのを支援します。市場情報をワークフローに変換します:スキャン、リサーチ、ディベート、比較、モニター、そして意思決定。GPT-5.6 Sol Ultra と Claude Opus 4.7 が重要なのは、どちらか一方のモデルが永続的に他方を打ち負かすからではなく、両者が市場がどれだけAIネイティブな投資インテリジェンスに近づいているかを示しているからです。
投資家にとって、重要な疑問はもはや「AIはこの銘柄を要約できるか?」ではありません。それは当たり前の水準です。本当に問うべきは、AIが私にとって何が重要か、何が変わったのか、何が織り込まれているのか、何が不確実か、そして次に何をすべきかを理解する手助けをしてくれるか、です。これはエージェント的なワークフロー、モデルルーティング、情報源の規律、透明な推論を必要とします。またプロダクト設計も必要です。優れたモデルでも良いワークフローがなければ、検索もアラートも構造もないブルームバーグ端末のようなものです。
AlphaVue.aiの視点:AIモデルからAI投資エージェントへ
金融リサーチの未来は一つの巨大なチャットボットではありません。企業を調査し、市場シグナルを比較し、強気と弱気のケースを検証し、投資家が重要事項を監視するのを支援する専門化されたAIエージェントのネットワークになるでしょう。AlphaVue.aiはこのAIネイティブな投資ワークフローのために構築されています:より賢いリサーチ、明確な意思決定、そしてより迅速な洞察。
実用的なユースケース:どのモデルを選ぶべきか?
GPT-5.6 Sol Ultra と Claude Opus 4.7 の間に普遍的な勝者はありません。どちらが適切かは用途によります。ここに実務的な意思決定フレームワークを示します。
次の場合は GPT-5.6 Sol Ultra を選んでください:
-
計画、ツール使用、オーケストレーションを必要とするAIエージェントを構築している場合。
-
すでに OpenAI のAPIを使用しており、フロンティアのアップグレードパスを望む場合。
-
ワークフローがテキスト、コード、構造化データ、場合によってはマルチモーダル入力を組み合わせている場合。
-
モデルに専門的なサブタスクの調整をさせたい場合。
-
エコシステム統合とプロダクトのスピードを重視する場合。
次の場合は Claude Opus 4.7 を選んでください:
-
長いコンテキストの精読と文書解析が必要です。
-
コードベース、リファクタリング、複雑なエンジニアリング作業を多く扱います。
-
慎重な推論と欠落データの開示を重視します。
-
Opus 4.7 をサポートする Claude Code や GitHub Copilot の統合を利用しています。
-
公表された料金に基づき、出力トークンの価格がやや低いことを望んでいます。
両方を併用すべき場合:
-
クロスモデル検証を正当化するほど価値の高いタスクである場合。
-
一方のモデルが生成し、別のモデルが批評する必要がある場合。
-
モデルルーティングを備えた本番用AIプラットフォームを構築している場合。
-
単一モデルの失敗モードを減らしたい場合。
-
創造性と慎重さの両方を重視する場合。
最も洗練されたチームは「どのモデルが最良か?」とは尋ねません。彼らは「どのモデルがどの工程を担当すべきか?」と問います。これは2026年に向けて正しい問いです。AIはモデル選択をブランドの好みとして扱うにはあまりにも重要になっています。
最終判定:GPT-5.6 Sol Ultra と Claude Opus 4.7 どちらか?

簡潔な答えを求めるなら、こうです: Claude Opus 4.7 は、慎重なコーディング、長いコンテキストを扱うリサーチ、そして規律あるプロフェッショナルなワークフローにおいて現時点でより安全な選択です。一方で GPT-5.6 Sol Ultra は、エージェント的なオーケストレーションや OpenAI ネイティブの AI システムにとって、戦略的により刺激的な選択です。
Claude Opus 4.7 は現状でより公開された裏付けがあります。Anthropic は公式の価格と提供状況を公表しており、GitHub は Copilot での展開について言及しています。初期テスターのフィードバックは、実業務で重要な能力――複数ステップの実行、ツールエラーの減少、より強力な計画立案、そして長いコンテキストでの性能向上――を強調しています。もしあなたのチームが今日、コーディングやリサーチのワークフローに使うモデルを必要としているなら、Claude Opus 4.7 は真剣な検討に値します。
GPT-5.6 Sol Ultra は、独立したベンチマークの報道がまだ限られているため、確実に評価するのは難しいです。しかし、その方向性は重要です。フラッグシップ推論、Max モード、Ultra モード、サブエージェントのオーケストレーションの組み合わせは、AI が向かう先――単に質問に答えることから、仕事を調整・運営することへ――を示しています。OpenAI がこれをうまく実行できれば、GPT-5.6 Sol Ultra はエージェントネイティブ製品における最も重要なモデルの一つになる可能性があります。
真の勝者はどちらか一方のモデルだけではないかもしれません。真の勝者は、適切なタイミングで適切なモデルを使うワークフローレイヤーです。コーディングでは、読み取り、パッチ、テスト、説明ができるエージェントを意味します。リサーチでは、情報を収集し、検証し、議論し、監視できるシステムを意味します。投資では、市場データを構造化されたインテリジェンスに変えるプラットフォームを意味します。
したがって、GPT-5.6 Sol Ultra と Claude Opus 4.7 の比較は単なるモデル比較ではありません。次の AI プラットフォーム戦争の予告編です。将来は、推論、ツール、メモリ、検証、ワークフローデザインを組み合わせたシステムのものになるでしょう。最も賢いチャットボットが勝つわけではありません。最も役に立つ AI ワーカーが勝ちます。
FAQ: GPT-5.6 Sol Ultra と Claude Opus 4.7
GPT-5.6 Sol Ultra は Claude Opus 4.7 より優れているか?
一概には言えません。GPT-5.6 Sol Ultraはエージェンシー的なオーケストレーションやOpenAIネイティブのワークフローにより重点を置いているように見えますが、Claude Opus 4.7は注意深いコーディング、長文コンテキスト処理、信頼できる複数ステップの実行に関して公的な実績がより強いです。どちらが優れているかは用途次第です。
コーディングにはどちらのモデルが向いているか?
現在、Claude Opus 4.7はコーディングに関する公的な信頼性が高いです。AnthropicやGitHubがそのコーディング性能やエージェンシー型の開発者ワークフローでの実績を強調しているためです。GPT-5.6 Sol Ultraは、特にUltraモードがサブエージェントのオーケストレーションを改善すれば、エージェンシー型コーディングシステムで非常に競争力を持つ可能性があります。
どちらが安いか?
公開されている価格に基づくと、両モデルとも入力トークンあたり100万トークンで$5とされています。Claude Opus 4.7は出力トークン100万あたり$25、公開報道ではGPT-5.6 Solは出力トークン100万あたり$30とされています。実際のコストはリトライ回数、出力長、ツールの使用、キャッシュ、ワークフローの成功率などによって変わります。
AIエージェントにはどちらが向いているか?
Ultraモードがサブエージェントを念頭に置いていると説明されているため、GPT-5.6 Sol Ultraはエージェントのオーケストレーションにおいてより興味深い選択肢かもしれません。一方でClaude Opus 4.7は、特にコーディングやドキュメント中心のワークフローにおいて、信頼性の高い長時間実行のエージェントに適している可能性があります。価値の高いユースケースでは、モデルルーターを使って両方を併用するのが最良です。
スタートアップはどちらを選ぶべきか?
スタートアップはワークフローの経済性に基づいて選ぶべきです。製品がOpenAIエコシステムの統合やマルチエージェントのオーケストレーションに依存するなら、GPT-5.6 Sol Ultraを試してください。製品が長文コンテキシングの推論、コーディングの信頼性、慎重な分析に依存するなら、Claude Opus 4.7を試してください。本番運用では、すべてを一つのモデルで賄うのではなく、モデルの強みに応じてタスクをルーティングしてください。
投資リサーチにはどちらが向いているか?
長い開示書類を読み、慎重な分析を行う点ではClaude Opus 4.7が優れている可能性があります。ニュースを収集し、財務データを比較し、リスクを議論し、投資仮説の変化を監視するようなマルチエージェントのリサーチワークフローではGPT-5.6 Sol Ultraが強みを発揮するかもしれません。最良の投資リサーチシステムは、複数のモデルと専門エージェントを組み合わせることになるでしょう。