
GPT-5.6 Sol Ultra e Claude Opus 4.7 representam duas visões diferentes da IA de ponta. Um é posicionado em torno de orquestração orientada a agentes, modos de raciocínio profundo e o ecossistema de produtos em expansão da OpenAI. O outro é construído em torno de execução cuidadosa, trabalho com contexto longo, confiabilidade na codificação e disciplina de fluxos de trabalho em nível empresarial. A verdadeira pergunta não é mais simplesmente “qual modelo é mais inteligente?” É “qual modelo se encaixa na forma como você realmente trabalha?”
A corrida por modelos de IA mudou. Há um ano, a maioria das comparações de modelos focava na qualidade das respostas: qual modelo escreveu o melhor ensaio, resolveu o enigma mais difícil, resumiu o PDF mais longo ou produziu o trecho de código mais limpo. Isso ainda importa, mas já não é suficiente. Em 2026, a linha de frente está se deslocando para sistemas de IA que podem planejar, usar ferramentas, gerenciar contexto, recuperar-se de erros e continuar trabalhando em objetivos de múltiplas etapas. O modelo mais valioso nem sempre é aquele que fornece a resposta única mais impressionante. Frequentemente é o modelo que consegue completar o fluxo de trabalho mais útil com o mínimo de atrito.
Por isso a comparação entre GPT-5.6 Sol Ultra e Claude Opus 4.7 é interessante. Esses modelos não são apenas atualizações de chatbots. São candidatos a se tornarem a camada de inteligência por trás de agentes de engenharia de software, copilotos de pesquisa, sistemas de análise financeira, automações empresariais e fluxos de trabalho de suporte à decisão. Para desenvolvedores, a questão passa a ser se GPT-5.6 Sol Ultra ou Claude Opus 4.7 é melhor para codificar, depurar, arquitetar e executar de forma agentiva. Para empresas, a questão é qual modelo oferece melhor valor por dólar. Para investidores e analistas, a pergunta é qual modelo consegue transformar informação ruidosa em insight estruturado.
Este artigo compara os dois modelos com base em informações públicas, precificação, casos de uso em codificação, comportamento de raciocínio, contexto de benchmarks, fluxos de trabalho para desenvolvedores, desempenho de agentes de IA e cenários de pesquisa no mundo real. Onde existem números públicos confiáveis, os utilizamos. Onde a cobertura independente de benchmarks ainda é limitada, especialmente para o GPT-5.6 Sol Ultra durante seu período inicial de prévia, evitamos fingir que rankings exatos já estão definidos. Uma boa comparação de IA deve ajudar as pessoas a tomar decisões melhores, não fabricar uma certeza falsa.
Nota importante sobre as fontes: GPT-5.6 Sol Ultra ainda está no início do ciclo público. As reportagens públicas mais úteis descrevem o GPT-5.6 como um conjunto de modelos em prévia limitada, com Sol como carro‑chefe, além de modos Max e Ultra para raciocínio mais profundo e orquestração de sub‑agentes. Claude Opus 4.7 tem informações oficiais mais diretas da Anthropic, incluindo disponibilidade de API, preços e feedback de testadores. Esta comparação, portanto, separa dados confirmados de interpretações práticas.
A corrida pela IA mudou: de chatbots para agentes inteligentes

A maneira mais fácil de interpretar erroneamente GPT-5.6 Sol Ultra vs Claude Opus 4.7 é tratar a comparação como um simples concurso de chatbots. Essa abordagem está desatualizada. Os melhores modelos não estão mais competindo apenas para ver se conseguem escrever um parágrafo melhor ou responder a uma pergunta de trivia. Eles competem para ver se conseguem operar como trabalhadores inteligentes dentro de um sistema maior.
Na era dos chatbots, o usuário fazia a maior parte do trabalho. O usuário dividia o problema em partes, escrevia prompts cuidadosos, copiava a saída para outras ferramentas, verificava erros manualmente, fazia perguntas de seguimento e costurava a resposta final. O modelo era poderoso, mas passivo. Ele aguardava instruções.
Na era dos agentes, espera-se que o modelo faça mais da coordenação. Ele deve entender o objetivo, planejar os passos, reunir evidências, usar ferramentas, escrever ou modificar código, testar o resultado, inspecionar falhas, revisar sua abordagem e fornecer uma saída pronta para decisão. Isso não significa que a IA seja autônoma num sentido mágico. Significa que a unidade de valor está mudando de uma resposta para um fluxo de trabalho completo.
GPT-5.6 Sol Ultra parece projetado para essa mudança. Reportagens públicas descrevem o Sol como o carro-chefe da OpenAI na suíte GPT-5.6, com pontos fortes em codificação, cibersegurança, biologia e tarefas agentivas de longo prazo. O modo Ultra é especialmente notável porque é descrito como aproveitando subagentes. Essa moldura importa. A orquestração de subagentes sugere um modelo projetado não apenas para raciocinar em um único fluxo, mas para distribuir o trabalho por processos especializados internos ou externos.
Claude Opus 4.7 vem de uma direção diferente, mas igualmente importante. Os materiais públicos da Anthropic enfatizam fluxos de trabalho complexos de múltiplas etapas, codificação, uso de ferramentas, tarefas de longa duração, disciplina de dados, seguir instruções e consistência. Citações de primeiros testadores destacaram a habilidade do Claude Opus 4.7 de detectar falhas lógicas durante o planejamento, continuar diante de falhas de ferramentas e evitar soluções plausíveis porém sem suporte. Isso não é apenas "uma escrita melhor". Isso é confiabilidade no fluxo de trabalho.
Isso cria o contraste central: o GPT-5.6 Sol Ultra parece ser um modelo otimizado para orquestração e ecossistemas de agentes, enquanto o Claude Opus 4.7 parece ser um modelo otimizado para execução cuidadosa e confiável em trabalhos longos e complexos. O vencedor depende de o seu caso de uso valorizar integração ampla do ecossistema e flexibilidade agentiva, ou consistência em longos contextos e precisão conservadora.
GPT-5.6 Sol Ultra vs Claude Opus 4.7: Comparação Rápida
Antes de aprofundar em benchmarks e fluxos de trabalho, aqui está a comparação de alto nível. Esta tabela não tem a intenção de declarar um vencedor universal. Ela serve para esclarecer onde cada modelo parece mais forte com base nas informações públicas atuais e nos padrões práticos de uso.
Categoria GPT-5.6 Sol Ultra Claude Opus 4.7 Posicionamento principal Variante da suíte de modelos da OpenAI focada em raciocínio avançado, programação e fluxos de trabalho agentivos, com o modo Ultra descrito em torno da orquestração de sub-agentes. Modelo de ponta da Anthropic, Opus, focado em programação, trabalho com contexto longo, tarefas complexas, execução consistente e seguimento cuidadoso de instruções. Melhor aplicação Fluxos de trabalho com agentes, apps do ecossistema OpenAI, orquestração de ferramentas, pesquisa automatizada, experiências de IA multimodais e produtizadas. Documentos longos, tarefas complexas de codificação, análise cuidadosa, fluxos de engenharia empresarial, Claude Code e raciocínio estruturado. Codificação Candidato forte para codificação agentiva e depuração automatizada, especialmente quando as ferramentas da OpenAI são centrais. Posição pública muito forte em codificação e tarefas de software de longa execução; disponível no Claude Code e integrações com o GitHub Copilot. Preço Relatos públicos listam o GPT-5.6 Sol a $5 por milhão de tokens de entrada e $30 por milhão de tokens de saída durante o período de preview. A Anthropic afirma que o Claude Opus 4.7 permanece a $5 por milhão de tokens de entrada e $25 por milhão de tokens de saída. Certeza dos benchmarks Dados independentes de benchmark públicos ainda são limitados devido ao ciclo inicial de preview. Mais feedback público do ecossistema e reivindicações oficiais da Anthropic estão disponíveis; a cobertura de benchmarks independentes varia por teste. Capacidade de agente Potencialmente mais forte para orquestração de sub-agentes e fluxos de produtos de IA amplos. Potencialmente mais forte para execução confiável de longa duração e fluxos de trabalho dependentes de ferramentas. Melhor escolha prática Escolha-o quando quiser um sistema de agentes nativo da OpenAI, ampla integração ao ecossistema e modos de raciocínio de alto desempenho. Escolha-o quando desejar codificação disciplinada, raciocínio sobre documentos, confiabilidade em contexto longo e saídas cuidadosas.
Filosofia do Modelo: OpenAI Sol Ultra vs Anthropic Opus
A OpenAI e a Anthropic têm filosofias de produto diferentes, e essas diferenças aparecem no comportamento dos modelos. Os modelos de ponta da OpenAI cada vez mais parecem componentes de um sistema operacional de IA em expansão: ChatGPT, fluxos de API, entradas multimodais, uso de ferramentas, ambientes de codificação, integrações empresariais e superfícies de produto agentivas. O modelo não é apenas um cérebro. Ele faz parte de um sistema que busca lidar com mais do trabalho do usuário do começo ao fim.
O GPT-5.6 Sol Ultra segue essa direção. A marca "Sol" sugere o nível carro‑chefe, enquanto "Ultra" sugere o modo mais capaz para tarefas complexas. A expressão-chave é orquestração de sub-agentes. Na prática, os sistemas de IA mais avançados estão começando a parecer menos com um gerador único de respostas enormes e mais com um coordenador de trabalhadores especializados. Um agente pode inspecionar o código-fonte. Outro pode buscar documentação. Outro pode avaliar implicações de segurança. Outro pode resumir trade-offs. O modelo principal coordena esses esforços em um resultado final.
A filosofia do Opus da Anthropic parece mais centrada em inteligência confiável. Claude há muito tempo é reconhecido pela qualidade de escrita, compreensão de contexto longo e estilo cauteloso. O Claude Opus 4.7 estende esse padrão ao trabalho profissional. O anúncio da Anthropic enfatizou o feedback de testes de empresas de codificação, dados, pesquisa e fluxos de trabalho. A linguagem é menos sobre demonstrações chamativas e mais sobre menos erros em ferramentas, melhor planejamento, desempenho mais sólido em tarefas de longa duração e melhor transparência quando faltam dados.
Essa diferença importa porque muitas falhas de IA em produção não são causadas pela falta de inteligência bruta. São causadas por comportamento ruim no fluxo de trabalho. O modelo inventa informações ausentes. Para cedo demais. Falha silenciosamente. Segue a hierarquia de instruções errada. Usa ferramentas incorretamente. Muda a tarefa sem explicar por quê. Produz resultados impressionantes que, na verdade, não estão fundamentados nas evidências disponíveis. As mensagens da Anthropic sobre o Claude Opus 4.7 miram diretamente esses problemas de produção.
A conclusão prática é simples: o GPT-5.6 Sol Ultra pode ser mais empolgante para desenvolvedores que querem sistemas de IA capazes de coordenar múltiplas tarefas e se integrar profundamente a um ecossistema de produto. O Claude Opus 4.7 pode ser mais atraente para equipes que precisam de execução cuidadosa, forte gerenciamento de contexto e menos surpresas de raciocínio em fluxos de trabalho profissionais longos.
Comparação de benchmarks: qual modelo de IA é mais inteligente?

Benchmarks são úteis, mas somente se forem interpretados corretamente. Um número em um leaderboard não é a mesma coisa que adequação ao produto. Um modelo pode obter boa pontuação em um benchmark e ainda assim ser frustrante em um fluxo de trabalho real. Outro modelo pode ficar um pouco atrás em um teste sintético, mas ser melhor em seguir instruções, usar ferramentas ou manter o contexto ao longo de uma tarefa extensa.
No caso do GPT-5.6 Sol Ultra, a situação honesta dos benchmarks é que os resultados públicos independentes ainda são limitados. Como o modelo foi apresentado em um contexto de pré-visualização limitada, a cobertura ampla de benchmarks por terceiros ainda não se estabilizou. Isso significa que qualquer artigo que afirme classificações universais exatas para o GPT-5.6 Sol Ultra em todos os benchmarks deve ser tratado com cautela, a menos que vincule a um leaderboard público real ou a um lançamento oficial de avaliação.
No caso do Claude Opus 4.7, há mais material público. O próprio anúncio da Anthropic inclui feedback inicial de testadores em tarefas de codificação, agentes de pesquisa, análise de dados e fluxos de trabalho em múltiplas etapas. O GitHub também anunciou que o Claude Opus 4.7 estava sendo lançado no GitHub Copilot, com testes iniciais indicando desempenho mais forte em tarefas de múltiplas etapas e execução por agentes mais confiável. Isso não é o mesmo que benchmarks acadêmicos neutros, mas é significativo porque vem de contextos de produto para desenvolvedores, onde fluxos de trabalho reais importam.
Sites independentes de benchmark, como SWE-bench e Artificial Analysis, são importantes porque fornecem contexto externo. O SWE-bench foca em problemas reais de engenharia de software, incluindo um subconjunto Verificado filtrado por humanos. O Artificial Analysis compara modelos em termos de inteligência, velocidade, preço, tokens de saída e métricas no estilo custo-por-tarefa. Essas plataformas são valiosas porque ajudam a separar afirmações de marketing de comportamentos mensuráveis. No entanto, também exigem cautela: os resultados de benchmarks dependem de suporte, acesso a ferramentas, design de prompts, framework de agentes e regras de avaliação.
A melhor maneira de ler o panorama de benchmarks não é “GPT vence” ou “Claude vence.” Em vez disso, pense em categorias:
-
Testes de raciocínio verificam se um modelo consegue resolver problemas difíceis, mas podem não refletir o uso em ferramentas de produção.
-
Testes de codificação avaliam reparo ou geração de software, mas os resultados dependem fortemente da arquitetura do agente.
-
Testes de contexto longo avaliam recuperação e síntese em entradas extensas, mas projetos reais incluem arquivos bagunçados, requisitos conflitantes e informações incompletas.
-
Testes de agentes estão mais próximos do trabalho real, mas ainda estão evoluindo rapidamente.
-
Testes de custo importam porque um modelo que é 5% melhor mas três vezes mais caro pode ser pior para produção.
Se você precisa de uma resposta estrita de benchmark hoje, o Claude Opus 4.7 atualmente tem mais fundamentação pública porque a Anthropic divulgou detalhes oficiais e parceiros do ecossistema discutiram seu desempenho. O GPT-5.6 Sol Ultra tem uma promessa estratégica mais forte em torno da orquestração de sub-agentes, mas a validação independente ainda está alcançando. Essa lacuna pode se fechar rapidamente à medida que a prévia se expande.
Comparação de codificação: GPT-5.6 Sol Ultra vs Claude Opus 4.7 para desenvolvedores

A codificação é um dos campos de batalha mais importantes para modelos de ponta porque desenvolvedores estão entre os usuários de IA mais valiosos. Eles usam modelos com frequência, pagam por ferramentas premium e empurram modelos para tarefas reais difíceis: refatorar sistemas legados, depurar testes instáveis, projetar arquitetura, ler bases de código desconhecidas, escrever migrações, gerar casos de teste e operar dentro de IDEs.
O Claude Opus 4.7 tem uma vantagem pública clara em credibilidade de codificação hoje porque a Anthropic e o GitHub o posicionaram em torno de fluxos de trabalho de engenharia de software. O anúncio da Anthropic inclui feedback de testadores iniciais que descrevem melhor planejamento, menos erros de ferramentas e desempenho mais forte em fluxos de trabalho complexos de codificação. O changelog do GitHub diz que o Opus 4.7 está sendo implementado no GitHub Copilot e descreve melhorias em tarefas de múltiplas etapas, raciocínio de longo prazo e fluxos de trabalho dependentes de ferramentas. Para desenvolvedores, isso importa mais do que uma demonstração com um único trecho de código.
A razão pela qual o Claude frequentemente se sai bem em codificação não é apenas que ele escreve código. Muitos modelos sabem escrever código. A parte difícil é entender a arquitetura existente de um projeto, preservar o estilo, seguir restrições, fazer mudanças mínimas, diagnosticar falhas e saber quando não exagerar na engenharia. O estilo cuidadoso do Claude é útil aqui. Ele tende a raciocinar sobre o problema, explicar compensações e evitar apressar uma solução muito rapidamente. Em uma grande base de código, essa cautela pode ser uma vantagem.
A história de codificação do GPT-5.6 Sol Ultra é diferente. Relatos públicos enfatizam que o GPT-5.6 Sol é especialmente habilidoso em codificação e em tarefas agentivas de longo prazo. Se o modo Ultra realmente melhora a orquestração de sub-agentes, o modelo pode ser muito forte em fluxos de trabalho de codificação que exigem raciocínio paralelo: um sub-agente lê os testes, outro inspeciona a implementação, outro pesquisa a documentação, outro propõe um patch e outro valida casos de borda. Essa estrutura é altamente relevante para a engenharia de software de IA moderna.
Para um desenvolvedor solo dentro de uma IDE, o Claude Opus 4.7 pode parecer mais imediatamente confiável se a tarefa for ler e modificar uma base de código existente. Para um construtor de plataforma criando agentes de codificação automatizados, o GPT-5.6 Sol Ultra pode ser mais interessante porque a arquitetura aponta para orquestração. Mas até que benchmarks independentes de codificação e relatórios reais de desenvolvedores sejam mais amplos, a conclusão correta não é que o GPT-5.6 já superou o Claude. A conclusão correta é que os dois modelos podem estar otimizados para fluxos de trabalho de codificação diferentes.
Onde o Claude Opus 4.7 pode ser mais forte para codificação
-
Compreender grandes bases de código com muitas restrições.
-
Seguir instruções detalhadas ao longo de sessões longas.
-
Explicar trade-offs e evitar suposições não fundamentadas.
-
Trabalhar dentro das integrações Claude Code e GitHub Copilot.
-
Refatorações complexas onde o manuseio cuidadoso do contexto importa.
Onde o GPT-5.6 Sol Ultra pode ser mais forte para codificação
-
Sistemas de codificação que usam múltiplas ferramentas e subagentes.
-
Fluxos de trabalho automatizados que exigem planejamento, execução e ciclos de validação.
-
Produtos para desenvolvedores nativos da OpenAI e agentes de codificação baseados em API.
-
Tarefas que combinam código, documentos, logs, screenshots e contexto multimodal.
-
Iteração rápida dentro de ecossistemas de produtos de IA mais amplos.
Se sua pergunta é “qual modelo devo usar no Cursor, Claude Code, Copilot ou em um agente de codificação interno?” a resposta é testar ambos no seu repositório real. Use cinco tarefas: uma correção de bug, uma refatoração, uma nova funcionalidade, uma tarefa de geração de testes e uma explicação arquitetural. Meça não apenas se o código compila, mas quantas interações são necessárias, quantos arquivos ele altera, se respeita o estilo e se inventa APIs. Isso dirá mais do que um ranking.
Capacidade de raciocínio: pensamento profundo vs inteligência prática
Raciocínio é a palavra mais superutilizada no marketing de IA. Todo modelo de ponta afirma ter melhor raciocínio. A pergunta mais útil é: que tipo de raciocínio o modelo executa bem?
A história de raciocínio do GPT-5.6 Sol Ultra está ligada a modos. Relatos públicos dizem que o Sol inclui um modo Max para raciocínio mais profundo e um modo Ultra para orquestração de subagentes. Isso implica um modelo projetado para alocar mais computação e estrutura para tarefas difíceis. Em termos do usuário, isso pode se manifestar como melhor planejamento, decomposição mais robusta, coordenação aprimorada de ferramentas e menos respostas superficiais em problemas complexos.
A história de raciocínio do Claude Opus 4.7 está ligada à disciplina. Os exemplos públicos da Anthropic enfatizam detectar falhas lógicas durante o planejamento, relatar corretamente dados ausentes, resistir a armadilhas e continuar apesar de falhas de ferramentas. Esse tipo de raciocínio é extremamente valioso no trabalho profissional. Não se trata apenas de resolver um quebra-cabeça. Trata-se de saber quais evidências existem, o que está faltando, o que pode ser inferido e o que não deve ser afirmado.
Apply this research method to your stock
Generate bull/bear views, risk notes, and an evidence trail for GPT.
Para um usuário, a diferença pode se sentir assim: o GPT-5.6 Sol Ultra tende a se comportar como um estrategista de alta energia que pode coordenar um fluxo de trabalho complexo, enquanto o Claude Opus 4.7 tende a se comportar como um analista sênior cuidadoso que protege contra suposições fracas. Ambos os estilos são úteis. O melhor modelo depende do custo de estar errado.
Se você está elaborando uma estratégia de produto, construindo um fluxo de trabalho com agentes de IA ou gerando várias opções rapidamente, o GPT-5.6 Sol Ultra pode ser o motor criativo mais potente. Se você está revisando um contrato, analisando um longo relatório financeiro, validando um pipeline de dados ou investigando um incidente de produção, a cautela do Claude Opus 4.7 pode ser mais valiosa.
Os sistemas de raciocínio mais profundos acabarão por combinar ambos os estilos: decomposição ousada mais verificação conservadora. É por isso que fluxos de trabalho com agentes importam. Um bom sistema de IA não deve depender de uma única personalidade de modelo. Deve usar um modelo para gerar hipóteses, outro para desafiá‑las, outro para verificar as fontes e outro para transformar o resultado em uma decisão acionável. Isso é especialmente importante em pesquisas financeiras, onde conclusões confiantes, porém sem base, podem ser custosas.
Contexto longo e trabalho com documentos
Contexto longo é uma das associações de marca mais fortes do Claude. Modelos Claude têm sido amplamente usados para ler documentos, contratos, bases de código, artigos de pesquisa e relatórios empresariais. O Claude Opus 4.7 continua esse padrão ao enfatizar consistência em contexto longo e trabalho profissional de conhecimento. O anúncio da Anthropic inclui feedback de testadores elogiando a disciplina no tratamento de dados, a divulgação de dados ausentes e o forte desempenho em contextos longos.
Contexto longo não é apenas sobre o tamanho da janela. Uma janela de contexto de um milhão de tokens soa impressionante, mas o que importa é se o modelo usa o contexto corretamente. Ele consegue encontrar o detalhe relevante? Consegue evitar ser distraído por texto irrelevante? Consegue conciliar fontes conflitantes? Consegue avisar o usuário quando a resposta não está presente? Consegue preservar as restrições do início ao fim da tarefa?
O Claude Opus 4.7 parece especialmente adequado para tarefas em que a entrada é longa, desorganizada e importante. Exemplos incluem revisão jurídica, análise de políticas, memorandos de investimento, documentação técnica, bases de conhecimento de atendimento ao cliente, pastas de due diligence, manuais de conformidade e grandes repositórios de código. Nestas situações, o controle de alucinações e a disciplina de contexto podem importar mais do que a velocidade.
O GPT-5.6 Sol Ultra pode ser mais atraente quando o contexto longo faz parte de um fluxo de trabalho mais amplo. Por exemplo, em vez de simplesmente ler um longo relatório, um sistema orientado por agentes pode resumir o relatório, extrair métricas-chave, compará‑las com dados de mercado, checar notícias recentes, gerar hipóteses de investimento, debater fatores de risco e produzir uma tese final. Se a orquestração de subagentes no modo Ultra funcionar bem, o GPT-5.6 pode ser poderoso nesse tipo de fluxo de trabalho multi‑fonte.
Portanto, a distinção não é “Claude para contexto longo, GPT para todo o resto.” É mais preciso dizer: o Claude Opus 4.7 pode ser mais forte para leitura cuidadosa em contexto longo e síntese fundamentada, enquanto o GPT-5.6 Sol Ultra pode ser mais forte para fluxos de trabalho em contexto longo que exigem orquestração, uso de ferramentas e execução em múltiplas etapas.
Desempenho de agentes de IA: a verdadeira diferença
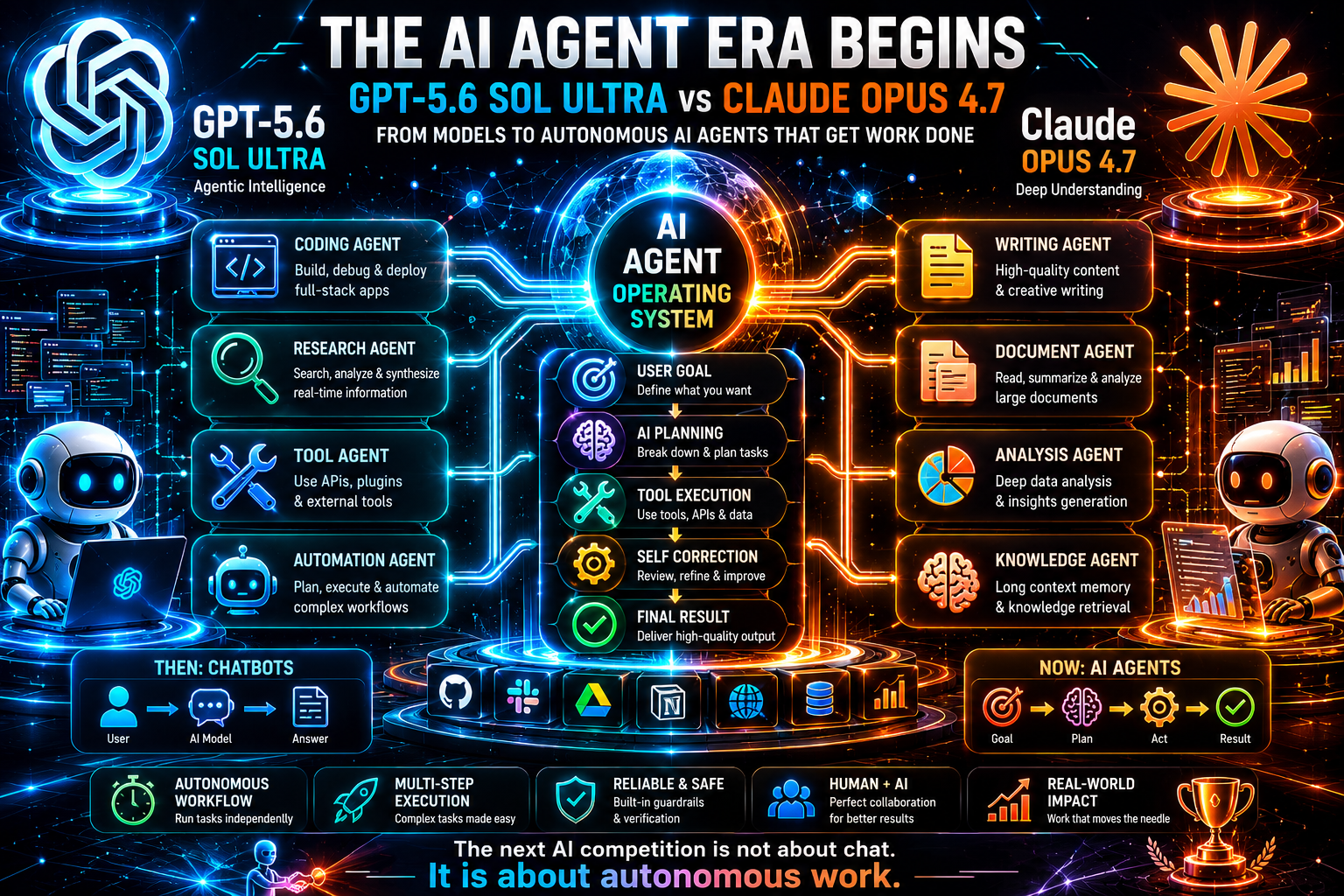
A categoria mais importante nesta comparação é o desempenho de agentes de IA. É para onde o mercado está indo. Chatbots são úteis, mas agentes são onde os ganhos de produtividade se tornam mensuráveis. Um agente de IA pode receber um objetivo, planejar etapas, chamar ferramentas, usar APIs, inspecionar resultados, revisar seu plano e continuar até que uma tarefa esteja concluída ou que uma decisão humana seja necessária.
A narrativa mais forte do GPT-5.6 Sol Ultra é a orquestração agenteica. A descrição do modo Ultra aponta para sub-agentes, que é um dos padrões mais importantes no design de sistemas avançados de IA. Uma única chamada de modelo pode ser poderosa, mas trabalhos complexos se beneficiam de papéis especializados: pesquisador, crítico, desenvolvedor, testador, analista de risco, resumidor e agente decisório. Se o GPT-5.6 Sol Ultra for otimizado para essa estrutura, ele pode se tornar uma base forte para produtos de IA de próxima geração.
A narrativa mais forte do Claude Opus 4.7 é a confiabilidade agenteica. A Anthropic e o GitHub enfatizam desempenho em tarefas multi-etapa, trabalhos de longa duração, fluxos de trabalho dependentes de ferramentas e menos falhas. Em produção, confiabilidade frequentemente vale mais do que ambição bruta. Um agente que tenta fazer demais e falha silenciosamente é perigoso. Um agente que procede com cuidado, reporta incertezas e se recupera de falhas de ferramentas é mais fácil de confiar.
Isso cria uma distinção útil para desenvolvedores:
-
Use GPT-5.6 Sol Ultra quando o agente precisar de ampla orquestração, múltiplas etapas especializadas e integração com fluxos de trabalho nativos da OpenAI.
-
Use Claude Opus 4.7 quando o agente precisar de tratamento cuidadoso de contexto, codificação ou pesquisa de longa duração e execução confiável sob restrições complexas.
-
Use ambos quando a tarefa for de alto valor: um modelo pode gerar e planejar, enquanto o outro critica, verifica ou reescreve.
O futuro dos agentes de IA não será um modelo substituindo todos os outros. Será roteamento inteligente. Uma plataforma escolherá o melhor modelo para cada etapa do fluxo de trabalho. Pode usar um modelo mais barato para classificação, um modelo rápido para extração, o Claude para análise de documentos longos, o GPT para orquestração e um modelo especializado em código para alterações de repositório. O produto vencedor não será simplesmente o produto com o maior modelo. Será o produto com o melhor design de fluxo de trabalho.
Comparação de Preços: Qual Modelo Oferece Melhor Custo-Benefício?

Precificação é onde a comparação se torna concreta. Com base em reportagens públicas, o GPT-5.6 Sol tem preço de $5 por milhão de tokens de entrada e $30 por milhão de tokens de saída. A Anthropic declara que o Claude Opus 4.7 tem preço de $5 por milhão de tokens de entrada e $25 por milhão de tokens de saída. Isso torna o Claude Opus 4.7 mais barato em tokens de saída se esses números forem a base de precificação para sua implantação.
Modelo Preço de entrada Preço de saída Observação sobre precificação GPT-5.6 Sol $5 / 1M tokens $30 / 1M tokens Mesmo preço de entrada que o Opus 4.7, preço de saída maior com base em reportagens públicas atuais. Claude Opus 4.7 $5 / 1M tokens $25 / 1M tokens Preço de saída menor, boa escolha para fluxos de trabalho extensos de codificação e documentos se o uso de tokens for controlado.
No entanto, o preço por token sozinho não determina o custo real. O custo real depende do comprimento da saída, do tamanho do contexto, do cache de prompts, da taxa de retentativas, das chamadas a ferramentas, da latência e de com que frequência o modelo acerta na primeira tentativa. Um modelo mais barato pode se tornar caro se exigir muitas retentativas. Um modelo mais caro pode ser mais barato se concluir a tarefa com menos chamadas. Para agentes de codificação, o maior fator de custo muitas vezes não é o prompt inicial. É o ciclo iterativo: inspecionar arquivos, propor alterações, executar testes, ler erros, revisar e repetir.
Business Insider relatou que a Anthropic atualizou suas estimativas de gasto de tokens do Claude Code, afirmando que o custo médio de um desenvolvedor corporativo era de cerca de US$13 por dia ativo e US$150 a US$250 por desenvolvedor por mês, com 90% dos usuários abaixo de US$30 por dia ativo. O ponto importante não é que o Claude seja exclusivamente caro. O ponto é que o uso de agentes de IA muda a estrutura de custos. Quando os modelos se tornam trabalhadores em vez de motores de respostas, eles consomem mais tokens porque fazem mais trabalho.
Para equipes de produção, a questão de precificação deve ser formulada como custo por fluxo de trabalho concluído. Por exemplo:
-
Quanto custa resolver um chamado de suporte?
-
Quanto custa corrigir um bug?
-
Quanto custa gerar um briefing de investimento?
-
Quanto custa analisar uma teleconferência de resultados?
-
Quanto custa monitorar uma ação por uma semana?
Uma vez que você meça o custo dessa maneira, o melhor modelo pode variar conforme a tarefa. O Claude Opus 4.7 pode ser mais eficiente em termos de custo para saídas cuidadosas de longo contexto porque o preço por token de saída é menor e seu estilo pode reduzir retrabalho. O GPT-5.6 Sol Ultra pode ser mais eficiente em fluxos de trabalho nos quais a orquestração reduz o tempo de coordenação humana. A única maneira confiável de saber é realizar avaliações por tarefa com prompts reais, arquivos reais e critérios de sucesso reais.
Experiência do Desenvolvedor: Claude Code, GitHub Copilot, APIs e Frameworks de Agentes
A qualidade do modelo importa, mas a experiência do desenvolvedor determina a adoção. Um modelo que é ligeiramente melhor, mas mais difícil de integrar, pode perder para um modelo que se encaixa naturalmente nos fluxos de trabalho existentes. É por isso que Claude Code, GitHub Copilot, ChatGPT, ferramentas de API e frameworks de agentes são tão importantes.
O Claude Opus 4.7 se beneficia por estar integrado aos ambientes de desenvolvimento onde os usuários já trabalham. O anúncio do GitHub de que o Opus 4.7 está sendo implementado no Copilot lhe dá distribuição dentro de um dos produtos de codificação mais importantes do mundo. O Claude Code também dá à Anthropic uma interface direta para engenharia de software baseada em agentes. Para desenvolvedores que desejam um parceiro de codificação poderoso em vez de apenas uma API, isso faz diferença.
O GPT-5.6 Sol Ultra se beneficia do ecossistema mais amplo da OpenAI. O ChatGPT permanece uma interface de IA mainstream, a API da OpenAI tem forte presença entre desenvolvedores, e a direção de produto da empresa cada vez mais apoia ferramentas, fluxos de trabalho multimodais e aplicações baseadas em agentes. Se sua equipe já constrói sobre as APIs da OpenAI, o GPT-5.6 Sol Ultra pode ser mais fácil de adotar como caminho de atualização.
A questão da experiência do desenvolvedor deve incluir:
-
O modelo funciona dentro das ferramentas que sua equipe já usa?
-
Ele pode chamar suas ferramentas internas com segurança?
-
Você pode monitorar o uso de tokens e o sucesso dos fluxos de trabalho?
-
Você pode rotear tarefas entre modelos?
-
Você pode adicionar salvaguardas para segurança, privacidade e conformidade?
-
O modelo pode explicar o que fez e por quê?
Para plataformas internas de IA, a melhor resposta pode ser um roteador de modelos em vez de um compromisso com um único modelo. Use Claude Opus 4.7 para tarefas que exigem leitura cuidadosa e raciocínio em bases de código com longo contexto. Use GPT-5.6 Sol Ultra para orquestração pesada em planejamento, uso intensivo de ferramentas e multagente. Use modelos mais baratos para extração, classificação e tarefas repetitivas. Essa arquitetura é mais resiliente do que apostar tudo em um único modelo de ponta.
Pesquisa e Análise: Qual Modelo Lida Melhor com Informações Complexas?
A pesquisa é onde modelos de IA podem gerar enorme alavancagem. Um analista humano pode gastar horas lendo relatórios, arquivamentos, transcrições, notícias, discussões em fóruns, dados de mercado e documentos internos. Um bom modelo de IA pode comprimir esse processo. Mas um sistema de pesquisa ruim pode produzir nonsense confiante.
Claude Opus 4.7 tem um forte argumento para tarefas de pesquisa por causa de sua disciplina de longo contexto e tratamento cauteloso de dados ausentes. O anúncio da Anthropic inclui feedback de testadores descrevendo melhor divulgação e disciplina de dados. Isso importa na pesquisa porque os erros mais perigosos muitas vezes não são alucinações óbvias. São inferências sutis e sem suporte que soam razoáveis.
GPT-5.6 Sol Ultra tem um forte caso para fluxos de trabalho de pesquisa por causa de sua orientação agentiva. Pesquisa não é apenas leitura. É fazer as perguntas certas, reunir fontes, comparar perspectivas, identificar contradições, atualizar uma tese e decidir o que monitorar em seguida. Se o modo Ultra melhora a orquestração de subagentes, o GPT-5.6 pode ser especialmente útil para sistemas de pesquisa que dividem o trabalho entre vários agentes.
Por exemplo, um fluxo de trabalho de pesquisa financeira pode incluir:
-
Um agente de notícias que reúne desenvolvimentos recentes da empresa.
-
Um agente de arquivamentos que extrai receitas, margens, dívida e alterações nas orientações.
-
Um agente de mercado que verifica ação de preço, volume, volatilidade e movimento do setor.
-
Um agente de risco que desafia a tese otimista.
-
Um agente de valuation que compara múltiplos e suposições.
-
Um agente de síntese final que produz um relatório pronto para decisão.
Aqui é onde GPT-5.6 Sol Ultra e Claude Opus 4.7 podem ser ambos valiosos. O GPT pode coordenar o fluxo de trabalho. O Claude pode criticar as evidências. Outro modelo pode extrair números estruturados de forma econômica. O produto final não é uma resposta de chatbot. É um processo de pesquisa nativo em IA.
Por que a Pesquisa de Investimentos Nativa em IA Está se Tornando Possível
A pesquisa de investimentos é um exemplo perfeito de por que a corrida por modelos de IA está se tornando uma corrida por fluxos de trabalho. Investidores não precisam apenas de respostas. Precisam de pensamento estruturado sob incerteza. Precisam saber o que mudou, por que isso importa, quais evidências sustentam a tese, o que pode estar errado e qual sinal deve ser monitorado a seguir.
Ferramentas tradicionais de pesquisa financeira costumam ser estáticas. Elas mostram gráficos, índices, manchetes, classificações de analistas e documentos (filings). Isso é útil, mas exige que o usuário conecte os pontos manualmente. O usuário ainda precisa decidir quais informações importam, quais riscos estão subprecificados, qual narrativa está mudando e qual dado contradiz o consenso.
Agentes de IA podem mudar isso. Um agente de pesquisa pode ler transcrições de resultados. Um agente de risco pode desafiar premissas. Um agente de avaliação pode comparar cenários. Um agente de notícias pode acompanhar catalisadores. Um agente de monitoramento pode vigiar por eventos que invalidam a tese. Um agente de debate pode simular argumentos de alta e de baixa. Não se trata de substituir o julgamento humano. Trata-se de oferecer aos investidores humanos um sistema operacional de pesquisa melhor.
É aí que plataformas como AlphaVue.ai se encaixam na mudança mais ampla provocada pela IA. A próxima geração de plataformas de investimento não apenas exibirá dados. Elas ajudarão os usuários a raciocinar sobre os dados. Transformarão informações de mercado em fluxos de trabalho: escanear, pesquisar, debater, comparar, monitorar e decidir. GPT-5.6 Sol Ultra e Claude Opus 4.7 são importantes não porque um modelo derrotará permanentemente o outro, mas porque ambos mostram o quão perto o mercado está de uma inteligência de investimento nativa em IA.
Para investidores, a questão-chave não é mais “a IA pode resumir esta ação?” Isso é o mínimo. A pergunta real é: a IA pode me ajudar a entender o que importa, o que mudou, o que já está precificado, o que é incerto e o que fazer a seguir? Isso exige fluxos de trabalho agentivos, roteamento de modelos, disciplina de fontes e raciocínio transparente. Também exige design de produto. Um modelo poderoso sem um bom fluxo de trabalho é como um terminal Bloomberg sem busca, sem alertas e sem estrutura.
Perspectiva da AlphaVue.ai: de Modelos de IA a Agentes de Investimento com IA
O futuro da pesquisa financeira não será um único chatbot gigante. Será uma rede de agentes de IA especializados que pesquisam empresas, comparam sinais de mercado, testam cenários otimistas e pessimistas e ajudam investidores a monitorar o que importa. AlphaVue.ai foi construída para esse fluxo de trabalho de investimento nativo em IA: pesquisa mais inteligente, decisões mais claras e insights mais rápidos.
Casos de Uso no Mundo Real: Qual Modelo Você Deve Escolher?
Não há um vencedor universal entre GPT-5.6 Sol Ultra e Claude Opus 4.7. O modelo certo depende da tarefa. Aqui está um quadro prático de decisão.
Escolha GPT-5.6 Sol Ultra quando:
-
Você está construindo agentes de IA que precisam de planejamento, uso de ferramentas e orquestração.
-
Você já usa as APIs da OpenAI e quer um caminho de atualização de ponta.
-
Seu fluxo de trabalho combina texto, código, dados estruturados e possivelmente entradas multimodais.
-
Você quer que o modelo coordene subtarefas especializadas.
-
Você valoriza integração com o ecossistema e velocidade de produto.
Escolha Claude Opus 4.7 quando:
-
Você precisa de leitura atenta de contextos longos e análise de documentos.
-
Você trabalha intensamente com bases de código, refatoração e tarefas de engenharia complexas.
-
Você valoriza raciocínio cauteloso e a divulgação de dados ausentes.
-
Você usa integrações Claude Code ou GitHub Copilot que suportam Opus 4.7.
-
Você quer preços de tokens de saída ligeiramente mais baixos com base nas tarifas listadas.
Use ambos quando:
-
A tarefa tem valor suficientemente alto para justificar verificação cruzada entre modelos.
-
Você precisa que um modelo gere e outro critique.
-
Você está construindo uma plataforma de IA de produção com roteamento de modelos.
-
Você quer reduzir modos de falha dependentes de um único modelo.
-
Você se importa tanto com criatividade quanto com cautela.
As equipes mais sofisticadas não vão perguntar "qual modelo é o melhor?" Elas vão perguntar "qual modelo deve lidar com cada etapa?" Essa é a pergunta certa para 2026. A IA tornou-se importantíssima demais para tratar a seleção de modelos como uma preferência de marca.
Veredito final: GPT-5.6 Sol Ultra ou Claude Opus 4.7?

Se você quer a resposta mais simples, é esta: Claude Opus 4.7 é a escolha mais segura hoje para codificação cuidadosa, pesquisa em contextos longos e fluxos de trabalho profissionais disciplinados, enquanto GPT-5.6 Sol Ultra é a escolha estrategicamente mais empolgante para orquestração orientada a agentes e sistemas de IA nativos da OpenAI.
O Claude Opus 4.7 tem mais respaldo público no momento. A Anthropic publicou preços e disponibilidade oficiais. O GitHub discutiu sua implantação no Copilot. O feedback dos primeiros testadores destaca exatamente as capacidades que importam para trabalho real: execução em múltiplas etapas, menos erros em ferramentas, planejamento mais sólido e melhor desempenho em contextos longos. Se sua equipe precisa de um modelo hoje para fluxos de trabalho de codificação e pesquisa, o Claude Opus 4.7 merece uma avaliação séria.
O GPT-5.6 Sol Ultra é mais difícil de avaliar com certeza porque a cobertura de benchmarks independentes ainda é limitada. Mas sua direção é importante. A combinação de raciocínio de destaque, modo Max, modo Ultra e orquestração de sub-agentes aponta para onde a IA está indo: de responder perguntas para coordenar trabalho. Se a OpenAI entregar bem, o GPT-5.6 Sol Ultra pode se tornar um dos modelos mais importantes para produtos nativos para agentes.
O verdadeiro vencedor pode não ser nenhum dos modelos isoladamente. O vencedor real é a camada de fluxo de trabalho que usa o modelo certo no momento certo. Em codificação, isso significa agentes que podem ler, corrigir, testar e explicar. Em pesquisa, isso significa sistemas que podem coletar, verificar, debater e monitorar. Em investimentos, isso significa plataformas que transformam dados de mercado em inteligência estruturada.
Portanto, GPT-5.6 Sol Ultra vs Claude Opus 4.7 não é apenas uma comparação de modelos. É uma prévia da próxima guerra de plataformas de IA. O futuro pertencerá a sistemas que combinam raciocínio, ferramentas, memória, verificação e design de fluxo de trabalho. O chatbot mais inteligente não vencerá. O trabalhador de IA mais útil vencerá.
Perguntas Frequentes: GPT-5.6 Sol Ultra vs Claude Opus 4.7
O GPT-5.6 Sol Ultra é melhor do que o Claude Opus 4.7?
Não de forma universal. O GPT-5.6 Sol Ultra parece mais focado na orquestração baseada em agentes e em fluxos de trabalho nativos da OpenAI, enquanto o Claude Opus 4.7 apresenta evidências públicas mais fortes para codificação cuidadosa, trabalho com contexto longo e execução confiável em múltiplas etapas. O modelo mais adequado depende do seu caso de uso.
Qual modelo é melhor para codificação?
Atualmente, o Claude Opus 4.7 possui credibilidade pública maior em codificação porque a Anthropic e o GitHub destacaram seu desempenho em codificação e em fluxos de trabalho de desenvolvedores orientados por agentes. O GPT-5.6 Sol Ultra pode tornar-se altamente competitivo para sistemas de codificação baseados em agentes, especialmente se seu modo Ultra melhorar a orquestração de subagentes.
Qual modelo é mais barato?
Com base nos preços públicos, ambos os modelos estão cotados em US$5 por milhão de tokens de entrada. O Claude Opus 4.7 está cotado em US$25 por milhão de tokens de saída, enquanto reportagens públicas listam o GPT-5.6 Sol em US$30 por milhão de tokens de saída. O custo real depende de retentativas, comprimento da saída, uso de ferramentas, armazenamento em cache e taxa de sucesso do fluxo de trabalho.
Qual modelo é melhor para agentes de IA?
O GPT-5.6 Sol Ultra pode ser mais interessante para orquestração de agentes porque o modo Ultra é descrito com foco em subagentes. O Claude Opus 4.7 pode ser melhor para execução confiável de agentes de longa duração, especialmente em fluxos de trabalho pesados em codificação e documentos. Para casos de uso de alto valor, usar ambos por meio de um roteador de modelos pode ser o ideal.
Qual modelo as startups devem escolher?
As startups devem escolher com base na economia do fluxo de trabalho. Se o produto depende da integração com o ecossistema OpenAI e da orquestração multiagente, teste o GPT-5.6 Sol Ultra. Se o produto depende de raciocínio com contexto longo, confiabilidade na codificação e análise cuidadosa, teste o Claude Opus 4.7. Em produção, direcione tarefas conforme os pontos fortes de cada modelo em vez de usar um único modelo para tudo.
Qual modelo é melhor para pesquisa de investimentos?
O Claude Opus 4.7 pode ser mais forte na leitura de relatórios longos e na produção de análises cautelosas. O GPT-5.6 Sol Ultra pode ser mais forte em fluxos de pesquisa multiagente que coletam notícias, comparam dados financeiros, debatem riscos e monitoram mudanças na tese. Os melhores sistemas de pesquisa de investimentos provavelmente combinarão vários modelos e agentes especializados.