
GPT-5.6 Sol Ultra et Claude Opus 4.7 représentent deux visions différentes de l'IA de pointe. L’un est positionné autour de l’orchestration agentique, des modes de raisonnement profonds et de l’écosystème de produits en expansion d’OpenAI. L’autre est construit autour d’une exécution soignée, du travail sur de longs contextes, de la fiabilité du codage et d’une discipline des flux de travail de niveau entreprise. La vraie question n’est plus simplement « quel modèle est plus intelligent ? » mais « quel modèle correspond réellement à votre façon de travailler ? »
La course aux modèles d’IA a changé. Il y a un an, la plupart des comparaisons de modèles portaient sur la qualité des réponses : quel modèle a écrit le meilleur essai, résolu l’énigme la plus difficile, résumé le PDF le plus long ou produit l’extrait de code le plus propre. Cela compte toujours, mais ce n’est plus suffisant. En 2026, la frontière se déplace vers des systèmes d’IA capables de planifier, d’utiliser des outils, de gérer le contexte, de se remettre d’erreurs et de poursuivre des objectifs en plusieurs étapes. Le modèle le plus précieux n’est pas toujours celui qui fournit la réponse unique la plus impressionnante. C’est souvent celui qui peut achever le flux de travail le plus utile avec le moins de friction.
C’est pourquoi la comparaison entre GPT-5.6 Sol Ultra et Claude Opus 4.7 est intéressante. Ces modèles ne sont pas de simples améliorations de chatbots. Ils sont candidats à devenir la couche d’intelligence derrière des agents d’ingénierie logicielle, des copilotes de recherche, des systèmes d’analyse financière, des automatisations d’entreprise et des flux de travail d’aide à la décision. Pour les développeurs, la question devient de savoir si GPT-5.6 Sol Ultra ou Claude Opus 4.7 est meilleur pour le codage, le débogage, l’architecture et l’exécution agentique. Pour les entreprises, la question devient quel modèle offre le meilleur rapport qualité-prix. Pour les investisseurs et les analystes, la question devient quel modèle peut transformer des informations bruyantes en insights structurés.
Cet article compare les deux modèles à travers les informations publiques, la tarification, les cas d’usage de codage, les comportements de raisonnement, le contexte des benchmarks, les flux de travail des développeurs, la performance des agents d’IA et les scénarios de recherche en conditions réelles. Lorsque des chiffres publics fiables existent, nous les utilisons. Lorsque la couverture des benchmarks indépendants est encore limitée, notamment pour GPT-5.6 Sol Ultra durant sa période de prévisualisation, nous évitons de prétendre que les classements exacts sont déjà établis. Une bonne comparaison d’IA doit aider les gens à prendre de meilleures décisions, pas fabriquer une certitude illusoire.
Remarque importante sur les sources : GPT-5.6 Sol Ultra en est encore au début du cycle public. Les rapports publics les plus utiles décrivent GPT-5.6 comme une suite de modèles en prévisualisation limitée avec Sol en tant que modèle phare, plus des modes Max et Ultra pour un raisonnement plus profond et l’orchestration de sous-agents. Claude Opus 4.7 dispose d’informations officielles plus directes de la part d’Anthropic, y compris la disponibilité de l’API, la tarification et les retours des testeurs. Cette comparaison sépare donc les données confirmées de l’interprétation pratique.
La course à l'IA a changé : des chatbots aux agents intelligents

La façon la plus simple de mal comprendre GPT-5.6 Sol Ultra vs Claude Opus 4.7 est de traiter la comparaison comme un simple concours de chatbots. Ce cadrage est dépassé. Les meilleurs modèles ne se disputent plus seulement la capacité à rédiger un meilleur paragraphe ou à répondre à une question de culture générale. Ils se mesurent désormais à leur capacité à fonctionner comme des travailleurs intelligents au sein d'un système plus vaste.
À l'ère des chatbots, l'utilisateur faisait la majeure partie du travail. L'utilisateur découpait le problème en éléments, rédigeait des prompts soignés, copiait les résultats dans d'autres outils, vérifiait les erreurs manuellement, posait des questions de suivi et assemblait la réponse finale. Le modèle était puissant, mais passif. Il attendait des instructions.
À l'ère des agents, on attend du modèle qu'il assure davantage la coordination. Il doit comprendre l'objectif, planifier les étapes, rassembler des preuves, utiliser des outils, écrire ou modifier du code, tester le résultat, analyser les échecs, réviser son approche et fournir un livrable prêt à la décision. Cela ne signifie pas que l'IA est autonome au sens magique. Cela signifie que l'unité de valeur passe d'une réponse isolée à un flux de travail achevé.
GPT-5.6 Sol Ultra semble conçu pour cette transition. Les comptes rendus publics décrivent Sol comme le vaisseau amiral d'OpenAI dans la suite GPT-5.6, avec des points forts en programmation, cybersécurité, biologie et tâches agentives à long terme. Le mode Ultra est particulièrement notable car il serait conçu pour tirer parti de sous-agents. Ce cadrage a de l'importance. L'orchestration de sous-agents suggère un modèle pensé non seulement pour raisonner dans un seul flux, mais pour distribuer le travail à travers des processus spécialisés internes ou externes.
Claude Opus 4.7 vient d'une direction différente mais tout aussi importante. Les documents publics d'Anthropic mettent l'accent sur des workflows complexes en plusieurs étapes, la programmation, l'utilisation d'outils, les tâches de longue durée, la discipline des données, le respect des consignes et la cohérence. Les premiers retours de testeurs ont souligné la capacité de Claude Opus 4.7 à détecter des fautes logiques lors de la planification, à poursuivre malgré des défaillances d'outils et à éviter des solutions de repli plausibles mais non étayées. Ce n'est pas seulement « une meilleure écriture ». C'est la fiabilité du flux de travail.
Cela crée le contraste central : GPT-5.6 Sol Ultra ressemble à un modèle optimisé pour l'orchestration et les écosystèmes d'agents, tandis que Claude Opus 4.7 paraît optimisé pour une exécution soigneuse et fiable sur des travaux longs et complexes. Le vainqueur dépendra de la valeur que votre cas d'utilisation accorde à l'intégration large dans un écosystème et à la flexibilité agentive, ou bien à la cohérence sur de longs contextes et à la précision prudente.
GPT-5.6 Sol Ultra vs Claude Opus 4.7 : comparaison rapide
Avant d'entrer dans le détail des benchmarks et des workflows, voici la comparaison à haut niveau. Ce tableau n'a pas pour but de proclamer un vainqueur universel. Il vise à clarifier où chaque modèle semble le plus performant en se basant sur les informations publiques actuelles et les usages pratiques.
Catégorie GPT-5.6 Sol Ultra Claude Opus 4.7 Positionnement principal Variante de la suite de modèles OpenAI haut de gamme axée sur le raisonnement avancé, le codage et les flux de travail agentiques, avec un mode Ultra décrit autour de l'orchestration de sous-agents. Modèle frontier d'Anthropic Opus axé sur le codage, le travail sur de longs contextes, les tâches complexes, l'exécution cohérente et le respect rigoureux des instructions. Meilleure adéquation Flux de travail agentiques, applications de l'écosystème OpenAI, orchestration d'outils, recherche automatisée, expériences IA multimodales et industrialisées. Longs documents, tâches de codage complexes, analyses soignées, flux d'ingénierie d'entreprise, Claude Code et raisonnement structuré. Codage : Fort candidat pour le codage agentique et le débogage automatisé, en particulier lorsque les outils OpenAI sont centraux. Positionnement public très fort sur le codage et les tâches logicielles de longue durée ; disponible dans Claude Code et les intégrations GitHub Copilot. Tarification : Les rapports publics indiquent GPT-5.6 Sol à 5 $ par million de tokens d'entrée et 30 $ par million de tokens de sortie pendant la période d'aperçu. Anthropic indique que Claude Opus 4.7 reste à 5 $ par million de tokens d'entrée et 25 $ par million de tokens de sortie. Certitude des benchmarks : Les données publiques indépendantes de benchmark restent limitées en raison du cycle d'aperçu précoce. Plus de retours de l'écosystème public et des déclarations officielles d'Anthropic sont disponibles ; la couverture indépendante des benchmarks varie selon les tests. Capacité d'agent : Potentiellement plus forte pour l'orchestration de sous-agents et les flux de produits IA larges. Potentiellement plus forte pour l'exécution fiable à long terme et les flux de travail dépendant d'outils. Meilleur choix pratique : Choisissez-le lorsque vous souhaitez un système d'agents natif OpenAI, une large intégration dans l'écosystème et des modes de raisonnement haute performance. Choisissez-le lorsque vous souhaitez un codage discipliné, un raisonnement sur les documents, une fiabilité sur de longs contextes et des sorties soigneuses.
Philosophie du modèle : OpenAI Sol Ultra vs Anthropic Opus
OpenAI et Anthropic ont des philosophies produit différentes, et ces différences se traduisent dans le comportement des modèles. Les modèles frontier d'OpenAI donnent de plus en plus l'impression d'être des composants d'un système d'exploitation IA en expansion : ChatGPT, flux de travail API, entrées multimodales, utilisation d'outils, environnements de codage, intégrations d'entreprise et surfaces produit agentiques. Le modèle n'est pas seulement un cerveau. Il fait partie d'un système qui cherche à prendre en charge davantage du travail de l'utilisateur, du début à la fin.
GPT-5.6 Sol Ultra s'inscrit dans cette direction. Le branding « Sol » suggère le niveau phare, tandis que « Ultra » indique le mode le plus capable pour les tâches complexes. L'expression clé est orchestration de sous-agents. En termes pratiques, les systèmes d'IA les plus avancés ressemblent de moins en moins à un unique générateur de réponses massif et de plus en plus à un gestionnaire de travailleurs spécialisés. Un agent peut inspecter le code source. Un autre peut rechercher dans la documentation. Un autre peut évaluer les implications de sécurité. Un autre peut résumer les compromis. Le modèle principal coordonne ces efforts en un résultat final.
La philosophie d'Opus chez Anthropic est davantage centrée sur une intelligence fiable. Claude est depuis longtemps reconnu pour la qualité rédactionnelle, la compréhension des longs contextes et un style prudent. Claude Opus 4.7 étend ce schéma au travail professionnel. L'annonce d'Anthropic a mis l'accent sur les retours de tests provenant d'entreprises de codage, de données, de recherche et de flux de travail. Le discours porte moins sur des démonstrations tape-à-l'œil et davantage sur moins d'erreurs d'outils, une meilleure planification, de meilleures performances sur des tâches de longue durée et une meilleure transparence lorsque des données font défaut.
Cette différence importe parce que de nombreux échecs de l'IA en production ne sont pas dus à un manque d'intelligence brute. Ils sont causés par un mauvais comportement du flux de travail. Le modèle invente des informations manquantes. Il s'arrête trop tôt. Il échoue silencieusement. Il suit une mauvaise hiérarchie d'instructions. Il utilise mal les outils. Il change la tâche sans expliquer pourquoi. Il produit des résultats impressionnants qui ne sont pas réellement étayés par les preuves disponibles. Le message d'Anthropic autour de Claude Opus 4.7 cible directement ces problèmes de production.
La conclusion pratique est simple : GPT-5.6 Sol Ultra peut être plus enthousiasmant pour les concepteurs qui veulent que les systèmes d'IA coordonnent plusieurs tâches et s'intègrent profondément dans un écosystème produit. Claude Opus 4.7 peut être plus attrayant pour les équipes qui ont besoin d'une exécution soignée, d'une gestion solide du contexte et de moins de surprises de raisonnement dans des flux de travail professionnels longs.
Comparaison des benchmarks : quel modèle d'IA est plus intelligent ?

Les benchmarks sont utiles, mais seulement s'ils sont interprétés correctement. Un score dans un classement n'est pas la même chose qu'une adéquation produit. Un modèle peut obtenir un bon score sur un benchmark et rester frustrant dans un flux de travail réel. Un autre modèle peut être légèrement en retard sur un test synthétique mais meilleur pour suivre les instructions, utiliser des outils ou maintenir le contexte sur une tâche longue.
Pour GPT-5.6 Sol Ultra, la situation honnête vis-à-vis des benchmarks est que les résultats publics indépendants sont encore limités. Comme le modèle a été présenté dans un contexte d'aperçu limité, la couverture étendue par des tiers n'est pas encore stabilisée. Cela signifie que tout article prétendant à des classements universels exacts pour GPT-5.6 Sol Ultra sur tous les benchmarks doit être pris avec précaution, sauf s'il renvoie à un véritable classement public ou à une publication d'évaluation officielle.
Pour Claude Opus 4.7, il existe plus de matériel public. L'annonce d'Anthropic elle-même inclut des retours de testeurs précoces couvrant le codage, les tâches d'agents de recherche, l'analyse de données et les flux de travail à étapes multiples. GitHub a également annoncé que Claude Opus 4.7 était déployé dans GitHub Copilot, les premiers tests indiquant de meilleures performances sur les tâches multi-étapes et une exécution agentive plus fiable. Ce ne sont pas les mêmes choses que des benchmarks académiques neutres, mais elles sont significatives car elles proviennent de contextes produit-développeur où les flux de travail réels comptent.
Des sites de benchmark indépendants tels que SWE-bench et Artificial Analysis sont importants car ils fournissent un contexte externe. SWE-bench se concentre sur des problèmes réels d'ingénierie logicielle, y compris un sous-ensemble « Verified » filtré par des humains. Artificial Analysis compare les modèles selon l'intelligence, la vitesse, le prix, les jetons de sortie et des métriques du type coût par tâche. Ces plateformes sont précieuses car elles aident à distinguer les affirmations marketing du comportement mesurable. Cependant, elles exigent aussi de la prudence : les résultats des benchmarks dépendent du cadre, de l'accès aux outils, de la conception des prompts, du framework agent et des règles d'évaluation.
La meilleure façon de lire le paysage des benchmarks n'est pas « GPT gagne » ou « Claude gagne ». Pensez plutôt en catégories :
-
Les benchmarks de raisonnement évaluent si un modèle peut résoudre des problèmes difficiles, mais ne reflètent pas forcément l'utilisation en production des outils.
-
Les benchmarks de codage testent la réparation ou la génération de logiciels, mais les résultats dépendent fortement du cadre d'agent utilisé.
-
Les benchmarks de contexte long évaluent la récupération et la synthèse sur de grandes entrées, mais les projets réels incluent des fichiers désordonnés, des exigences contradictoires et des informations incomplètes.
-
Les benchmarks d'agents se rapprochent davantage du travail réel, mais ils évoluent encore très rapidement.
-
Les benchmarks de coût comptent parce qu'un modèle 5 % meilleur mais 3 fois plus cher peut être moins adapté à la production.
Si vous avez besoin d'une réponse de benchmark stricte aujourd'hui, Claude Opus 4.7 dispose actuellement d'un ancrage public plus solide parce qu'Anthropic a publié des détails officiels et que des partenaires de l'écosystème ont discuté de ses performances. GPT-5.6 Sol Ultra présente une promesse stratégique plus forte autour de l'orchestration de sous-agents, mais la validation indépendante est encore en retards. Cet écart peut se réduire rapidement au fur et à mesure de l'expansion de l'aperçu.
Comparaison en matière de codage : GPT-5.6 Sol Ultra vs Claude Opus 4.7 pour les développeurs

Le codage est l'un des terrains d'affrontement les plus importants pour les modèles de pointe parce que les développeurs figurent parmi les utilisateurs d'IA les plus précieux. Ils utilisent fréquemment les modèles, paient pour des outils premium et poussent les modèles sur des tâches réelles difficiles : refactorisation de systèmes hérités, débogage de tests instables, conception d'architectures, lecture de bases de code inconnues, écriture de migrations, génération de cas de test et travail dans des IDE.
Claude Opus 4.7 possède aujourd'hui un avantage public clair en crédibilité pour le codage car Anthropic et GitHub l'ont tous deux positionné autour des flux de travail d'ingénierie logicielle. L'annonce d'Anthropic inclut des retours d'utilisateurs précoces décrivant une meilleure planification, moins d'erreurs liées aux outils et de meilleures performances sur des flux de travail de codage complexes. Le journal des modifications de GitHub indique qu'Opus 4.7 est déployé dans GitHub Copilot et décrit des améliorations sur les tâches en plusieurs étapes, le raisonnement à long terme et les flux de travail dépendants des outils. Pour les développeurs, cela compte plus qu'une simple démo de snippet de code.
La raison pour laquelle Claude réussit souvent en codage n'est pas seulement qu'il écrit du code. Beaucoup de modèles savent écrire du code. La difficulté consiste à comprendre l'architecture existante d'un projet, préserver le style, respecter les contraintes, effectuer des modifications minimales, diagnostiquer les pannes et savoir quand ne pas sur-ingénieriser. Le style prudent de Claude est utile ici. Il a tendance à raisonner sur le problème, expliquer les compromis et éviter de se précipiter trop vite vers une solution. Dans une grande base de code, cette prudence peut être un atout.
L'histoire du codage pour GPT-5.6 Sol Ultra est différente. Les rapports publics insistent sur le fait que GPT-5.6 Sol est particulièrement compétent pour les tâches de codage et les tâches agentiques à long terme. Si le mode Ultra améliore réellement l'orchestration des sous-agents, le modèle pourrait être très performant dans les flux de travail de codage nécessitant un raisonnement parallèle : un sous-agent lit les tests, un autre inspecte l'implémentation, un autre recherche la documentation, un autre propose un correctif et un autre valide les cas limites. Cette structure est très pertinente pour l'ingénierie logicielle assistée par IA moderne.
Pour un développeur seul travaillant dans un IDE, Claude Opus 4.7 peut sembler plus immédiatement fiable si la tâche consiste à lire et modifier une base de code existante. Pour un créateur de plateforme développant des agents de codage automatisés, GPT-5.6 Sol Ultra peut être plus intéressant car l'architecture tend vers l'orchestration. Mais tant que les benchmarks de codage indépendants et les retours réels des développeurs ne seront pas plus nombreux, la bonne conclusion n'est pas que GPT-5.6 a déjà battu Claude. La bonne conclusion est que les deux modèles peuvent être optimisés pour des flux de travail de codage différents.
Où Claude Opus 4.7 peut être plus performant pour le codage
-
Comprendre de grandes bases de code avec de nombreuses contraintes.
-
Suivre des instructions détaillées au cours de longues sessions.
-
Expliquer les compromis et éviter les hypothèses non fondées.
-
Travailler au sein des intégrations Claude Code et GitHub Copilot.
-
Refactorings complexes où la gestion attentive du contexte est importante.
Où GPT-5.6 Sol Ultra peut être plus performant pour le codage
-
Systèmes de codage basés sur des agents qui utilisent plusieurs outils et sous-agents.
-
Flux de travail automatisés qui nécessitent des boucles de planification, d'exécution et de validation.
-
Produits développeurs natifs OpenAI et agents de codage basés sur des API.
-
Tâches combinant code, documents, journaux, captures d'écran et contexte multimodal.
-
Itération rapide au sein d'écosystèmes de produits IA plus vastes.
Si votre question est « quel modèle dois-je utiliser dans Cursor, Claude Code, Copilot ou un agent de codage interne ? », la réponse est de tester les deux sur votre dépôt réel. Utilisez cinq tâches : une correction de bug, un refactoring, une fonctionnalité, une tâche de génération de tests et une explication d'architecture. Mesurez non seulement si le code compile, mais combien de tours cela prend, combien de fichiers il modifie, s'il respecte le style et s'il invente des API. Cela vous dira plus qu'un classement.
Capacité de raisonnement : réflexion approfondie vs intelligence pratique
Le terme « raisonnement » est le mot le plus galvaudé dans le marketing de l'IA. Chaque modèle de pointe prétend avoir un meilleur raisonnement. La question la plus utile est : quel type de raisonnement le modèle réalise-t-il bien ?
L'histoire du raisonnement de GPT-5.6 Sol Ultra est liée aux modes. Les rapports publics indiquent que Sol inclut un mode Max pour un raisonnement plus profond et un mode Ultra pour l'orchestration de sous-agents. Cela implique un modèle conçu pour allouer davantage de calcul et de structure aux tâches difficiles. Pour l'utilisateur, cela peut se traduire par une meilleure planification, une décomposition plus poussée, une coordination d'outils améliorée et moins de réponses superficielles sur des problèmes complexes.
L'histoire du raisonnement de Claude Opus 4.7 est liée à la discipline. Les exemples publics d'Anthropic mettent l'accent sur la détection des fautes logiques pendant la planification, le signalement correct des données manquantes, la résistance aux pièges et la poursuite malgré les défaillances d'outils. Ce type de raisonnement est extrêmement précieux dans le travail professionnel. Il ne s'agit pas seulement de résoudre une énigme. Il s'agit de savoir quelles preuves existent, ce qui manque, ce qui peut être inféré et ce qui ne doit pas être affirmé.
Apply this research method to your stock
Generate bull/bear views, risk notes, and an evidence trail for GPT.
Pour un utilisateur, la différence peut se ressentir ainsi : GPT-5.6 Sol Ultra est plus susceptible de se comporter comme un stratège énergique capable de coordonner un flux de travail complexe, tandis que Claude Opus 4.7 est plus susceptible de se comporter comme un analyste senior prudent qui protège contre les hypothèses fragiles. Les deux styles sont utiles. Le meilleur modèle dépend du coût de l'erreur.
Si vous élaborez une stratégie produit, construisez un flux de travail pour des agents IA, ou générez rapidement plusieurs options, GPT-5.6 Sol Ultra peut être le moteur créatif le plus puissant. Si vous passez en revue un contrat, analysez un long rapport financier, validez un pipeline de données, ou enquêtez sur un incident en production, la prudence de Claude Opus 4.7 peut être plus précieuse.
Les systèmes de raisonnement les plus profonds finiront par combiner les deux styles : une décomposition audacieuse et une vérification conservatrice. C’est pourquoi les flux de travail d’agents sont importants. Un bon système d’IA ne devrait pas dépendre d’une seule personnalité de modèle. Il devrait utiliser un modèle pour générer des hypothèses, un autre pour les contester, un autre pour vérifier les sources, et un autre pour transformer le résultat en décision actionnable. Cela est particulièrement important dans la recherche financière, où des conclusions confiantes mais non étayées peuvent coûter cher.
Contexte étendu et travail documentaire
Le contexte étendu est l’une des associations de marque les plus fortes de Claude. Les modèles Claude ont été largement utilisés pour la lecture de documents, contrats, bases de code, articles de recherche et rapports d’entreprise. Claude Opus 4.7 prolonge cette tendance en mettant l’accent sur la cohérence dans les contextes longs et le travail de connaissance professionnelle. L’annonce d’Anthropic inclut des retours de testeurs louant la discipline des données, la divulgation des données manquantes et une solide performance sur les contextes étendus.
Le contexte étendu ne se résume pas à la taille de la fenêtre. Une fenêtre contextuelle d’un million de tokens peut sembler impressionnante, mais ce qui compte, c’est de savoir si le modèle utilise correctement le contexte. Peut-il trouver le détail pertinent ? Peut-il éviter d’être distrait par du texte non pertinent ? Peut-il concilier des sources contradictoires ? Peut-il indiquer à l’utilisateur lorsque la réponse n’est pas présente ? Peut-il préserver les contraintes du début à la fin de la tâche ?
Claude Opus 4.7 semble particulièrement adapté aux tâches où l’entrée est longue, désordonnée et importante. Les exemples incluent la revue juridique, l’analyse des politiques, les mémos d’investissement, la documentation technique, les bases de connaissances du support client, les dossiers de diligence raisonnable, les manuels de conformité et les grands dépôts de code. Dans ces situations, le contrôle des hallucinations et la discipline contextuelle peuvent compter davantage que la vitesse.
GPT-5.6 Sol Ultra peut être plus convaincant lorsque le contexte étendu fait partie d’un flux de travail plus large. Par exemple, au lieu de se contenter de lire un long rapport, un système agentique pourrait résumer le rapport, extraire les métriques clés, les comparer aux données de marché, vérifier les actualités récentes, générer des hypothèses d’investissement, débattre des facteurs de risque et produire une thèse finale. Si l’orchestration des sous-agents du mode Ultra fonctionne bien, GPT-5.6 pourrait être puissant dans ce type de flux de travail multi-sources.
Donc la distinction n’est pas « Claude pour le contexte long, GPT pour tout le reste ». Elle est plus précise : Claude Opus 4.7 peut être plus fort pour la lecture attentive de contextes étendus et la synthèse ancrée, tandis que GPT-5.6 Sol Ultra peut être plus performant pour des flux de travail sur contexte étendu nécessitant orchestration, utilisation d’outils et exécution en plusieurs étapes.
Performance des agents IA : la vraie différence
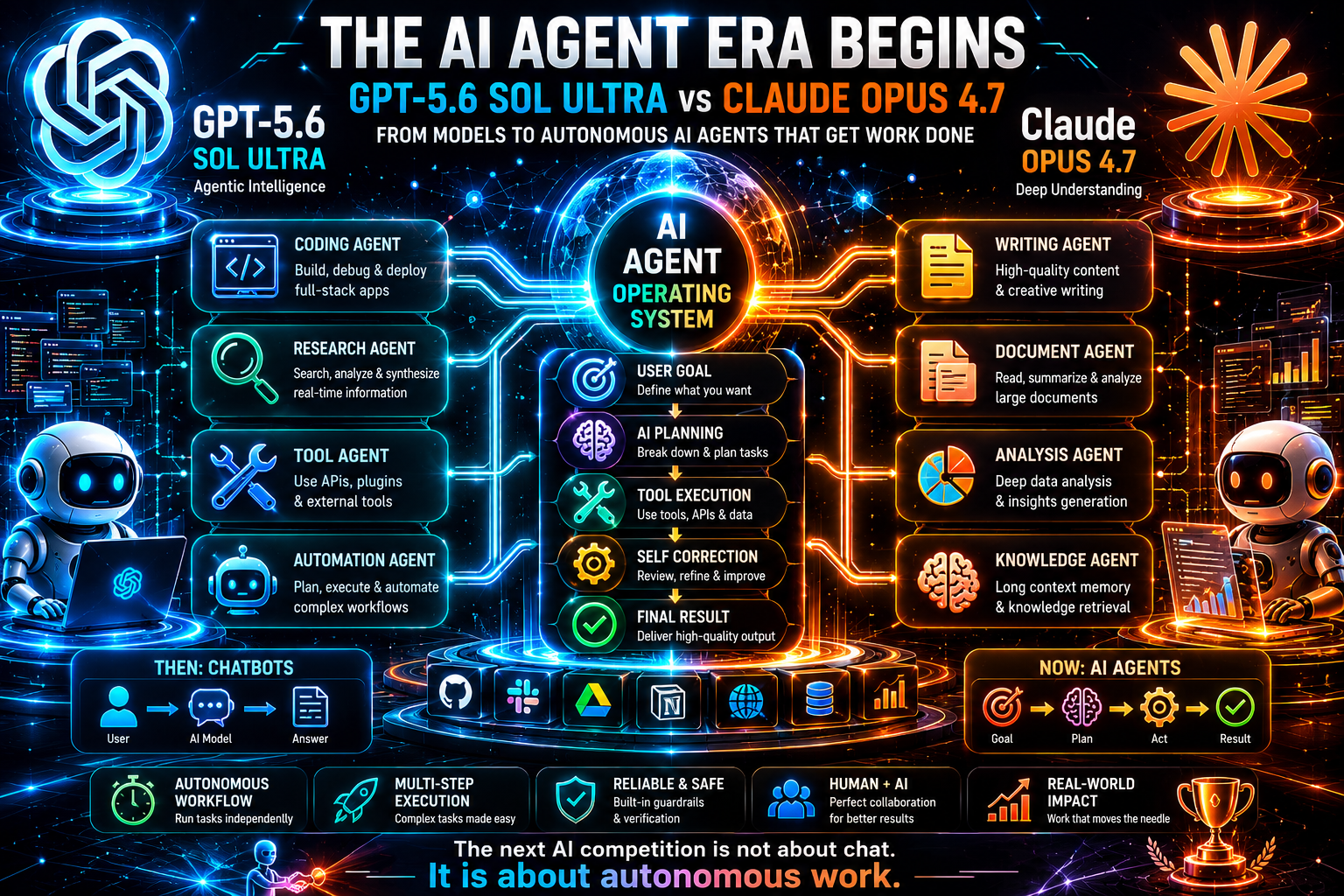
La catégorie la plus importante dans cette comparaison est la performance des agents IA. C'est là que le marché se dirige. Les chatbots sont utiles, mais ce sont les agents qui rendent les gains de productivité mesurables. Un agent IA peut prendre un objectif, planifier des étapes, appeler des outils, utiliser des API, inspecter les résultats, revoir son plan et poursuivre jusqu'à ce qu'une tâche soit terminée ou qu'une décision humaine soit nécessaire.
Le récit le plus fort de GPT-5.6 Sol Ultra est l'orchestration agentique. La description du mode Ultra évoque des sous-agents, l'un des schémas les plus importants dans la conception de systèmes IA avancés. Un appel à un modèle unique peut être puissant, mais les travaux complexes bénéficient de rôles spécialisés : chercheur, critique, codeur, testeur, analyste des risques, résumeur et agent décisionnel. Si GPT-5.6 Sol Ultra est optimisé pour cette structure, il pourrait devenir une base solide pour les produits IA de nouvelle génération.
Le récit le plus fort de Claude Opus 4.7 est la fiabilité agentique. Anthropic et GitHub mettent tous deux l'accent sur l'exécution de tâches en plusieurs étapes, le travail de longue durée, les flux de travail dépendants d'outils et la réduction des échecs. En production, la fiabilité vaut souvent plus que l'ambition brute. Un agent qui tente trop et se casse silencieusement est dangereux. Un agent qui avance prudemment, signale l'incertitude et se remet des pannes d'outils est plus facile à faire confiance.
Cela crée une distinction utile pour les concepteurs :
-
Utilisez GPT-5.6 Sol Ultra lorsque l'agent a besoin d'une orchestration large, de plusieurs étapes spécialisées et d'une intégration avec des flux de travail natifs d'OpenAI.
-
Utilisez Claude Opus 4.7 lorsque l'agent nécessite une gestion attentive du contexte, du codage ou de la recherche de longue durée, et une exécution fiable sous des contraintes complexes.
-
Utilisez les deux lorsque la tâche a une grande valeur : un modèle peut générer et planifier, tandis que l'autre critique, vérifie ou réécrit.
L'avenir des agents IA ne consistera pas en un modèle remplaçant tous les autres. Ce sera un routage intelligent. Une plateforme choisira le meilleur modèle pour chaque étape du flux de travail. Elle pourra utiliser un modèle moins coûteux pour la classification, un modèle rapide pour l'extraction, Claude pour l'analyse de longs documents, GPT pour l'orchestration, et un modèle de codage spécialisé pour les modifications de dépôt. Le produit gagnant ne sera pas simplement celui qui a le plus grand modèle. Ce sera celui qui a la meilleure conception de flux de travail.
Comparaison des prix : quel modèle offre le meilleur rapport qualité-prix ?

Le prix est l'endroit où la comparaison devient concrète. D'après les rapports publics, GPT-5.6 Sol est tarifé à 5 $ par million de tokens d'entrée et 30 $ par million de tokens de sortie. Anthropic indique que Claude Opus 4.7 est tarifé à 5 $ par million de tokens d'entrée et 25 $ par million de tokens de sortie. Cela rend Claude Opus 4.7 moins cher sur les tokens de sortie si ces chiffres constituent la base tarifaire de votre déploiement.
Modèle Prix entrée Prix sortie Conclusion tarifaire GPT-5.6 Sol 5 $ / 1M tokens 30 $ / 1M tokens Même prix d'entrée que Opus 4.7, prix de sortie plus élevé d'après les rapports publics actuels. Claude Opus 4.7 5 $ / 1M tokens 25 $ / 1M tokens Prix de sortie inférieur, adaptée aux flux de travail de codage et de documents de longue durée si l'utilisation des tokens est maîtrisée.
Cependant, le prix par token ne détermine pas à lui seul le coût réel. Le coût réel dépend de la longueur de la sortie, de la taille du contexte, de la mise en cache des prompts, du taux de réessai, des appels aux outils, de la latence et de la fréquence à laquelle le modèle donne la bonne réponse dès la première fois. Un modèle moins cher peut devenir coûteux s'il nécessite de nombreux réessais. Un modèle plus cher peut être moins onéreux s'il accomplit la tâche avec moins d'appels. Pour les agents de codage, le principal facteur de coût n'est souvent pas le prompt initial. C'est la boucle itérative : inspecter les fichiers, proposer des modifications, exécuter des tests, lire les erreurs, réviser et répéter.
Business Insider a rapporté qu'Anthropic a mis à jour ses estimations de dépense en tokens pour Claude Code, indiquant que le coût moyen pour un développeur en entreprise était d'environ 13 $ par jour actif et de 150 à 250 $ par développeur et par mois, avec 90 % des utilisateurs à moins de 30 $ par jour actif. L'important n'est pas que Claude soit particulièrement cher. L'essentiel est que l'utilisation d'agents IA modifie la structure des coûts. Lorsque les modèles deviennent des travailleurs plutôt que de simples moteurs de réponses, ils consomment davantage de tokens parce qu'ils effectuent plus de travail.
Pour les équipes de production, la question tarifaire devrait être formulée en coût par flux de travail complété. Par exemple :
-
Quel est le coût pour résoudre un ticket de support ?
-
Quel est le coût pour corriger un bug ?
-
Quel est le coût pour générer un brief d'investissement ?
-
Quel est le coût pour analyser une conférence sur les résultats ?
-
Quel est le coût pour surveiller une action pendant une semaine ?
Une fois que vous mesurez le coût de cette manière, le meilleur modèle peut varier selon la tâche. Claude Opus 4.7 peut être plus rentable pour des sorties longues et soignées car son prix par token de sortie est plus bas et son style peut réduire les retouches. GPT-5.6 Sol Ultra peut être plus économique pour des flux de travail où l'orchestration réduit le temps de coordination humaine. La seule façon fiable de le savoir est de réaliser des évaluations au niveau des tâches avec de vrais prompts, de vrais fichiers et de vrais critères de réussite.
Expérience développeur : Claude Code, GitHub Copilot, API et frameworks d'agents
La qualité du modèle compte, mais l'expérience développeur détermine l'adoption. Un modèle légèrement meilleur mais plus difficile à intégrer peut perdre face à un modèle qui s'intègre naturellement aux flux de travail existants. C'est pourquoi Claude Code, GitHub Copilot, ChatGPT, les outils API et les frameworks d'agents sont si importants.
Claude Opus 4.7 bénéficie d'une intégration dans les environnements de développement où les utilisateurs travaillent déjà. L'annonce de GitHub selon laquelle Opus 4.7 est déployé dans Copilot lui offre une distribution au sein de l'un des produits de codage les plus importants au monde. Claude Code donne également à Anthropic une interface directe pour l'ingénierie logicielle basée sur des agents. Pour les développeurs qui souhaitent un partenaire de codage puissant plutôt qu'une API brute, cela a de l'importance.
GPT-5.6 Sol Ultra profite de l'écosystème plus large d'OpenAI. ChatGPT reste une interface IA grand public, l'API d'OpenAI bénéficie d'une forte adoption chez les développeurs, et l'orientation produit de l'entreprise supporte de plus en plus les outils, les flux de travail multimodaux et les applications basées sur des agents. Si votre équipe se construit déjà sur les APIs d'OpenAI, GPT-5.6 Sol Ultra peut être plus facile à adopter comme voie de mise à niveau.
La question de l'expérience développeur devrait inclure :
-
Le modèle fonctionne-t-il au sein des outils que votre équipe utilise déjà ?
-
Peut-il appeler vos outils internes en toute sécurité ?
-
Pouvez-vous surveiller l'utilisation des tokens et le succès des workflows ?
-
Pouvez-vous acheminer les tâches entre les modèles ?
-
Pouvez-vous ajouter des garde-fous pour la sécurité, la confidentialité et la conformité ?
-
Le modèle peut-il expliquer ce qu'il a fait et pourquoi ?
Pour les plates-formes d'IA internes, la meilleure réponse peut être un routeur de modèles plutôt qu'un engagement envers un seul modèle. Utilisez Claude Opus 4.7 pour les tâches qui nécessitent une lecture attentive et un raisonnement sur des bases de code avec un long contexte. Utilisez GPT-5.6 Sol Ultra pour l'orchestration axée sur la planification, l'utilisation d'outils et la coordination de multiples agents. Utilisez des modèles moins coûteux pour l'extraction, la classification et les tâches répétitives. Cette architecture est plus résiliente que de tout miser sur un seul modèle de pointe.
Recherche et analyse : quel modèle gère mieux les informations complexes ?
La recherche est l'endroit où les modèles d'IA peuvent créer un effet de levier énorme. Un analyste humain peut passer des heures à lire des rapports, des dépôts, des transcriptions, des actualités, des discussions de forums, des données de marché et des documents internes. Un bon modèle d'IA peut compresser ce processus. Mais un mauvais système de recherche IA peut produire des absurdités confiantes.
Claude Opus 4.7 présente un bon argument pour les tâches de recherche en raison de sa discipline sur les longs contextes et de sa gestion prudente des données manquantes. L'annonce d'Anthropic inclut des retours de testeurs décrivant une meilleure divulgation et une discipline des données renforcée. Cela compte en recherche parce que les erreurs les plus dangereuses ne sont souvent pas des hallucinations manifestes. Ce sont des inférences subtiles et non étayées qui semblent raisonnables.
GPT-5.6 Sol Ultra a de solides arguments pour les workflows de recherche en raison de son orientation agentive. La recherche n'est pas seulement de la lecture. Il s'agit de poser les bonnes questions, de rassembler des sources, de comparer des perspectives, d'identifier des contradictions, de faire évoluer une thèse et de décider quoi surveiller ensuite. Si le mode Ultra améliore l'orchestration des sous-agents, GPT-5.6 pourrait être particulièrement utile pour les systèmes de recherche qui divisent le travail entre plusieurs agents.
Par exemple, un flux de travail de recherche financière pourrait inclure :
-
Un agent d'actualités qui rassemble les développements récents de l'entreprise.
-
Un agent de dépôts qui extrait les revenus, marges, dettes et changements de guidance.
-
Un agent de marché qui vérifie l'action du prix, le volume, la volatilité et la dynamique sectorielle.
-
Un agent de risque qui remet en question la thèse haussière.
-
Un agent de valorisation qui compare les multiples et les hypothèses.
-
Un agent de synthèse final qui produit un brief prêt à la décision.
C'est là que GPT-5.6 Sol Ultra et Claude Opus 4.7 peuvent tous deux être précieux. GPT peut coordonner le flux de travail. Claude peut critiquer les preuves. Un autre modèle peut extraire des chiffres structurés à moindre coût. Le produit final n'est pas une réponse de chatbot. C'est un processus de recherche propre à l'IA.
Pourquoi la recherche d'investissement propre à l'IA devient possible
La recherche d'investissement est un exemple parfait de pourquoi la course aux modèles d'IA devient une course aux workflows. Les investisseurs n'ont pas simplement besoin de réponses. Ils ont besoin d'une pensée structurée en situation d'incertitude. Ils doivent savoir ce qui a changé, pourquoi cela importe, quelles preuves soutiennent la thèse, ce qui pourrait être faux et quel signal doit être surveillé ensuite.
Les outils traditionnels de recherche financière sont souvent statiques. Ils affichent des graphiques, des ratios, des titres, des notes d'analystes et des documents déposés. Ils sont utiles, mais ils obligent l'utilisateur à faire lui-même les liens. L'utilisateur doit encore décider quelles informations sont pertinentes, quels risques sont sous-estimés dans les prix, quelle narration évolue et quel élément de donnée contredit le consensus.
Les agents d'IA peuvent changer cela. Un agent de recherche peut lire des transcriptions de résultats. Un agent de risque peut remettre en question les hypothèses. Un agent d'évaluation peut comparer des scénarios. Un agent d'actualité peut suivre les catalyseurs. Un agent de surveillance peut guetter les événements qui brisent une thèse. Un agent de débat peut simuler des arguments haussiers et baissiers. Il ne s'agit pas de remplacer le jugement humain. Il s'agit de donner aux investisseurs humains un meilleur système d'exploitation pour la recherche.
C'est là que des plateformes comme AlphaVue.ai s'inscrivent dans le mouvement plus large de l'IA. La prochaine génération de plateformes d'investissement ne se contentera pas d'afficher des données. Elles aideront les utilisateurs à raisonner à partir des données. Elles transformeront l'information de marché en flux de travail : scanner, rechercher, débattre, comparer, surveiller et décider. GPT-5.6 Sol Ultra et Claude Opus 4.7 sont importants non pas parce que l'un vaincra définitivement l'autre, mais parce qu'ils montrent tous deux à quel point le marché est proche d'une intelligence d'investissement native à l'IA.
Pour les investisseurs, la question clé n'est plus « l'IA peut-elle résumer cette action ? » C'est le minimum syndical. La vraie question est : l'IA peut-elle m'aider à comprendre ce qui compte, ce qui a changé, ce qui est déjà intégré dans les prix, ce qui est incertain et que faire ensuite ? Cela exige des flux de travail agentiques, un routage des modèles, une discipline des sources et un raisonnement transparent. Cela nécessite aussi une conception produit. Un modèle puissant sans bon flux de travail revient à un terminal Bloomberg sans recherche, sans alertes et sans structure.
Perspective d'AlphaVue.ai : des modèles d'IA aux agents d'investissement IA
L'avenir de la recherche financière ne sera pas un chatbot géant. Ce sera un réseau d'agents d'IA spécialisés qui recherchent des entreprises, comparent les signaux de marché, testent des scénarios haussiers et baissiers, et aident les investisseurs à surveiller ce qui compte. AlphaVue.ai est conçu pour ce flux de travail d'investissement natif à l'IA : une recherche plus intelligente, des décisions plus claires et des insights plus rapides.
Cas d'utilisation réels : quel modèle choisir ?
Il n'existe pas de gagnant universel entre GPT-5.6 Sol Ultra et Claude Opus 4.7. Le modèle adapté dépend de la tâche. Voici un cadre décisionnel pratique.
Choisissez GPT-5.6 Sol Ultra lorsque :
-
Vous construisez des agents d'IA qui nécessitent de la planification, l'utilisation d'outils et de l'orchestration.
-
Vous utilisez déjà les API d'OpenAI et souhaitez une voie d'évolution vers la pointe.
-
Votre flux de travail combine texte, code, données structurées et éventuellement des entrées multimodales.
-
Vous voulez que le modèle coordonne des sous-tâches spécialisées.
-
Vous accordez de l'importance à l'intégration dans l'écosystème et à la vitesse de développement produit.
Choisissez Claude Opus 4.7 lorsque :
-
Vous avez besoin d'une lecture attentive de longs contextes et d'une analyse documentaire.
-
Vous travaillez intensivement avec des bases de code, du refactoring et des tâches d'ingénierie complexes.
-
Vous privilégiez un raisonnement prudent et la divulgation des données manquantes.
-
Vous utilisez les intégrations Claude Code ou GitHub Copilot qui prennent en charge Opus 4.7.
-
Vous souhaitez des tarifs par token de sortie légèrement inférieurs selon les tarifs indiqués.
Utilisez les deux lorsque :
-
La tâche a suffisamment de valeur pour justifier une vérification croisée entre modèles.
-
Vous avez besoin qu'un modèle génère et qu'un autre critique.
-
Vous construisez une plateforme d'IA en production avec routage des modèles.
-
Vous voulez réduire les modes de défaillance liés à un modèle unique.
-
Vous accordez de l'importance à la fois à la créativité et à la prudence.
Les équipes les plus sophistiquées ne demanderont pas « quel modèle est le meilleur ? ». Elles demanderont « quel modèle doit prendre en charge quelle étape ? ». C'est la bonne question pour 2026. L'IA est devenue trop importante pour traiter la sélection du modèle comme une préférence de marque.
Verdict final : GPT-5.6 Sol Ultra ou Claude Opus 4.7 ?

Si vous voulez la réponse la plus simple, la voici : Claude Opus 4.7 est aujourd'hui le choix le plus sûr pour le codage minutieux, la recherche sur de longs contextes et les flux de travail professionnels disciplinés, tandis que GPT-5.6 Sol Ultra est le choix stratégiquement le plus enthousiasmant pour l'orchestration par agents et les systèmes d'IA natifs d'OpenAI.
Claude Opus 4.7 bénéficie actuellement d'une base publique plus solide. Anthropic a publié les tarifs officiels et les informations de disponibilité. GitHub a évoqué son déploiement dans Copilot. Les retours des premiers testeurs mettent en avant précisément les capacités qui comptent pour le travail réel : exécution en plusieurs étapes, moins d'erreurs d'outils, planification renforcée et meilleures performances sur de longs contextes. Si votre équipe a besoin aujourd'hui d'un modèle pour les flux de travail de codage et de recherche, Claude Opus 4.7 mérite une évaluation sérieuse.
GPT-5.6 Sol Ultra est plus difficile à juger avec certitude car la couverture des benchmarks indépendants reste limitée. Mais sa direction est importante. La combinaison d'un raisonnement de premier plan, du mode Max, du mode Ultra et de l'orchestration par sous-agents indique la voie que prend l'IA : du simple fait de répondre à des questions vers la coordination du travail. Si OpenAI exécute bien, GPT-5.6 Sol Ultra pourrait devenir l'un des modèles les plus importants pour les produits orientés agents.
Le véritable gagnant ne sera peut‑être aucun des deux modèles pris isolément. Le véritable gagnant est la couche de flux de travail qui utilise le bon modèle au bon moment. En développement, cela signifie des agents capables de lire, corriger, tester et expliquer. En recherche, cela signifie des systèmes capables de collecter, vérifier, débattre et surveiller. En investissement, cela signifie des plateformes qui transforment les données de marché en intelligence structurée.
GPT-5.6 Sol Ultra vs Claude Opus 4.7 n'est donc pas seulement une comparaison de modèles. C'est un aperçu de la prochaine guerre des plateformes d'IA. L'avenir appartiendra aux systèmes qui combinent raisonnement, outils, mémoire, vérification et conception des flux de travail. Le chatbot le plus intelligent ne gagnera pas. Le travailleur IA le plus utile l'emportera.
FAQ : GPT-5.6 Sol Ultra vs Claude Opus 4.7
GPT-5.6 Sol Ultra est-il meilleur que Claude Opus 4.7 ?
Pas universellement. GPT-5.6 Sol Ultra semble davantage axé sur l'orchestration d'agents et les workflows natifs d'OpenAI, tandis que Claude Opus 4.7 dispose de preuves publiques plus solides en matière de codage soigneux, de travail sur de longs contextes et d'exécution fiable en plusieurs étapes. Le meilleur modèle dépend de votre cas d'usage.
Quel modèle est meilleur pour la programmation ?
Claude Opus 4.7 bénéficie actuellement d'une crédibilité publique supérieure en matière de programmation, car Anthropic et GitHub ont tous deux mis en avant ses performances en codage et dans les workflows de développeurs basés sur des agents. GPT-5.6 Sol Ultra pourrait devenir très compétitif pour les systèmes de codage agentiques, surtout si son mode Ultra améliore l'orchestration des sous-agents.
Quel modèle est moins cher ?
D'après les tarifs publics, les deux modèles sont à 5 $ par million de tokens d'entrée. Claude Opus 4.7 est facturé 25 $ par million de tokens de sortie, tandis que les rapports publics indiquent GPT-5.6 Sol à 30 $ par million de tokens de sortie. Le coût réel dépend des réessais, de la longueur des sorties, de l'utilisation d'outils, de la mise en cache et du taux de réussite des workflows.
Quel modèle est meilleur pour les agents d'IA ?
GPT-5.6 Sol Ultra peut être plus intéressant pour l'orchestration d'agents car le mode Ultra est décrit autour des sous-agents. Claude Opus 4.7 peut être mieux adapté à l'exécution fiable d'agents longue durée, en particulier pour les workflows axés sur le codage et les documents volumineux. Pour les cas d'usage à forte valeur, l'utilisation conjointe des deux via un routeur de modèles peut être la meilleure option.
Quel modèle les startups devraient-elles choisir ?
Les startups doivent choisir en fonction de l'économie de leurs workflows. Si le produit dépend de l'intégration à l'écosystème OpenAI et de l'orchestration multi-agents, testez GPT-5.6 Sol Ultra. Si le produit repose sur le raisonnement sur de longs contextes, la fiabilité du codage et des analyses approfondies, testez Claude Opus 4.7. En production, orientez les tâches selon les points forts de chaque modèle plutôt que d'utiliser un seul modèle pour tout.
Quel modèle est meilleur pour la recherche d'investissement ?
Claude Opus 4.7 peut être plus performant pour la lecture de longs rapports et la production d'analyses prudentes. GPT-5.6 Sol Ultra peut être plus adapté aux workflows de recherche multi-agents qui collectent les actualités, comparent des données financières, débattent des risques et suivent l'évolution des thèses. Les meilleurs systèmes de recherche d'investissement combineront probablement plusieurs modèles et agents spécialisés.